【记录】Python中尝试用lxml去解析html
crifan 13年前 (2013-05-27) 10698浏览 0评论
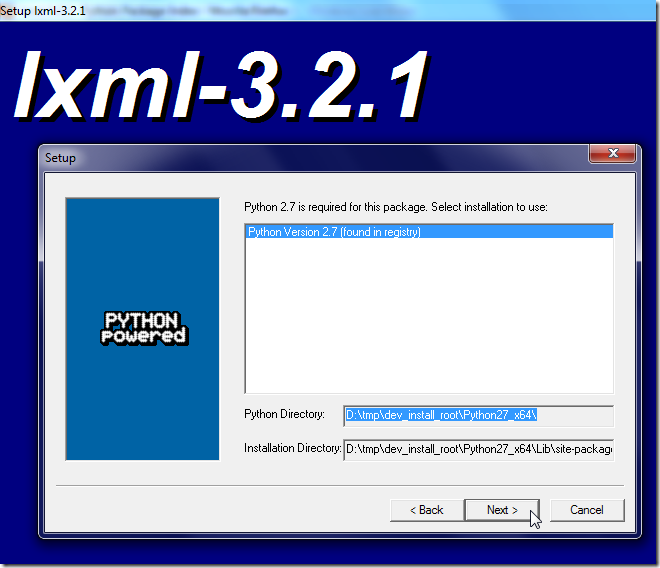
【背景】 Python中,之前一直用BeautifulSoup去解析html的: 【教程】Python中第三方的用于解析HTML的库:BeautifulSoup 后来听说BeautifulSoup很慢,而lxml解析html速度很快,所以打算去试试...
crifan 13年前 (2013-05-27) 10698浏览 0评论
【背景】 Python中,之前一直用BeautifulSoup去解析html的: 【教程】Python中第三方的用于解析HTML的库:BeautifulSoup 后来听说BeautifulSoup很慢,而lxml解析html速度很快,所以打算去试试...

crifan 13年前 (2013-05-24) 12104浏览 0评论
【问题】 在折腾: 【记录】用Scrapy抓取manta.com 期间,运行scrapy项目,结果出错: E:\Dev_Root\python\Scrapy\manta\manta>scrapy crawl manta -o respB...
crifan 13年前 (2013-05-24) 3819浏览 0评论
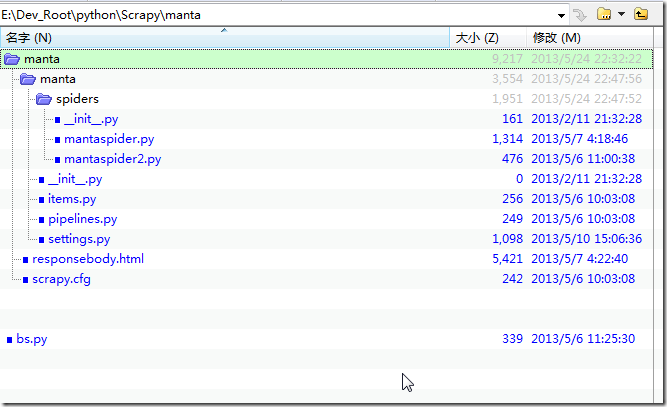
【问题】 手上有个Scrapy的项目,是要抓取和 http://www.manta.com/ 相关的站点的内容。 已有源码为: bs.py: import requests from bs4 import BeautifulSoup ...
crifan 13年前 (2013-05-24) 8625浏览 0评论
【问题】 别人遇到的问题: 求正则表达式牛人 怎样获得截获了多次的组的所有子串 Match.group(i)方法说明里说 如果一个组被截获了多次 则 截获了多次的组返回最后一次截获的子串 比如&q...
crifan 13年前 (2013-05-20) 5916浏览 0评论
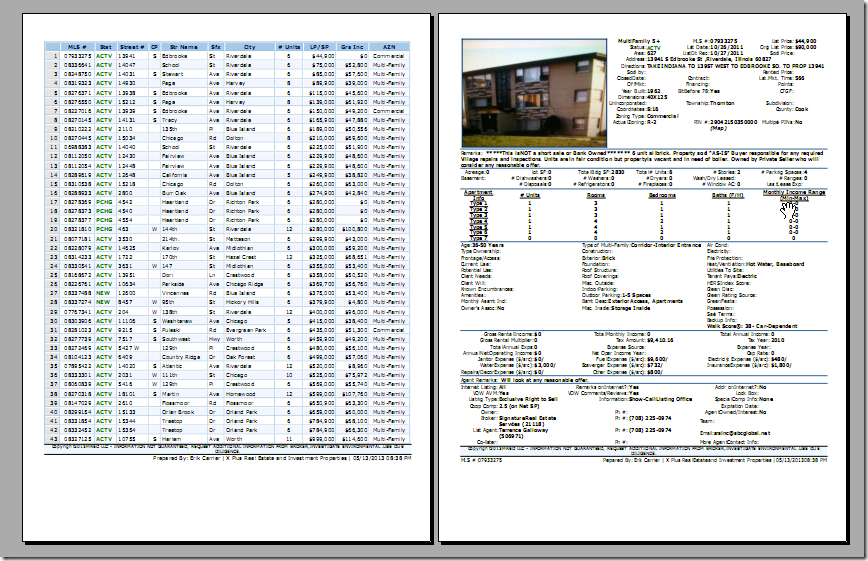
【背景】 已有一个pdf文件,效果如下: 想要用python从中提取一些信息。 【折腾过程】 1.搜了下,找到个: pyPdf http://pybrary.net/pyPdf/ 其功能之一是: “extracting document infor...
crifan 13年前 (2013-05-15) 13450浏览 0评论
【背景】 看到: python将json转换成xml 所以先去试试,用python实现,将xml转为json。 【解决过程】 1.参考: python中将XML转换为JSON格式 所以先以: <student> ...
crifan 13年前 (2013-05-08) 4055浏览 0评论
待完成,最新更新:2013-05-08 把之前的: 【详解】Python中的文件操作,readline读取单行,readlines读取全部行,文件打开模式 中的部分内容整理过来,再加上更多的解释。 关于文件的基本知识 &...
crifan 13年前 (2013-05-03) 7392浏览 0评论
【问题】 已经通过Python中的BeautifulSoup获得了对应的soup: LINE 253 : INFO foundDescription=<td va...
crifan 13年前 (2013-05-02) 7703浏览 0评论
【问题】 python中,用如下代码: #http://autoexplosion.com/cars/buy/150954.php #error : #TypeError: sequence item 1: expected ...
crifan 13年前 (2013-05-02) 46042浏览 10评论
待完成,最近更新:2013-05-08 【背景】 Python中的正则表达式方面的功能,很强大。 其中就包括re.sub,实现正则的替换。 功能很强大,所以导致用法稍微有点复杂。 所以当遇到稍微复杂的用法时候,就容易犯错。 所以此处,总...