折腾:
【未解决】从蝉大师搜索塔防结果中生成安卓游戏测试任务列表
期间,遇到一个问题:
从utf-8的csv读取出内容后,发现第一个字符是\ufeff
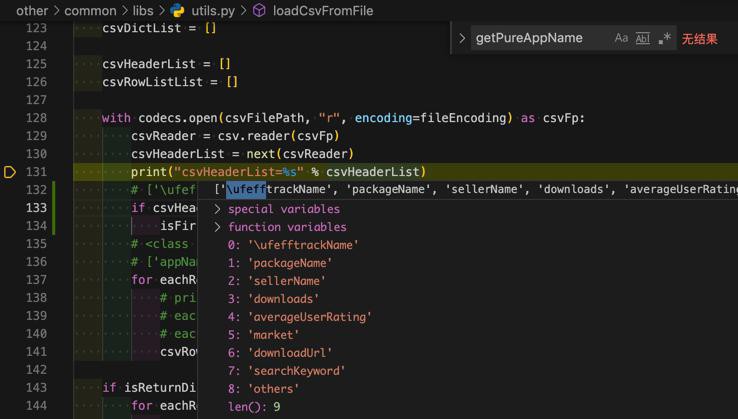
# ['\ufefftrackName', ...
需要去解决掉。
调试打印:
print(csvHeaderList[0])
输出,第一个好像是空格:
trackName

本来想自己用re.match去匹配的。
utf 8 ufeff
去试试utf-8-sig:
# def loadCsvFromFile(csvFilePath, fileEncoding="utf-8", isReturnDictList=True): def loadCsvFromFile(csvFilePath, fileEncoding="utf-8-sig", isReturnDictList=True):
效果:
是对的:
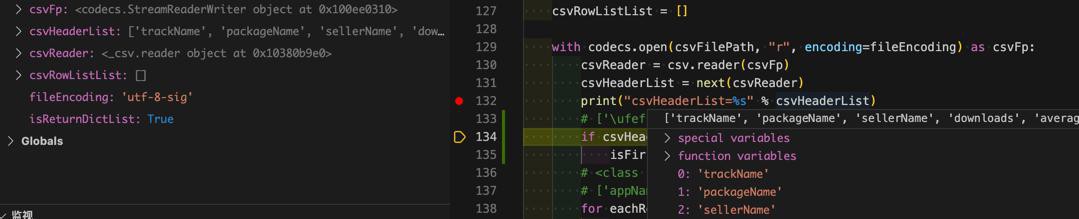
去掉了signature
不过,要去确保,如果本身utf-8的文件中没signature,用utf-8-sig是否会报错

不会报错。是没问题的。那就保留这个写法:默认utf-8-sig
【总结】
部分utf-8的文件,最开始是带BOM的,即signature的,比如此处:
\ufeff
如果传入utf-8去读取:
with codecs.open(csvFilePath, "r", encoding='utf-8') as csvFp:
去除出的第一个字符是:\ufeff
解决办法:
把utf-8,换utf-8-sig,即可:
with codecs.open(csvFilePath, "r", encoding='utf-8-sig') as csvFp:
自动识别文件开始是否有signature,而自动忽略掉,即可实现效果:
utf-8的带或不带BOM头的,都可以正常解析,忽略掉最开始的signature。