【整理】网页抓取,模拟登陆,抓取动态网页内容等过程中,所涉及的Headers信息,Cookie信息,POST数据的处理逻辑
crifan 14年前 (2012-12-04) 5529浏览 2评论
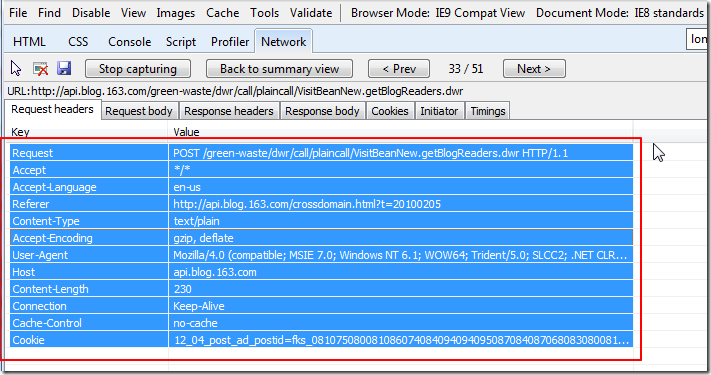
背景 我们在,网页抓取,模拟登陆,抓取动态网页等等,过程中,往往要先通过工具去分析,如何访问一个url,然后获得对应的数据,然后搞懂逻辑了,再用代码实现出来。 而此时,就涉及到,访问对应的url是GET是,要发送,一堆的Header, 而如果是POS...
crifan 14年前 (2012-12-04) 5529浏览 2评论
背景 我们在,网页抓取,模拟登陆,抓取动态网页等等,过程中,往往要先通过工具去分析,如何访问一个url,然后获得对应的数据,然后搞懂逻辑了,再用代码实现出来。 而此时,就涉及到,访问对应的url是GET是,要发送,一堆的Header, 而如果是POS...

crifan 14年前 (2012-12-04) 9121浏览 4评论
背景 很多时候,很多人,需要去抓取网页中某些特定内容。 但是,除了之前介绍过的,想要提取某些,静态网页,中的特定内容,比如: 【教程】抓取网并提取网页中所需要的信息 之 Python版 和 【教程】抓取网并提取网页中所需要的信息 之 C#版 之外,有...
crifan 14年前 (2012-11-20) 5068浏览 2评论
最近更新:v2012-11-20 之前,由于折腾一些东西,BlogsToWordpress,InsertSkydriveFiles,而接触到了,这些,用于调试网页,调试页面执行流程和逻辑的工具: IE9的F12,Chrome的Ctrl+Shi...
crifan 14年前 (2012-11-20) 21215浏览 10评论
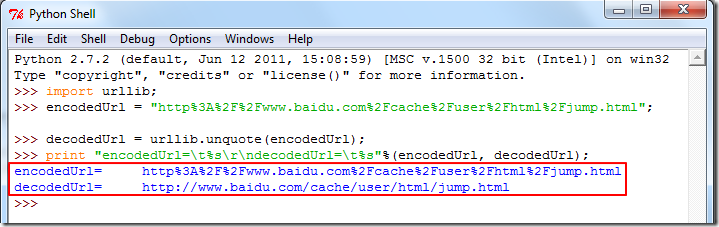
背景 比如: 【教程】手把手教你如何利用工具(IE9的F12)去分析模拟登陆网站(百度首页)的内部逻辑过程 中所涉及的staticpage变量的值是: http%3A%2F%2Fwww.baidu.com%2Fcache%2Fuser%2Fht...
crifan 14年前 (2012-11-12) 12623浏览 3评论
【问题】 通过Scrapy创建好了项目: E:\Dev_Root\python\Scrapy>scrapy startproject songtaste 运行项目,结果出错: E:\Dev_Root\python\Scrapy>scrap...
crifan 14年前 (2012-11-12) 5667浏览 0评论
【问题】 想要模拟优酷视频播放,刷新视频播放次数。 以此为例: 视频:燕山大讲堂 中国如何走向公民社会 4-3 http://v.youku.com/v_show/id_XMjIxMjUzNjQ0.html 想要通过C#程序模拟刷新其播放次数。 【解...
crifan 14年前 (2012-11-11) 5428浏览 2评论
安装了Scrapy之后,就去按照官网教程: Scrapy Tutorial 去试试。 1.通过 scrapy startproject tutorial 创建了一个新项目。 2.参考其代码,把items.py改为其所说的值。 3.新建了dm...
crifan 14年前 (2012-11-11) 5032浏览 5评论
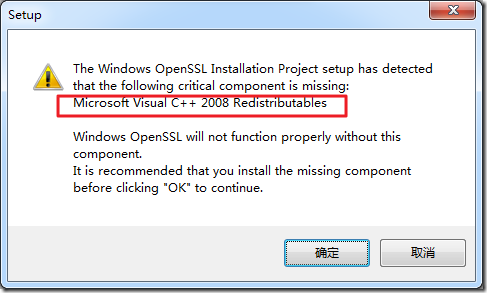
1.参考: http://scrapy.org/download/ 去cmd中通过pip安装,结果出错: E:\Dev_Tools\python\Scrapy>pip install Scrapy Downloading/unpacking S...
crifan 14年前 (2012-11-11) 5026浏览 5评论
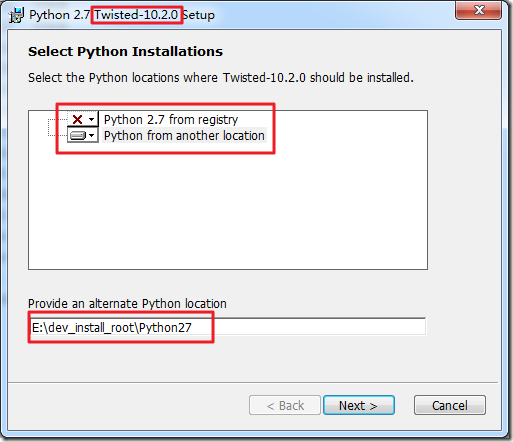
【问题】 在安装Scrapy过程中,出错: E:\Dev_Tools\python\Scrapy>pip install Scrapy ... creating Twisted.egg-info writing requirements to...
crifan 14年前 (2012-11-11) 5706浏览 1评论
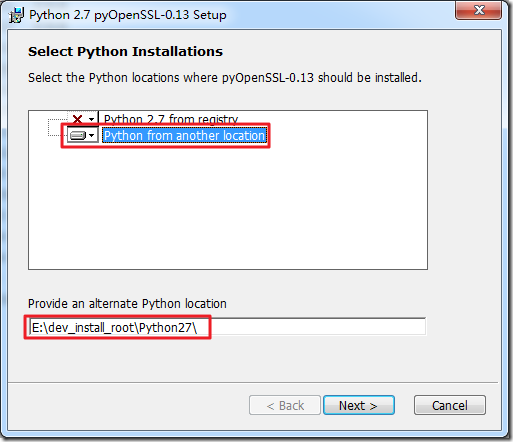
【问题】 安装scrapy过程中出错: E:\Dev_Tools\python\Scrapy>pip install Scrapy ... Downloading/unpacking pyOpenSSL (from Scrapy) Down...