折腾:
【记录】爬虫 爬数据 义务教育教科书 义教教科书 电子书
期间,去打开:
后,需要输入账号和密码:
登录后,去打开:
然后去看看如何抓取。
需要爬取:
进入:
先去:
【已解决】分析tch.ityxb.com页面内部获取电子书图片的逻辑
然后再去写代码
写了代码:
# Function:
# 下载在线电子书:(需要登录)
# java 入门,第二版
# http://tch.ityxb.com/textbook/detail/8a9aec126449fa350164590f5e4d0063
# 的图片
# Author: Crifan Li
# Update: 20200426
import os
import requests
gBookTitle = "Java基础入门第2版"
gDomain = "tch.ityxb.com"
gTotalPageCount=427
UserAgent_Mac_Chrome = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36"
gHeaders = {
"User-Agent": UserAgent_Mac_Chrome,
}
# gSaveFolder = os.path.join("output", gBookTitle)
gSaveFolder = os.path.join("output", gDomain, gBookTitle)
def createFolder(folderFullPath):
"""
create folder, even if already existed
Note: for Python 3.2+
"""
os.makedirs(folderFullPath, exist_ok=True)
createFolder(gSaveFolder)
Host = "https://vip.ow365.cn"
GetPageUrl = "%s/PW/GetPage" % Host
GetImgUrl = "%s/img" % Host
curPageToken = ""
def downloadImgage(imgUrl, saveFullPath):
resp = requests.get(imgUrl)
if resp.ok:
with open(saveFullPath, 'wb') as saveFp:
saveFp.write(resp.content)
print("Saved imgUrl=%s to saveFullPath=%s" % (imgUrl, saveFullPath))
else:
print("Fail to download image from %s" % imgUrl)
for curPageIdx in range(gTotalPageCount):
curPageNum = curPageIdx + 1
print("[%d] " % (curPageNum))
queryDict = {
'f': "YXR0YWNobWVudC1jZW50ZXIuYm94dWVndS5jb20uODBcMThmNWJiOTZhM2I4NGM3NzllZDJhNTY4MzM3ZWFkNjAucGRm",
"img": curPageToken,
"isMobile": "false",
"vid": "@ouvAGlwulktavhIGppyKg==",
"dk": "0",
"ver": "2",
"sn": "0",
}
resp = requests.get(GetPageUrl, headers=gHeaders, params=queryDict)
if resp.ok:
respText = resp.text
# print("respText=%s" % respText)
respJson = resp.json()
# print("respJson=%s" % respJson)
"""
{
"NextPage": "IDcMbrrMGOWvOQVTWydwR6WWz0UVpg2zB9VFJh7jsnp5byBCqeJ6jribHO0GQGIZ1exJW4aembE=",
"PageCount": 427,
"ErrorMsg": "",
"PageIndex": 1,
"PageWidth": 880,
"Width": 880,
"Height": 1237
}
"""
curImgToken = respJson["NextPage"]
curPageIndex = respJson["PageIndex"]
saveFilename = "%d.png" % curPageNum
saveFullPath = os.path.join(gSaveFolder, saveFilename)
curImgUrl = "%s?img=%s&tp=" % (GetImgUrl, curImgToken)
# https://vip.ow365.cn/img?img=IDcMbrrMGOWvOQVTWydwR6WWz0UVpg2zB9VFJh7jsnp5byBCqeJ6jmsfp2y28J9E9JreoGwZvNk=&tp=
# https://vip.ow365.cn/img?img=IDcMbrrMGOWvOQVTWydwR6WWz0UVpg2zB9VFJh7jsnp5byBCqeJ6jribHO0GQGIZ1exJW4aembE=&tp=
downloadImgage(curImgUrl, saveFullPath)
else:
print("!!! fail to open url: %s, reason: %s, status_code" % (GetPageUrl, resp.reason, resp.status_code))
print("resp.text=%s" % resp.text)其中调试第一张图片
结果
https://vip.ow365.cn/img?img=IDcMbrrMGOWvOQVTWydwR6WWz0UVpg2zB9VFJh7jsnp5byBCqeJ6jribHO0GQGIZ1exJW4aembE=&tp=
却保存图片是错误的
去找找缺哪些参数
去看了之前的
curl 'https://vip.ow365.cn/img?img=IDcMbrrMGOWvOQVTWydwR6WWz0UVpg2zB9VFJh7jsnp5byBCqeJ6jribHO0GQGIZ1exJW4aembE=&tp=' \ -H 'authority: vip.ow365.cn' \ -H 'pragma: no-cache' \ -H 'cache-control: no-cache' \ -H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36' \ -H 'accept: image/webp,image/apng,image/*,*/*;q=0.8' \ -H 'sec-fetch-site: same-origin' \ -H 'sec-fetch-mode: no-cors' \ -H 'sec-fetch-dest: image' \ -H 'referer: https://vip.ow365.cn/?i=11311&ssl=1&furl=0As6WW@zSHIfqZy_0miBI1NfVmqplNkx4osgxUapgos7zntvq_BluwUV5DjSGRhsHRFJwyGpvHi9cjUTIGzm3WHgnjJ2lFd1wVPaQXBaorIzE0K0J_OXwbwK6qlOrtb@@GhMGaxrje5AeipdhF4tvw==' \ -H 'accept-language: zh-CN,zh;q=0.9,en;q=0.8,la;q=0.7' \ --compressed
试了试:
authority: vip.ow365.cn
无效,猜测是referer
果然是:
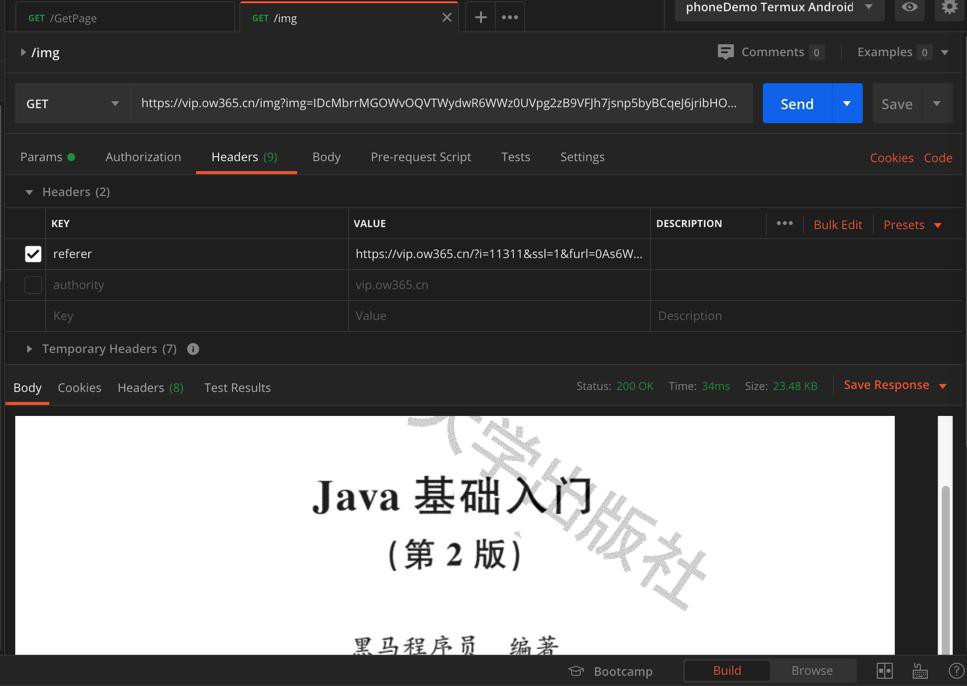
所以去加上referer即可。
但是发现此处值不是当前getpage的url
不过发现是:
中的url
所以:此处可以写死:
https://vip.ow365.cn/?i=11311&ssl=1&furl=0As6WW@zSHIfqZy_0miBI1NfVmqplNkx4osgxUapgos7zntvq_BluwUV5DjSGRhsHRFJwyGpvHi9cjUTIGzm3WHgnjJ2lFd1wVPaQXBaorIzE0K0J_OXwbwK6qlOrtb@@GhMGaxrje5AeipdhF4tvw==
试试。
尤其是其中的i值11311之类的(和furl=from url?),就是:此处对应的当前这个电子书的网页打开时的url
RefererI = "11311"
RefererSsl = "1"
RefererFurl = "0As6WW@zSHIfqZy_0miBI1NfVmqplNkx4osgxUapgos7zntvq_BluwUV5DjSGRhsHRFJwyGpvHi9cjUTIGzm3WHgnjJ2lFd1wVPaQXBaorIzE0K0J_OXwbwK6qlOrtb@@GhMGaxrje5AeipdhF4tvw=="
ImgReferer = "https://vip.ow365.cn/?i=%s&ssl=%s&furl=%s" % (RefererI, RefererSsl, RefererFurl)
ImgHeaderDict = {
"referer": ImgReferer
}
curPageToken = ""
def downloadImgage(imgUrl, saveFullPath):
resp = requests.get(imgUrl, headers=ImgHeaderDict)结果:
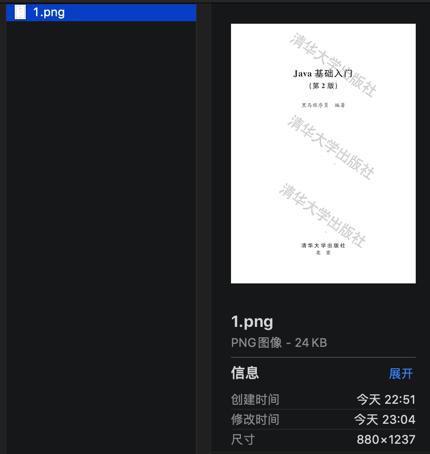
即可获取到图片了。
转载请注明:在路上 » 【未解决】爬取tch.ityxb.com中电子书《java 入门》