
【整理】关于python中文件open后去调用read()时需要知道的事情:只需调用一次即可获得文件的全部内容
crifan 13年前 (2013-09-23) 8553浏览 0评论
关于,python中,文件被open打开后 再去调用read(),需要注意的是: 只需要调用一次read(),即可(读取出)获得文件的,所有的,内容了。 示例代码如下: #!/usr/bin/python # -*- coding: utf-8 -*...
crifan 13年前 (2013-09-23) 8553浏览 0评论
关于,python中,文件被open打开后 再去调用read(),需要注意的是: 只需要调用一次read(),即可(读取出)获得文件的,所有的,内容了。 示例代码如下: #!/usr/bin/python # -*- coding: utf-8 -*...
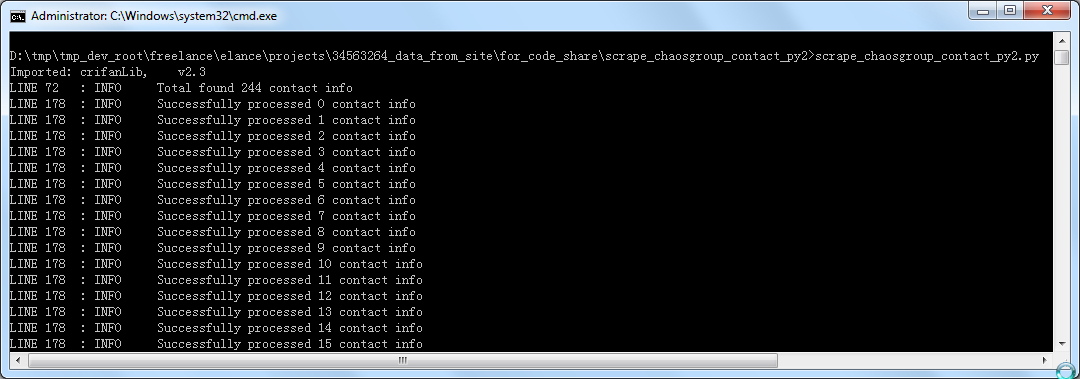
crifan 13年前 (2013-09-23) 2762浏览 0评论
背景】 之前写的,前后共写了两个版本的: Python 2.x版本 和 Python 3.x版本 去抓取 http://www.chaosgroup.com/ 中联系人信息,并保存为excel文件 【scrape_ch...
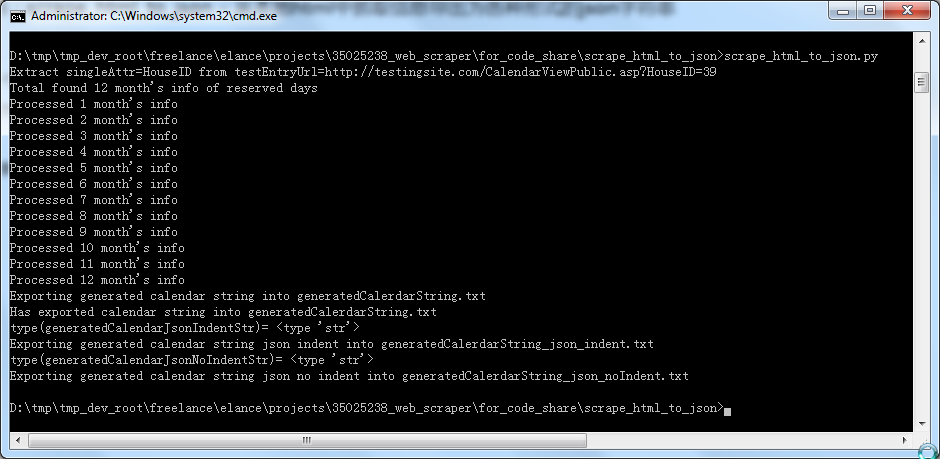
crifan 13年前 (2013-09-23) 2480浏览 0评论
背景】 之前写的,去处理本地已有的一个html文件, 然后对于提取出来的信息,导出为,各种形式的json字符串。 【scrape_html_to_json代码分享】 1.截图: (1)运行效果: (2)输出的各种json字符...
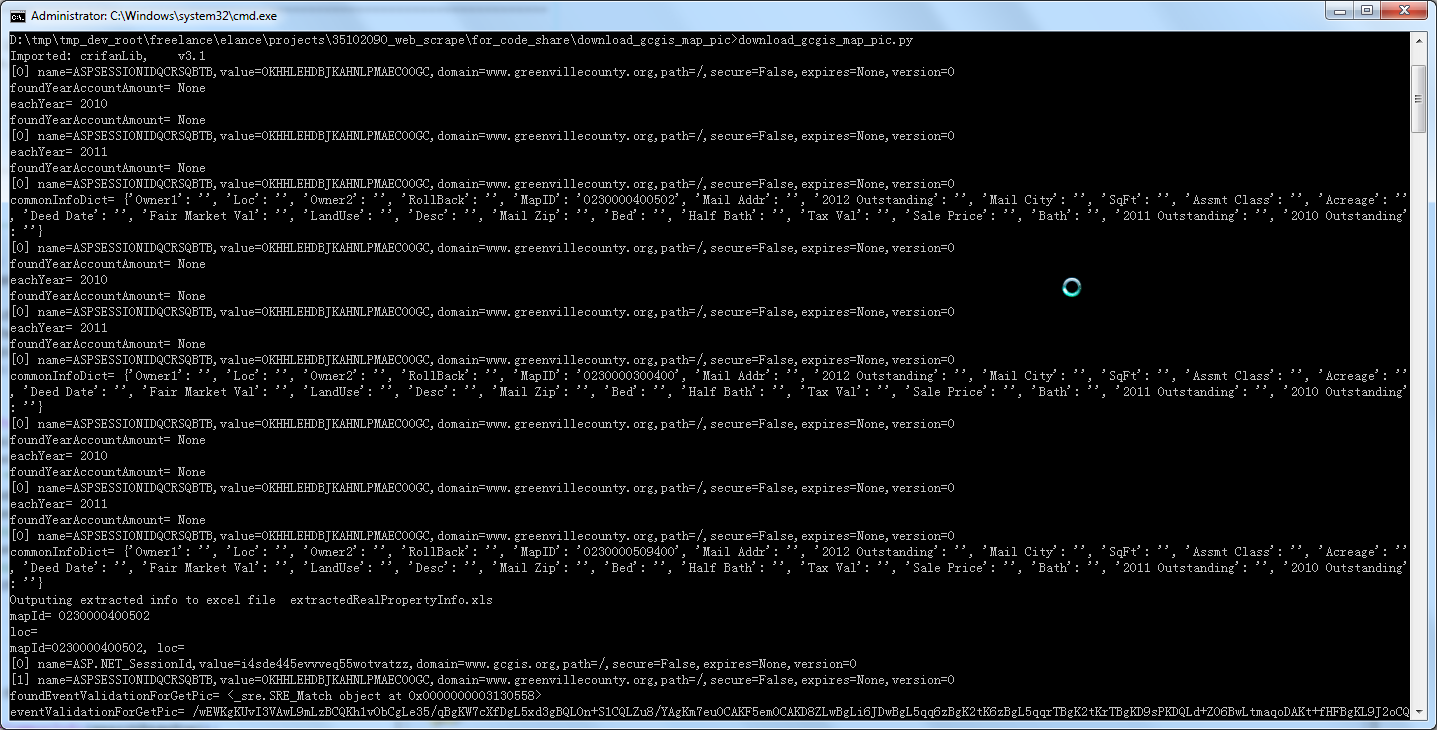
crifan 13年前 (2013-09-23) 3120浏览 0评论
【背景】 之前写的,去处理: http://www.gcgis.org/webmappub/titleWF.aspx http://www.greenvillecounty.org/vrealpr24/clRealProp.ASP?WCI=tp...
crifan 13年前 (2013-09-23) 2372浏览 0评论
【背景】 之前写的,去模拟: http://www.menupix.com 然后获得返回的jsonp字符串。 【scrape_menupix_com代码分享】 1.截图: (1)运行效果: 返回的jsonp示例: jsonp...
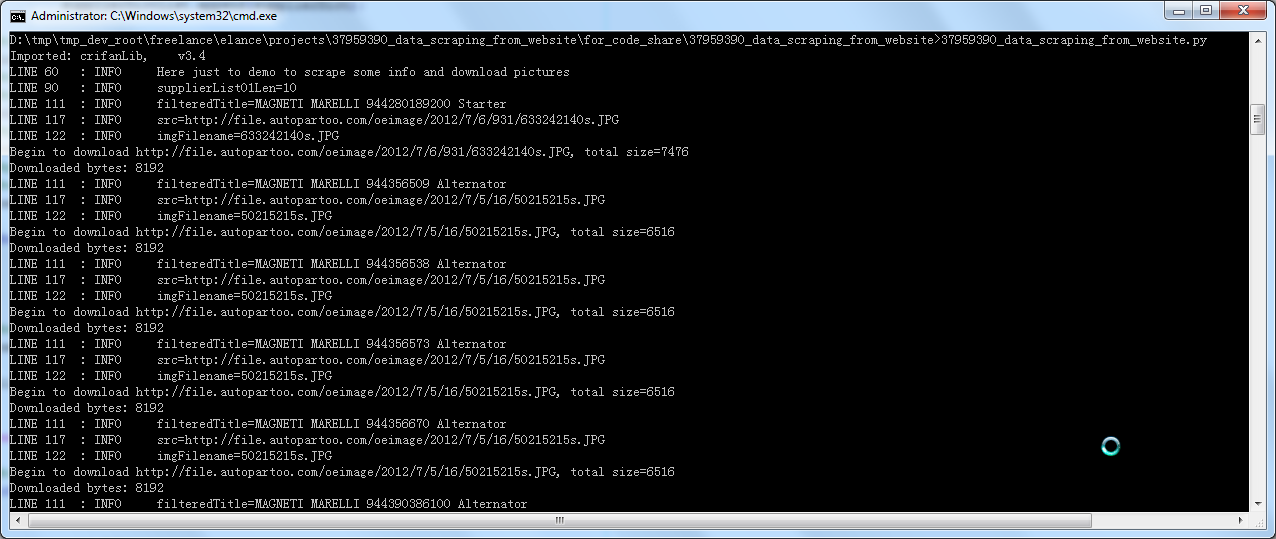
crifan 13年前 (2013-09-23) 2712浏览 0评论
【背景】 之前写的,去下载: http://www.autopartoo.com 中的图片,并且保存图片信息为csv文件。 【37959390_data_scraping_from_website代码分享】 1.截图: (1...
crifan 13年前 (2013-09-22) 4542浏览 3评论
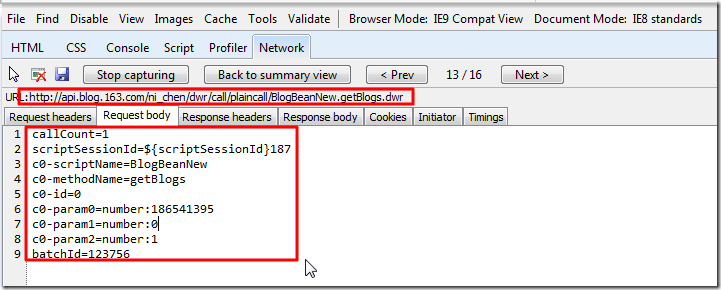
【背景】 之前的 BlogsToWordpress 不支持网易的心情随笔。 现在去添加此功能。 【解决过程】 1.结果使用: BlogsToWordpress.py -s http://blog.163.com/ni_chen 竟然结果连...
crifan 13年前 (2013-09-22) 25049浏览 3评论
【背景】 问题参见: python2.7 urllib2 抓取新浪乱码 中的: 报错的异常是 UnicodeDecodeError: ‘gbk’ codec can’t decode...
crifan 13年前 (2013-09-16) 6400浏览 0评论
【背景】 之前已经使用过chardet了,也算用了不少次了。 之前也写过和chardet相关的: 【已解决】windows下,安装python的chardet 【问题】Python中用Chardet检测出来从Windows的cmd中输入的字符串的编码...
crifan 13年前 (2013-09-10) 5167浏览 0评论
【背景】 之前折腾技术的时候,或多或少,知道一个东西: DocxyGen 是用于从代码生成文档的。 最近,又从: Seeking very simple ANTLR error handling example when generating C c...