【未解决】js中将html内容保存到服务器上的本地的html文件
crifan 11年前 (2015-07-21) 6225浏览 0评论
【背景】 之前已经实现了: 网页中,点击某个按钮,可以调用到js获得到KindEditor的html的内容: <script> function submitGoodsContent() { var ...
crifan 11年前 (2015-07-21) 6225浏览 0评论
【背景】 之前已经实现了: 网页中,点击某个按钮,可以调用到js获得到KindEditor的html的内容: <script> function submitGoodsContent() { var ...

crifan 11年前 (2015-07-19) 4898浏览 0评论
【背景】 之前已经实现了,整合KindEditor进来,可以正常使用了。 现在需要在富文本编辑器KindEditor中,加载已有的html网页的内容。 【折腾过程】 1.自己瞎写的,但是估计不能工作: <script> ...
crifan 11年前 (2015-07-19) 9196浏览 0评论
【背景】 在折腾: 【基本解决】KindEditor中加载已有html页面内容 期间,需要先去搞懂,如何通过js中加载已有html页面内容。 【折腾过程】 1.搜: js load html 参考: javascript –...
crifan 11年前 (2015-07-19) 12320浏览 0评论
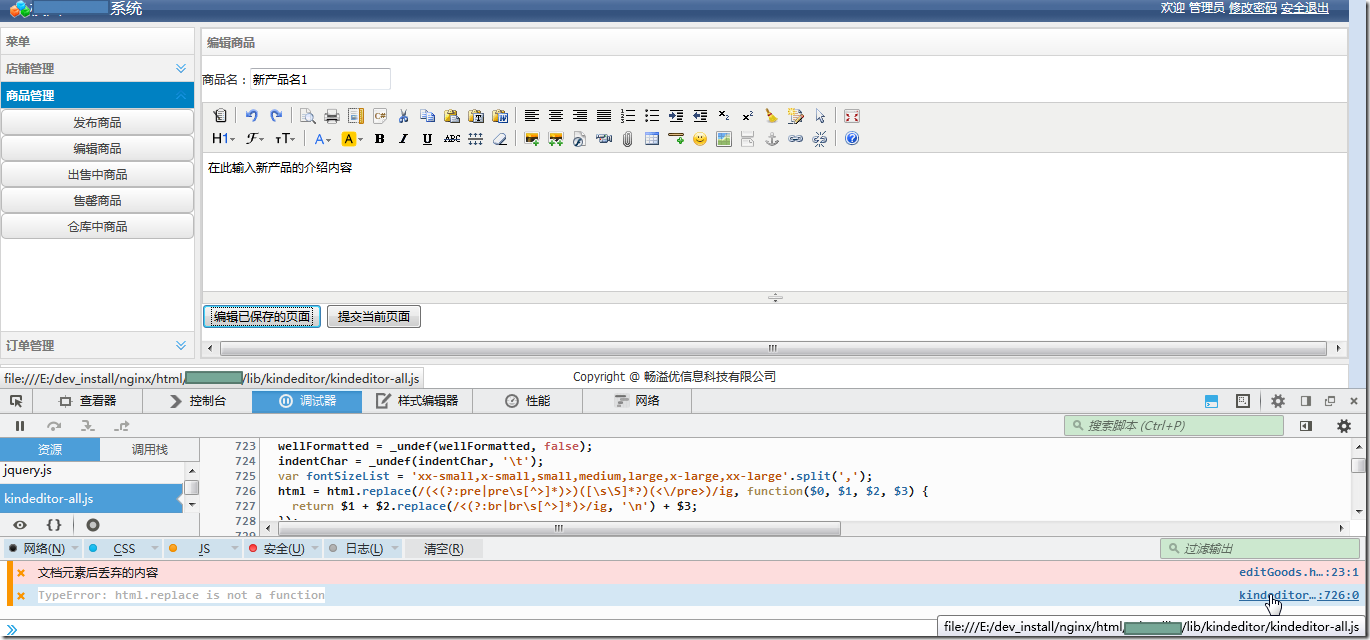
【问题】 折腾: 【基本解决】js中如何加载html内容 期间,用代码: <script> function editSavedGoodsContent() { var kindeditor = wi...
crifan 12年前 (2014-01-27) 4074浏览 0评论
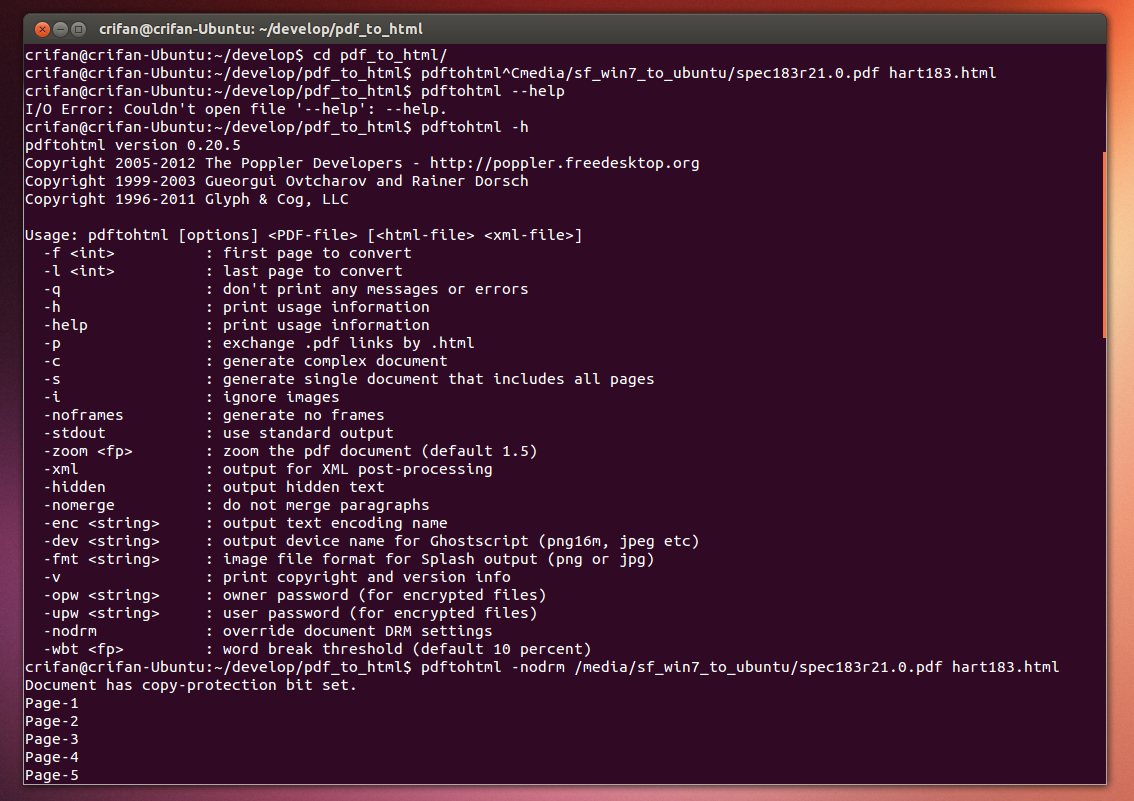
【背景】 折腾: 【未解决】将不可拷贝复制的PDF中的表格数据导出并转换为xml格式数据 期间,去试试用pdftohtml,将一个不可拷贝的pdf文件,转换为文本或html。 【折腾过程】 1.继续参考: Howto Convert P...
crifan 12年前 (2014-01-27) 3154浏览 0评论
【背景】 折腾: 【未解决】将不可拷贝复制的PDF中的表格数据导出并转换为xml格式数据 期间,去试试用xpdf,将一个不可拷贝的pdf文件,转换为文本或html。 【折腾过程】 1.参考: PDFTOHTML conversion p...
crifan 12年前 (2014-01-27) 4504浏览 3评论
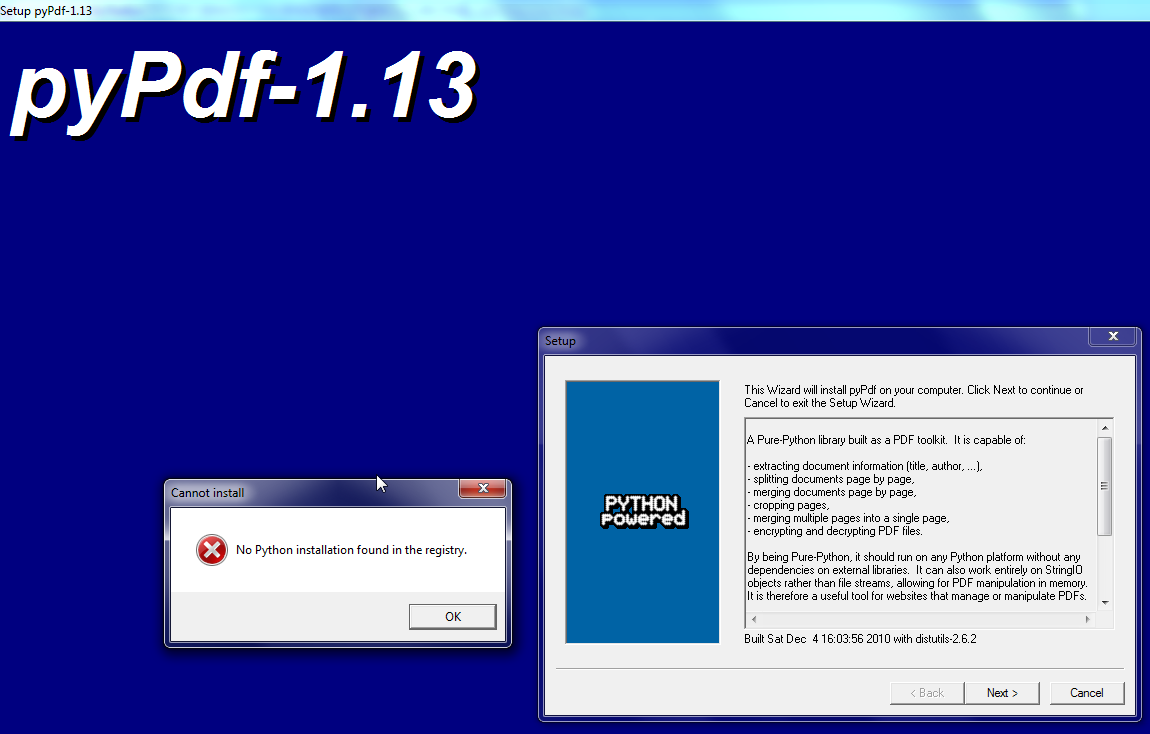
【背景】 折腾: 【未解决】将不可拷贝复制的PDF中的表格数据导出并转换为xml格式数据 期间,去试试使用pyPdf去把一个不可复制的PDF文件,转换为文本或HTML。 【折腾过程】 1.参考: Convert PDF to text ...
crifan 12年前 (2014-01-27) 3024浏览 1评论
【背景】 折腾: 【未解决】将不可拷贝复制的PDF中的表格数据导出并转换为xml格式数据 期间,打算去试试使用PDFMiner去把PDF,且是个加了密,不可拷贝的PDF,看看能否转换为文本或HTML。 【折腾过程】 1.找到主页: PD...
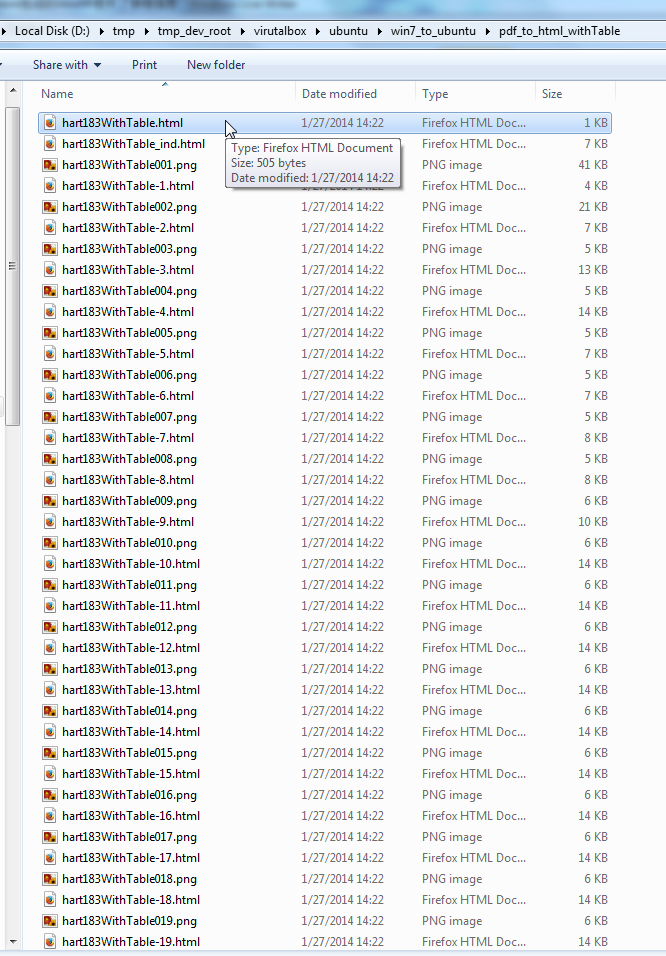
crifan 12年前 (2014-01-27) 3143浏览 0评论
【背景】 折腾: 【未解决】将不可拷贝复制的PDF中的表格数据导出并转换为xml格式数据 期间,虽然可以用pdftohtml通过加-nodrm参数而使得将不可复制的pdf生成html。 但是生成的html中,丢失了原先pdf中有个那些表格的数据,只剩...
crifan 12年前 (2013-10-17) 4633浏览 0评论
之前见过不止一个人,比如: 用正则表达式得到某个div标签内部的div标签中的内容 之前某人写sina搬家到wordpress,也是全部用的是正则表达式实现的 -> 如果其遇到足够复杂的html代码,估计就会发现,正则基本上就没法使用了...