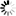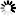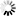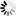对于ISO/IEC 8859所包含的全部字符,我们可以看到,对于基本的拉丁字母,那都是和ASCII一样的,因为其就是借用了ASCII中的0x20-0x7F这段的编码,对应的是那些常见的可显示的字符,而对于0xA0-0xFF这段空间,则是对于同一个值,不同的字符集中,对应着不同的符号。
对于ISO/IEC 8859的编码方式是设计了多个字符集,我们不难看出,其之所以这么编码,而不是像ASCII中每个编码值,都对应唯一的一个字符,那是因为,欧洲的全部所用的字符数很多,如果是对于全部的欧洲用的字符都用一个对应的值来表示,那么这剩下的0xA0-0xFF,甚至是0x80-0xFF,也都不够用的,因为0x80-0xFF128个值,当然不够表示欧洲那几百上千的不同国家的不同字符。
所以,才会去设计出这么15个字符集,然后对于同一个值,你用了ISO/IEC 8859-n,就表示对应的字符集中的那个特定的字符。
而上述做法的好处是,可以避免去用多个字节,比如两个字节(8×2=16位,可以表示最多2^16=65536个字符)去表示一个单独的字符,即节省了存放数据的空间。
但是缺点是,比如你写一篇文章,中间出现了多个不同语系的不同的字符,那么此文章如果用ISO/IEC 8859来编码的话,那么就无法单独存成某一种对应的字符集,即包含多个欧洲国家不同语系的特殊字符的数据,无法用ISO/IEC 8859的某一个单独的字符集来表示出来,即无法在同一个文章中支持显示不同语系的不同的字符。
当然,相对于亚洲字符,即中文,日文,韩文等字符来说,另外一个如果算的上是缺点的话,那就是没有把咱亚洲字符考虑进去。
正因此,字符编码,才会继续演化出更加通用的,包含了世界上所有的字符的字符编码标准:Unicode。
关于Unicode的详细解释请去看:第 2.4 节 “支持世界上几乎所有字符的字符编码:Unicode”
此处先来说说,其他几个和ISO/IEC 8859相关的内容。
 |  |  |
| 2.2.2.2. ISO/IEC 8859的编码规则 |  | 2.2.2.4. ISO/IEC 6429 |