折腾:
【已解决】Python的BeautifulSoup去实现提取带tag的HTML网页主体内容
期间,去写代码:
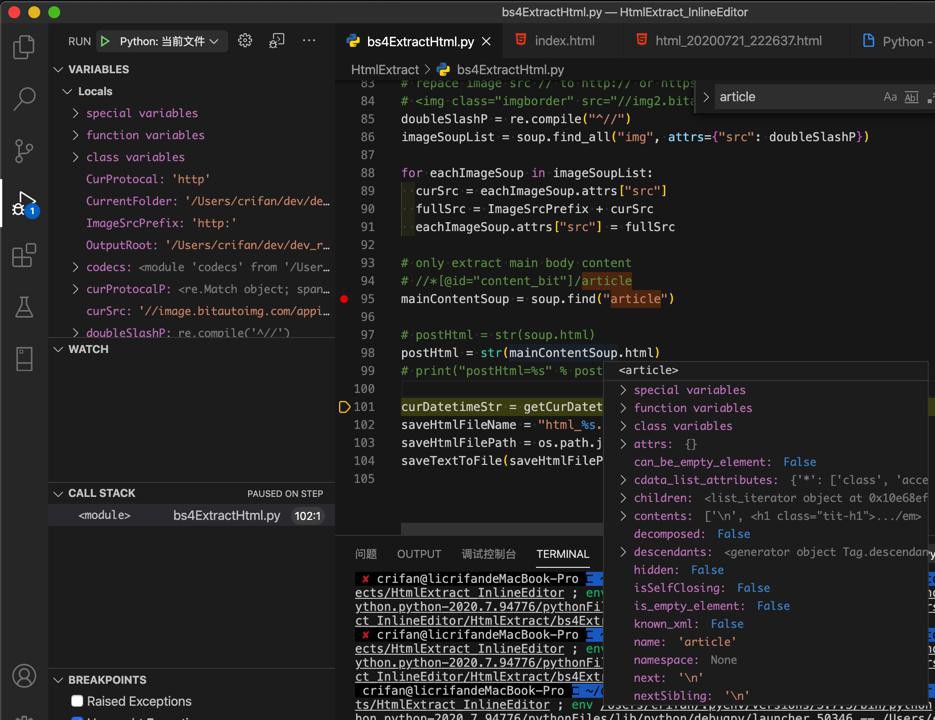
# only extract main body content
# //*[@id="content_bit"]/article
mainContentSoup = soup.find("article")
# postHtml = str(soup.html)
postHtml = str(mainContentSoup.html)
# print("postHtml=%s" % postHtml)虽然可以找到article节点:
但是:其html属性却是空的:
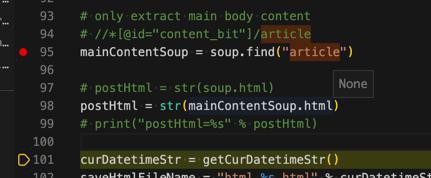
所以要去想办法找找如何获取find得到的某个soup节点及其子节点的html
beautifulsoup get soup node html
好像直接用str即可?
去试试
postHtml = str(mainContentSoup)
结果:
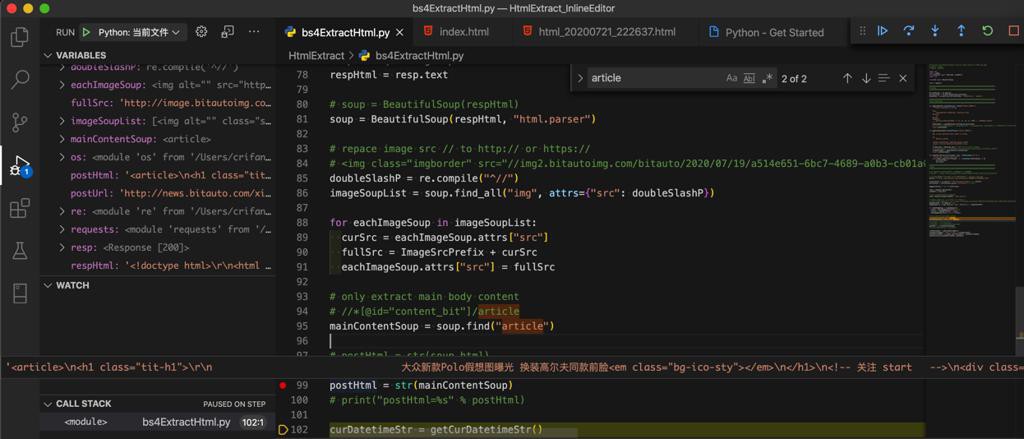
好像真的可以了。。。
【总结】
BeautifulSoup中find出来的soup,直接用
str(soup)
即可获取到html源码。
转载请注明:在路上 » 【已解决】BeautifulSoup中find得到的soup节点如何获取自身及其下子孙节点的html源码