折腾:
【未解决】Python的Playwright去解析提取百度搜索的结果
期间,代码:
resultASelector = "h3[class^='t'] a" searchResultAList = page.query_selector_all(resultASelector)
之前调试期间可以获取到数据
现在直接运行,获取不到,返回为空。
估计也是:需要wait 等到某元素出现。
参考:
【整理】用Chrome或Chromium查看百度首页中各元素的html源码
的:
<span class="nums_text">百度为您找到相关结果约2,370,000个</span>
去看看如何写代码 等待此元素出现
看到
有:
* page.is_visible(selector, **kwargs)
后来也看到更希望的:
wait for的:
- * page.wait_for_event(event, **kwargs)
- * page.wait_for_function(expression, **kwargs)
- * page.wait_for_load_state(**kwargs)
- * page.wait_for_selector(selector, **kwargs)
- * page.wait_for_timeout(timeout)
其中的:
page.wait_for_selector
就是我要的
“page.wait_for_selector(selector, **kwargs)#
* selector <str> A selector to query for. See working with selectors for more details.
* state <“attached”|”detached”|”visible”|”hidden”> Defaults to ‘visible’. Can be either:
* ‘attached’ – wait for element to be present in DOM.
* ‘detached’ – wait for element to not be present in DOM.
* ‘visible’ – wait for element to have non-empty bounding box and no visibility:hidden. Note that element without any content or with display:none has an empty bounding box and is not considered visible.
* ‘hidden’ – wait for element to be either detached from DOM, or have an empty bounding box or visibility:hidden. This is opposite to the ‘visible’ option.
* timeout <float> Maximum time in milliseconds, defaults to 30 seconds, pass 0 to disable timeout. The default value can be changed by using the browser_context.set_default_timeout(timeout) or page.set_default_timeout(timeout) methods.
* returns: <NoneType|ElementHandle>
Returns when element specified by selector satisfies state option. Returns null if waiting for hidden or detached.
Wait for the selector to satisfy state option (either appear/disappear from dom, or become visible/hidden). If at the moment of calling the method selector already satisfies the condition, the method will return immediately. If the selector doesn’t satisfy the condition for the timeout milliseconds, the function will throw.
This method works across navigations:”
示例代码 :
from playwright.sync_api import sync_playwright
def run(playwright):
chromium = playwright.chromium
browser = chromium.launch()
page = browser.new_page()
for current_url in ["https://google.com", "https://bbc.com"]:
page.goto(current_url, wait_until="domcontentloaded")
element = page.wait_for_selector("img")
print("Loaded image: " + str(element.get_attribute("src")))
browser.close()
with sync_playwright() as playwright:
run(playwright)去写代码
SearchFoundWordsSelector = 'span.nums_text' # SearchFoundWordsXpath = "//span[@class='nums_text']" page.wait_for_selector(SearchFoundWordsSelector, state="visible")
结果:
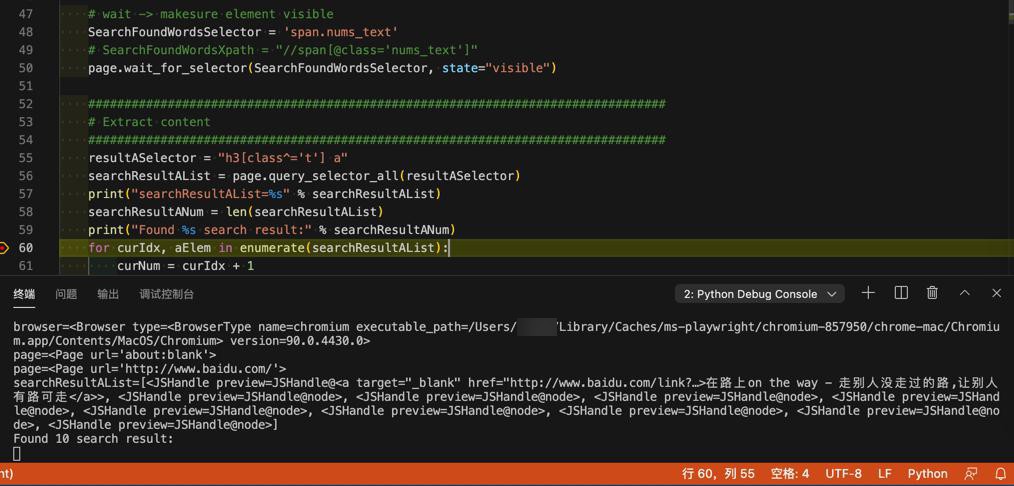
即可确保 元素出现-》表示页面加载完毕,后续可以找到数据
【总结】
此处之前代码:
page.query_selector_all(resultASelector)
找不到元素,是由于 百度首页触发搜索后,页面内容重新加载
此处需要去等待页面内容重新加载完毕,才能后续找到元素
具体方式是:用page的wait_for_selector
代码:
# wait -> makesure element visible SearchFoundWordsSelector = 'span.nums_text' page.wait_for_selector(SearchFoundWordsSelector, state="visible")
即可。
转载请注明:在路上 » 【已解决】Python的Playwright用page.query_selector_all找不到元素