折腾:
【未解决】用Python爬虫框架PySpider实现爬虫爬取百度热榜内容列表
期间,此处已经可以抓取到要的标题列表了。
现在希望单个页面能返回(一个列表中的)多个结果
此处不知道如何实现 每次返回单个结果
pyspider return 返回多个结果
竟然搜到的第一个是我自己的帖子
改为:
curResult = {
# "url": response.url,
"百度热榜标题": itemTitleStr,
}
# return curResult
self.send_message(self.project_name, curResult, url=response.url)结果:
终于可以返回多个结果了:
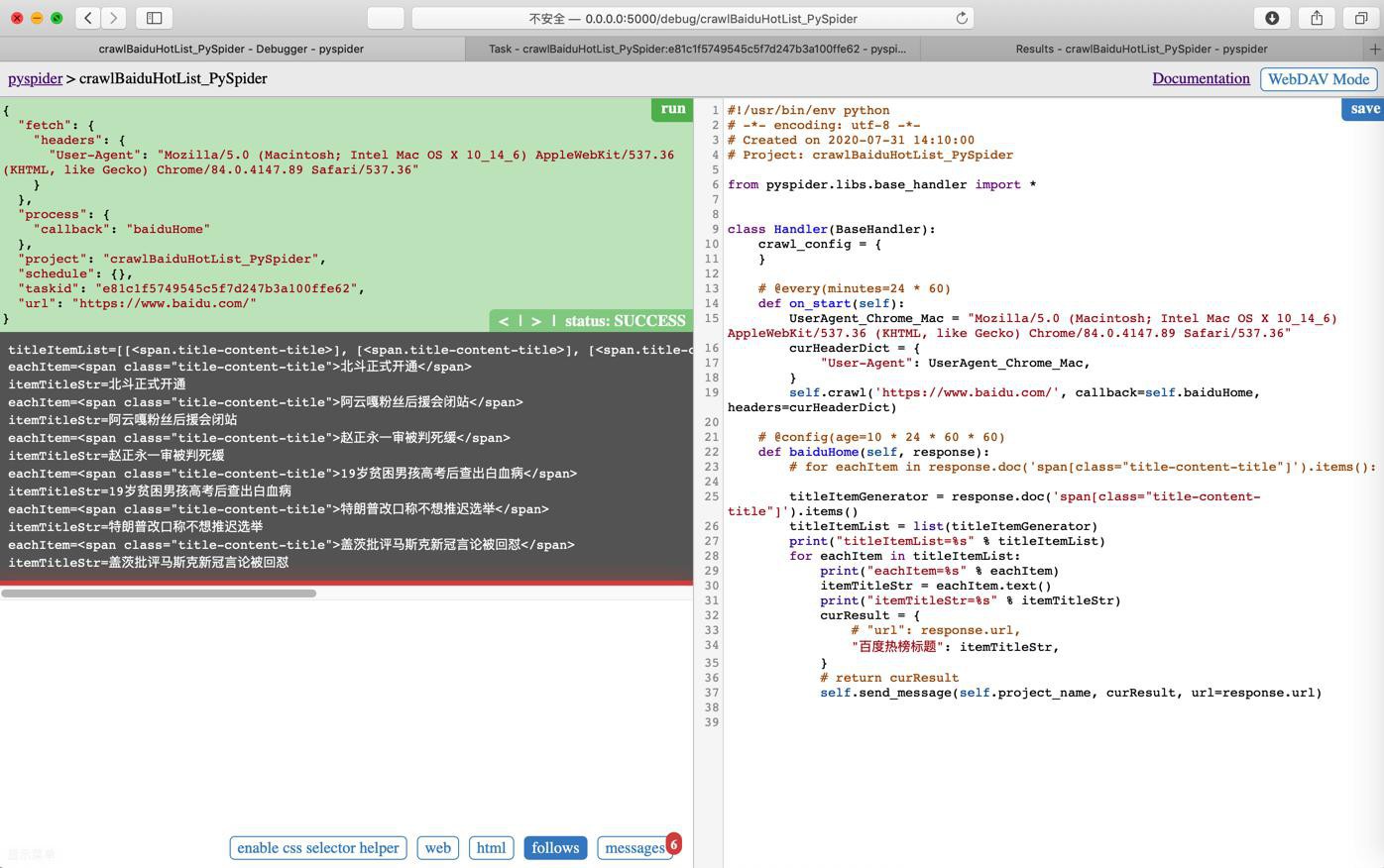
但是去Run后,发现列表中并没有我们要的结果

发现了,忘了加on_message了。。。
调试:
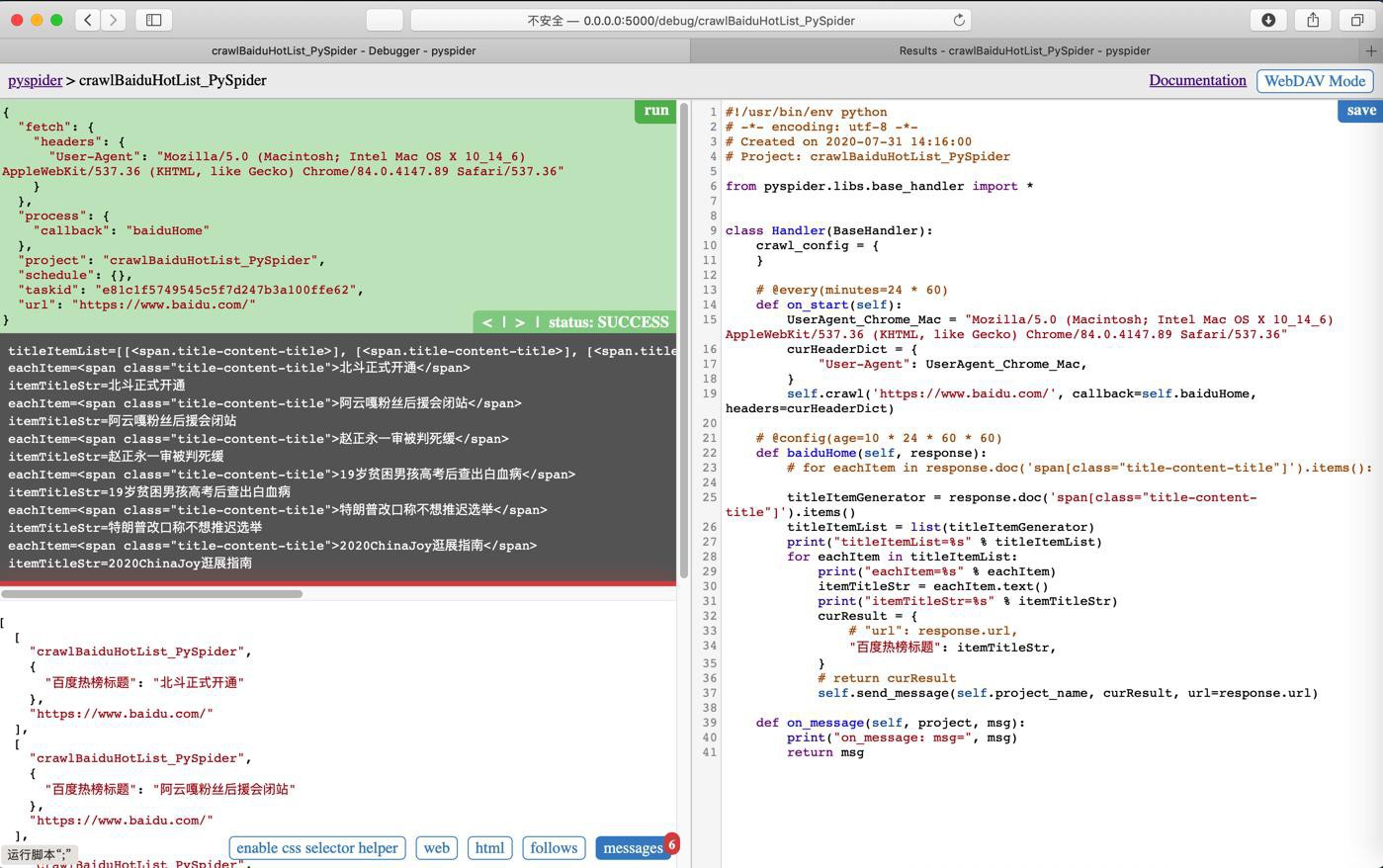
去运行:
问题依旧。结果还是没有。
还是参考:
去试试ResultDB
发现也不对,需要额外
resultdb = connect_database("<your resutldb connection url>")此处不希望引入额外数据库。
好像可以多次调用on_result去保存?
后记:自己回复了:
好像是:url重复了?
那去使得url不重复试试?
不过,先确保Results中能看到这个 即使只有的 一个结果:
curResult = {
# "url": response.url,
"百度热榜标题": itemTitleStr,
}
return curResult
# self.send_message(self.project_name, curResult, url=response.url)
# def on_message(self, project, msg):
# print("on_message: msg=", msg)
# return msg结果
调试时,正常,返回单个结果:
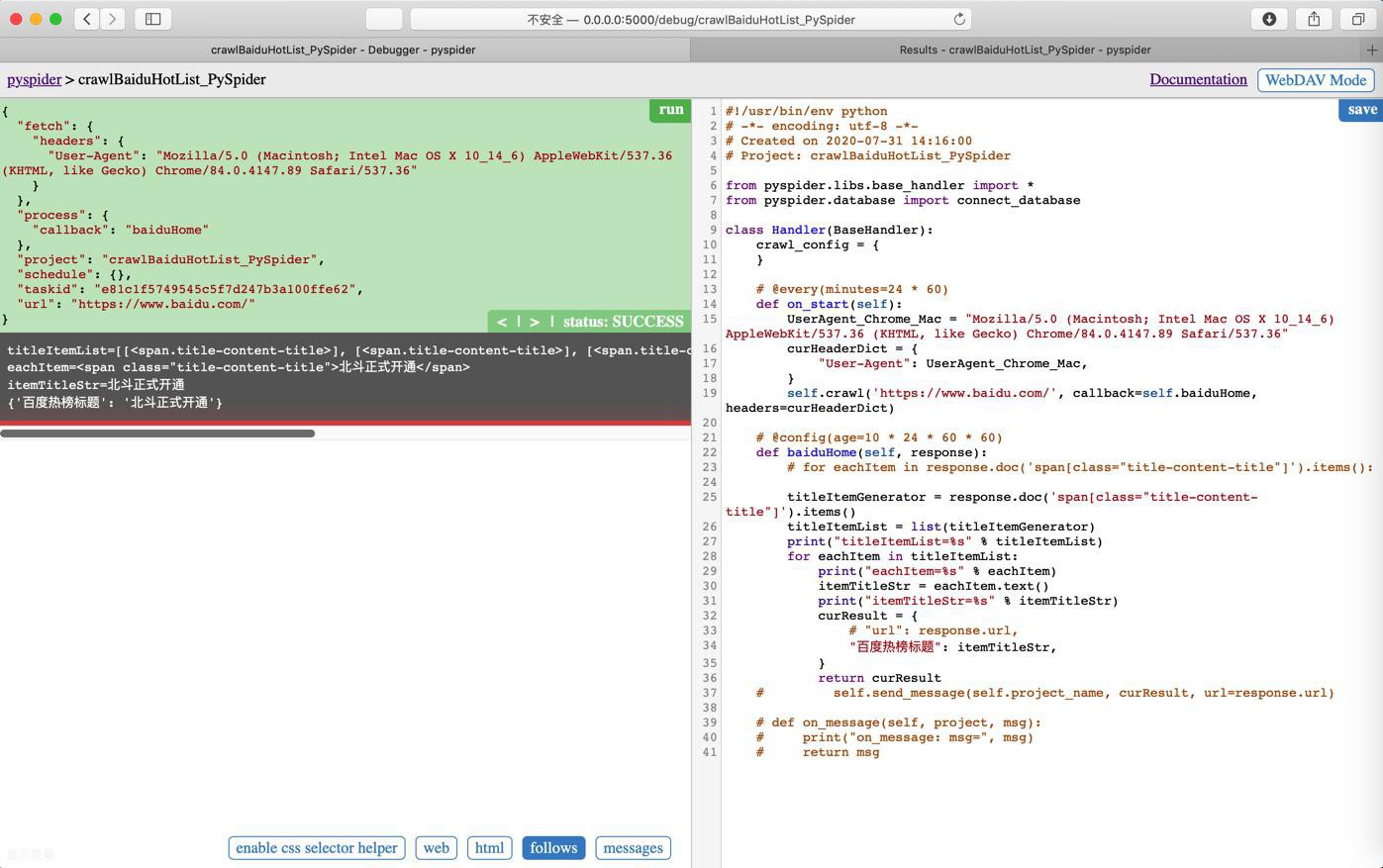
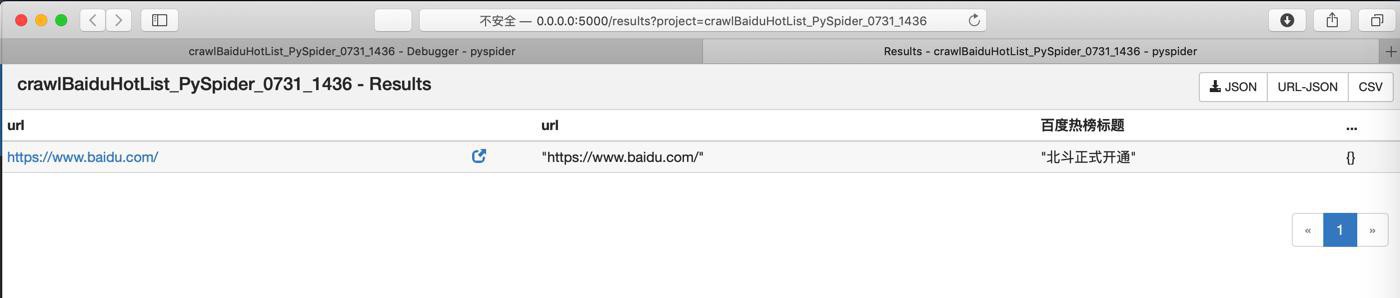
去看看Results中:

还是空的。
返回时加上url
curResult = {
"url": response.url,
"百度热榜标题": itemTitleStr,
}
return curResult结果:
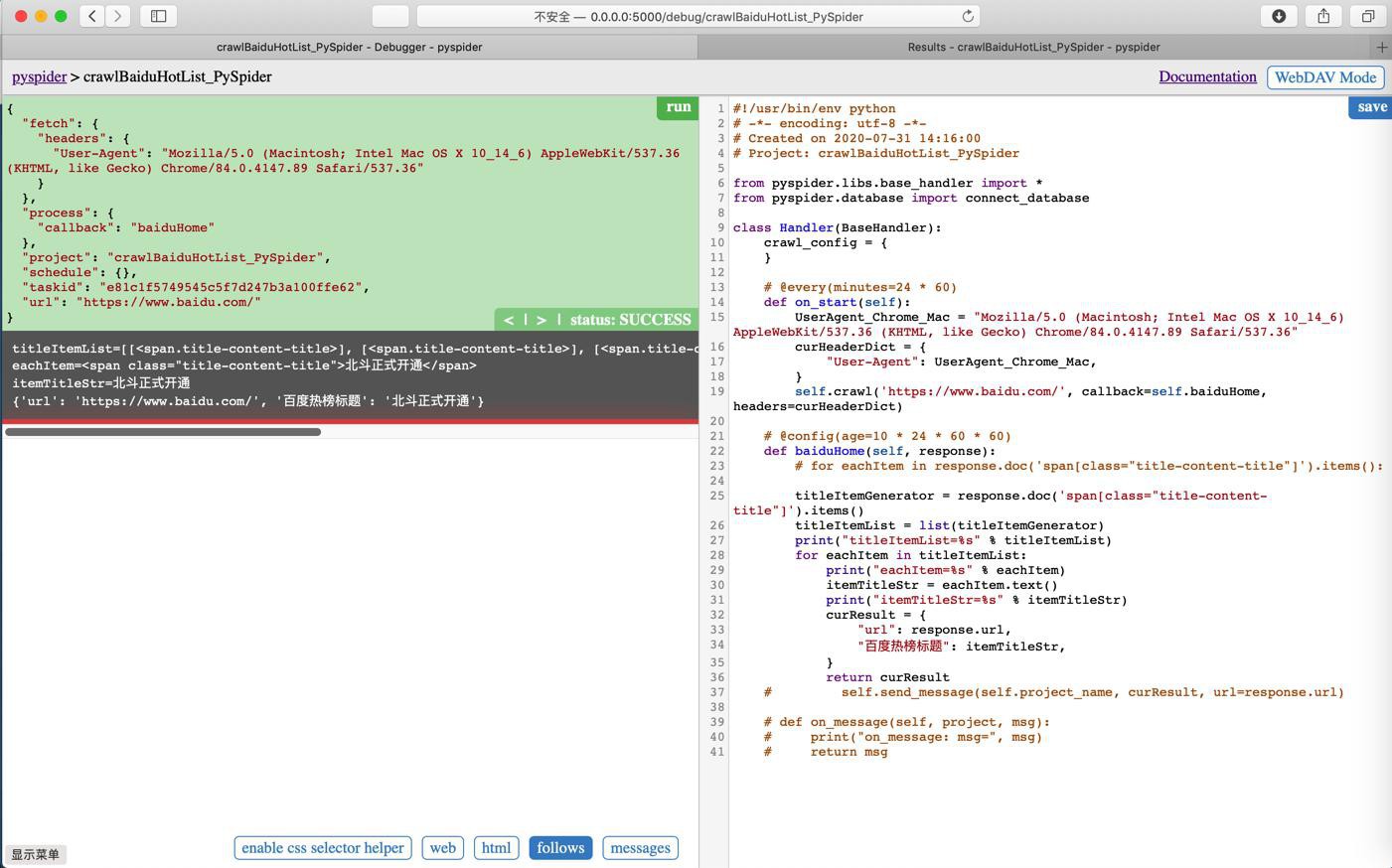
再看看Results
依旧是空。
删除项目重新创建试试
然后设置了RUNNING,再点击Run:
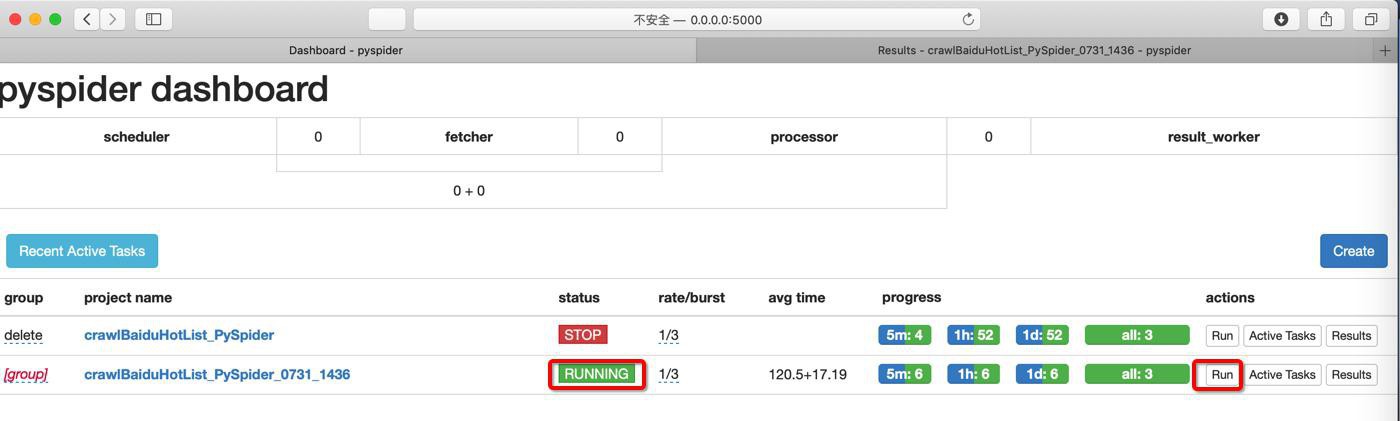
才会有结果:

那就正常了。
然后再去改造,返回多个结果:
# for eachItem in titleItemList:
for curIdx, eachItem in enumerate(titleItemList):
print("[%d] eachItem=%s" % (curIdx, eachItem))
itemTitleStr = eachItem.text()
print("itemTitleStr=%s" % itemTitleStr)
curUrl = "%s#%d" % (response.url, curIdx)
print("curUrl=%s" % curUrl)
curResult = {
# "url": response.url,
"url": curUrl,
"百度热榜标题": itemTitleStr,
}
return curResult结果:
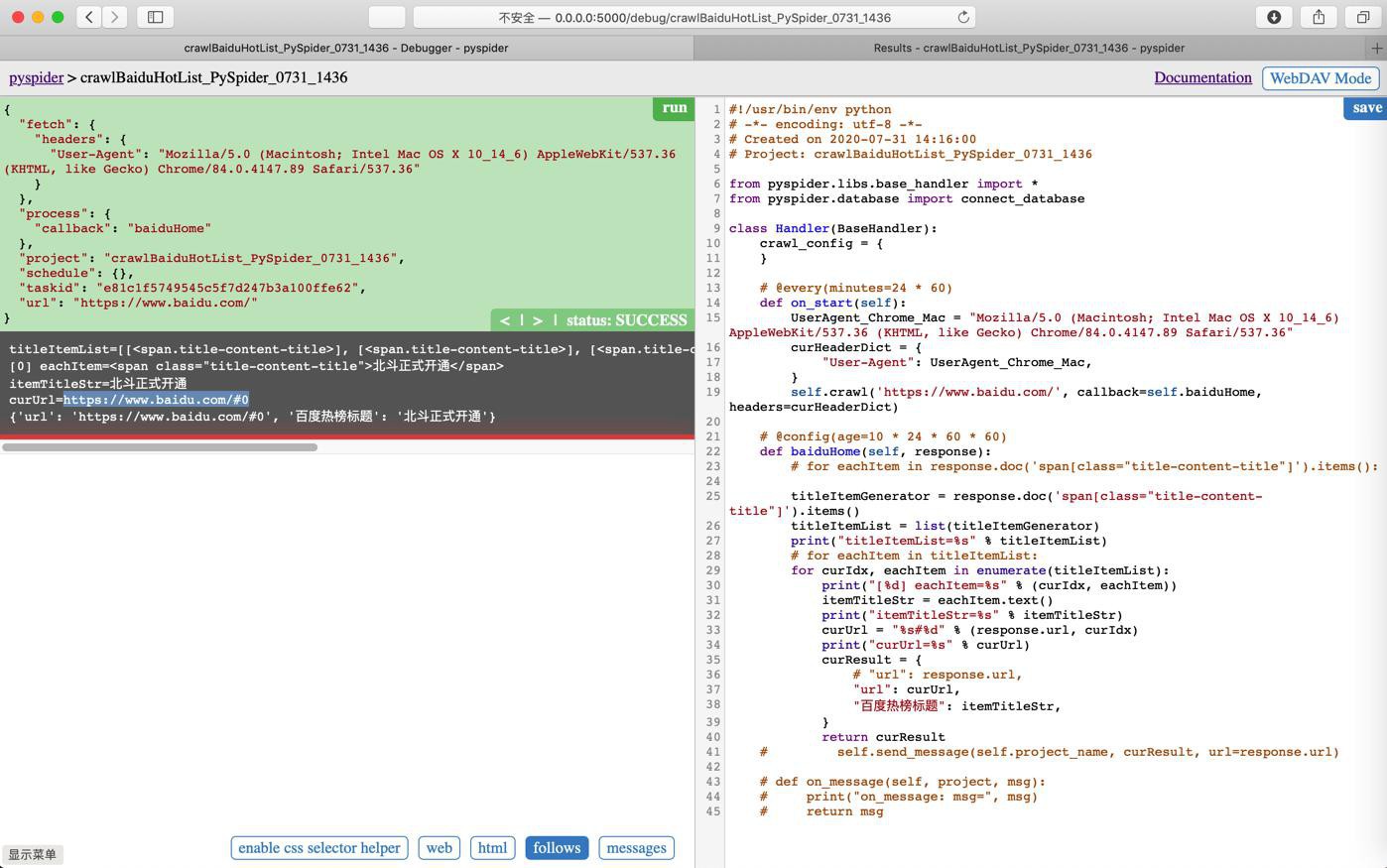
但是试了半天,保存的结果,始终没能更新
url没有变成调试时候的:
https://www.baidu.com/#0
算了,再去重新新建?
好像也不合适。
算了,参考之前的逻辑和官网文档
想办法,尽快删除原有项目:
pyspider scheduler --delete-time=30
重新运行:
✘ xxx@xxx ~/dev/crifan/python/demo_spider pyspider scheduler --delete-time=30 [I 200731 14:45:16 scheduler:647] scheduler starting... [I 200731 14:45:16 scheduler:782] scheduler.xmlrpc listening on 0.0.0.0:23333 [I 200731 14:45:16 scheduler:126] project crawlBaiduHotList_PySpider updated, status:STOP, paused:False, 0 tasks [I 200731 14:45:16 scheduler:126] project crawlBaiduHotList_PySpider_0731_1436 updated, status:DEBUG, paused:False, 0 tasks [I 200731 14:45:16 scheduler:965] select crawlBaiduHotList_PySpider_0731_1436:_on_get_info data:,_on_get_info [I 200731 14:45:16 scheduler:586] in 5m: new:0,success:0,retry:0,failed:0 [W 200731 14:45:16 scheduler:613] deleting project: crawlBaiduHotList_PySpider!

立刻就删除了之前的旧项目。
但是无法通过
去打开UI了。
所以换成配置文件
config.json
{
"webui": {
"port": 5000,
"need-auth": false
},
"scheduler": {
"delete_time": 30
}
}运行调用效果:
pyspider -c use_python_spider_framework/config.json
[I 200731 14:48:06 result_worker:49] result_worker starting...
phantomjs fetcher running on port 25555
[I 200731 14:48:06 processor:211] processor starting...
[I 200731 14:48:06 scheduler:647] scheduler starting...
[I 200731 14:48:06 tornado_fetcher:638] fetcher starting...
[I 200731 14:48:06 scheduler:782] scheduler.xmlrpc listening on 127.0.0.1:23333
[I 200731 14:48:06 scheduler:126] project crawlBaiduHotList_PySpider_0731_1436 updated, status:DEBUG, paused:False, 0 tasks
[I 200731 14:48:06 scheduler:965] select crawlBaiduHotList_PySpider_0731_1436:_on_get_info data:,_on_get_info
[I 200731 14:48:06 scheduler:586] in 5m: new:0,success:0,retry:0,failed:0
[I 200731 14:48:06 tornado_fetcher:188] [200] crawlBaiduHotList_PySpider_0731_1436:_on_get_info data:,_on_get_info 0s
[D 200731 14:48:06 project_module:145] project: crawlBaiduHotList_PySpider_0731_1436 updated.
[I 200731 14:48:06 processor:202] process crawlBaiduHotList_PySpider_0731_1436:_on_get_info data:,_on_get_info -> [200] len:12 -> result:None fol:0 msg:0 err:None
[I 200731 14:48:06 scheduler:360] crawlBaiduHotList_PySpider_0731_1436 on_get_info {'min_tick': 0, 'retry_delay': {}, 'crawl_config': {}}
[I 200731 14:48:06 app:76] webui running on 0.0.0.0:5000
然后新建项目后,结果对了:

url是:
“https://www.baidu.com/#0”
然后继续试试message的效果:
print("curUrl=%s" % curUrl)
curResult = {
# "url": response.url,
"url": curUrl,
"百度热榜标题": itemTitleStr,
}
# return curResult
# self.send_message(self.project_name, curResult, url=response.url)
self.send_message(self.project_name, curResult, url=curUrl)
def on_message(self, project, msg):
print("on_message: msg=", msg)
return msg结果:
问题依旧。还是只有一个。
作者自己说了,就是用on_message
def detail_page(self, response):
for i, each in enumerate(response.json['products']):
self.send_message(self.project_name, {
"name": each['name'],
'price': each['prices'],
}, url="%s#%s" % (response.url, i))
def on_message(self, project, msg):
return msg但是自己此处好像就是没生效?
重新删除项目再试试
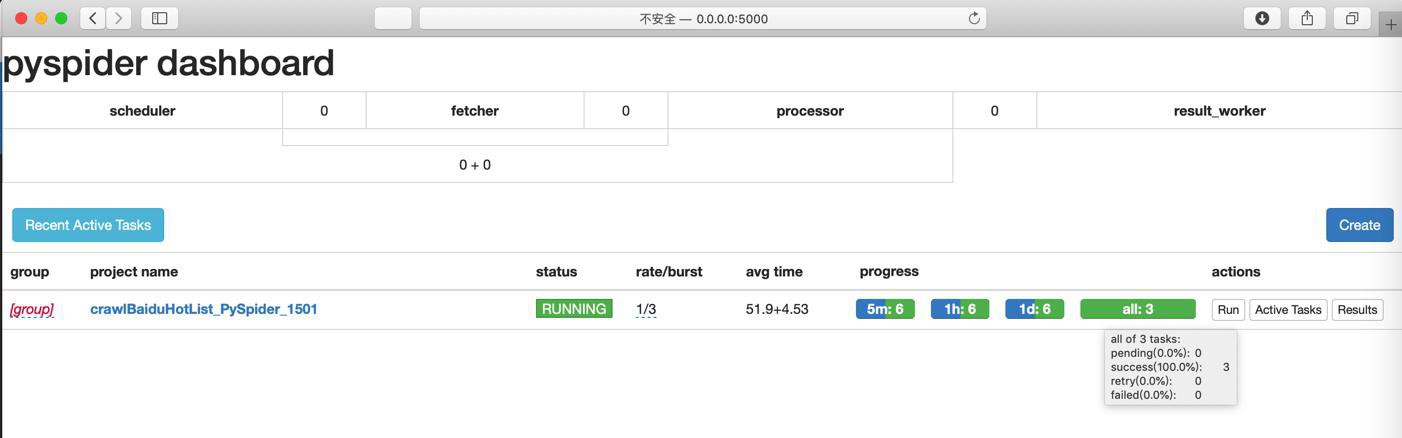
就可以了:
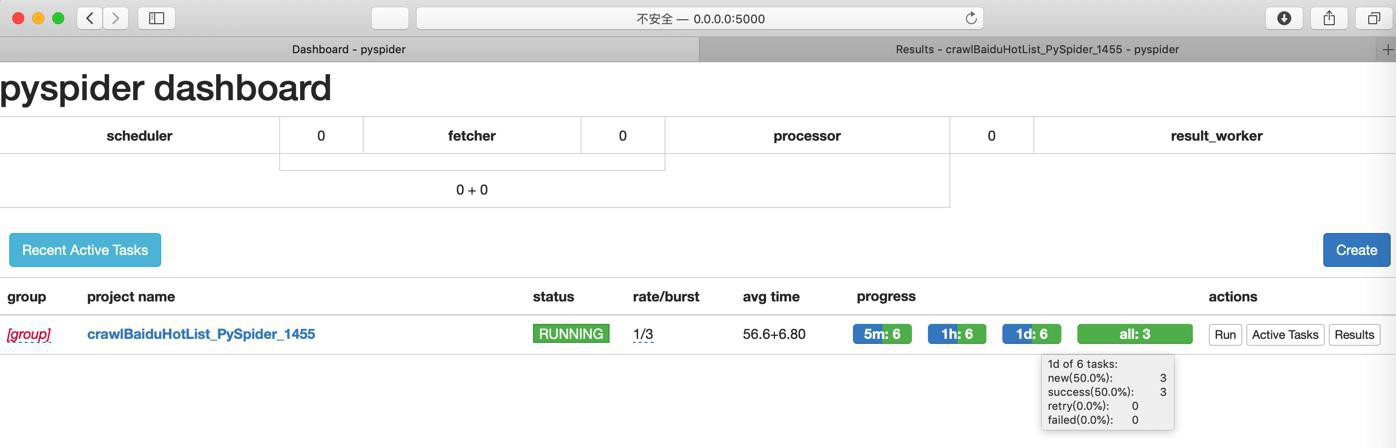
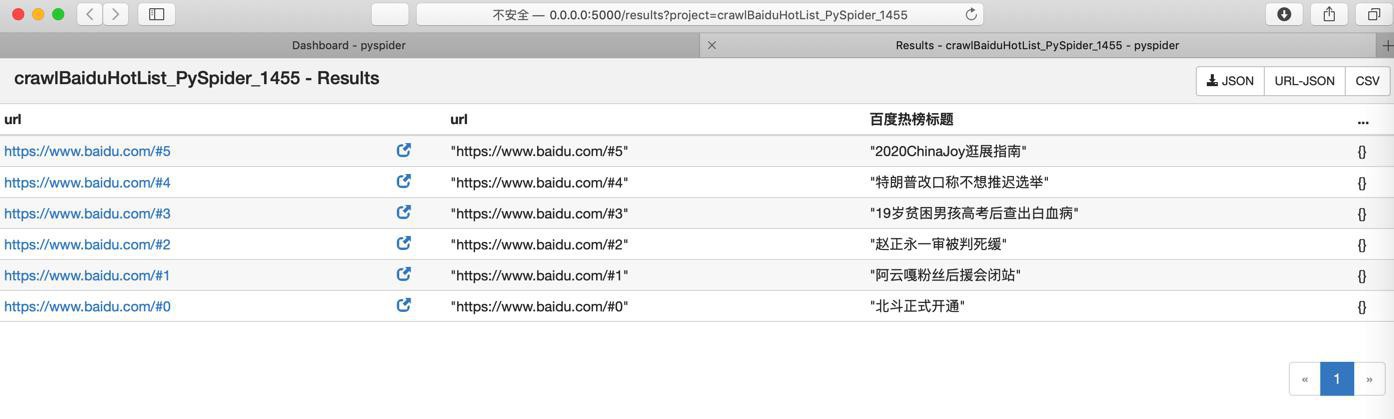
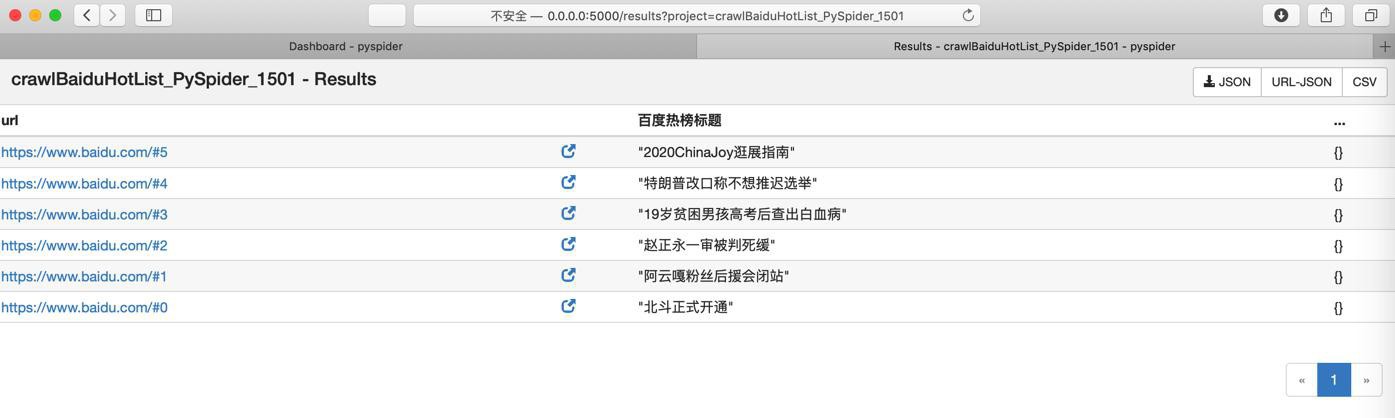
点击CSV去导出:

url,url,百度热榜标题,...
https://www.baidu.com/#5,https://www.baidu.com/#5,2020ChinaJoy逛展指南,{}
https://www.baidu.com/#4,https://www.baidu.com/#4,特朗普改口称不想推迟选举,{}
https://www.baidu.com/#3,https://www.baidu.com/#3,19岁贫困男孩高考后查出白血病,{}
https://www.baidu.com/#2,https://www.baidu.com/#2,赵正永一审被判死缓,{}
https://www.baidu.com/#1,https://www.baidu.com/#1,阿云嘎粉丝后援会闭站,{}
https://www.baidu.com/#0,https://www.baidu.com/#0,北斗正式开通,{}就得到我们要的数据了。
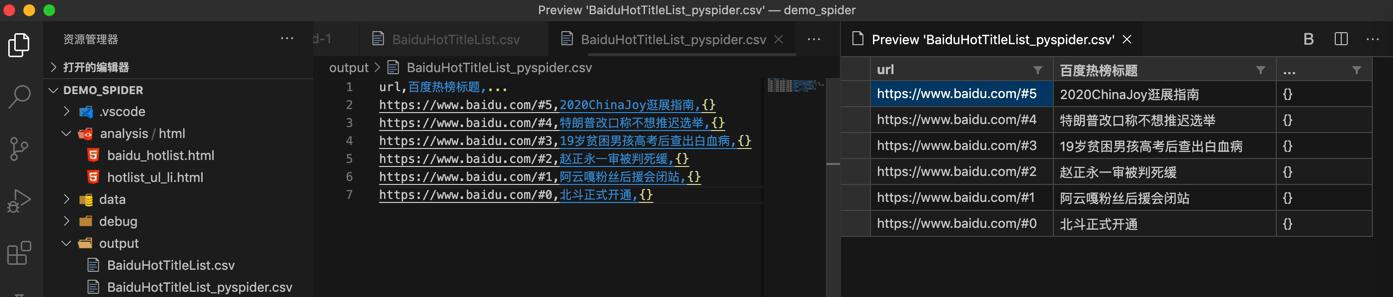
以列表形式预览:
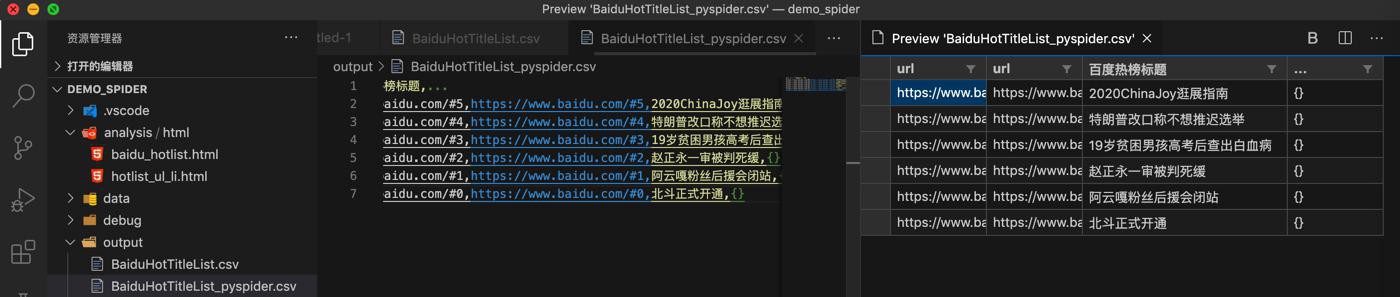
当然,如果不想要url,则可以用VSCode列编辑模式去删除掉
或者用excel打开,删除不要的第一列url和最后一列 … 也可以。
再去修改代码,去掉返回的url字段:
curResult = {
# "url": response.url,
# "url": curUrl,
"百度热榜标题": itemTitleStr,
}结果:
调试:
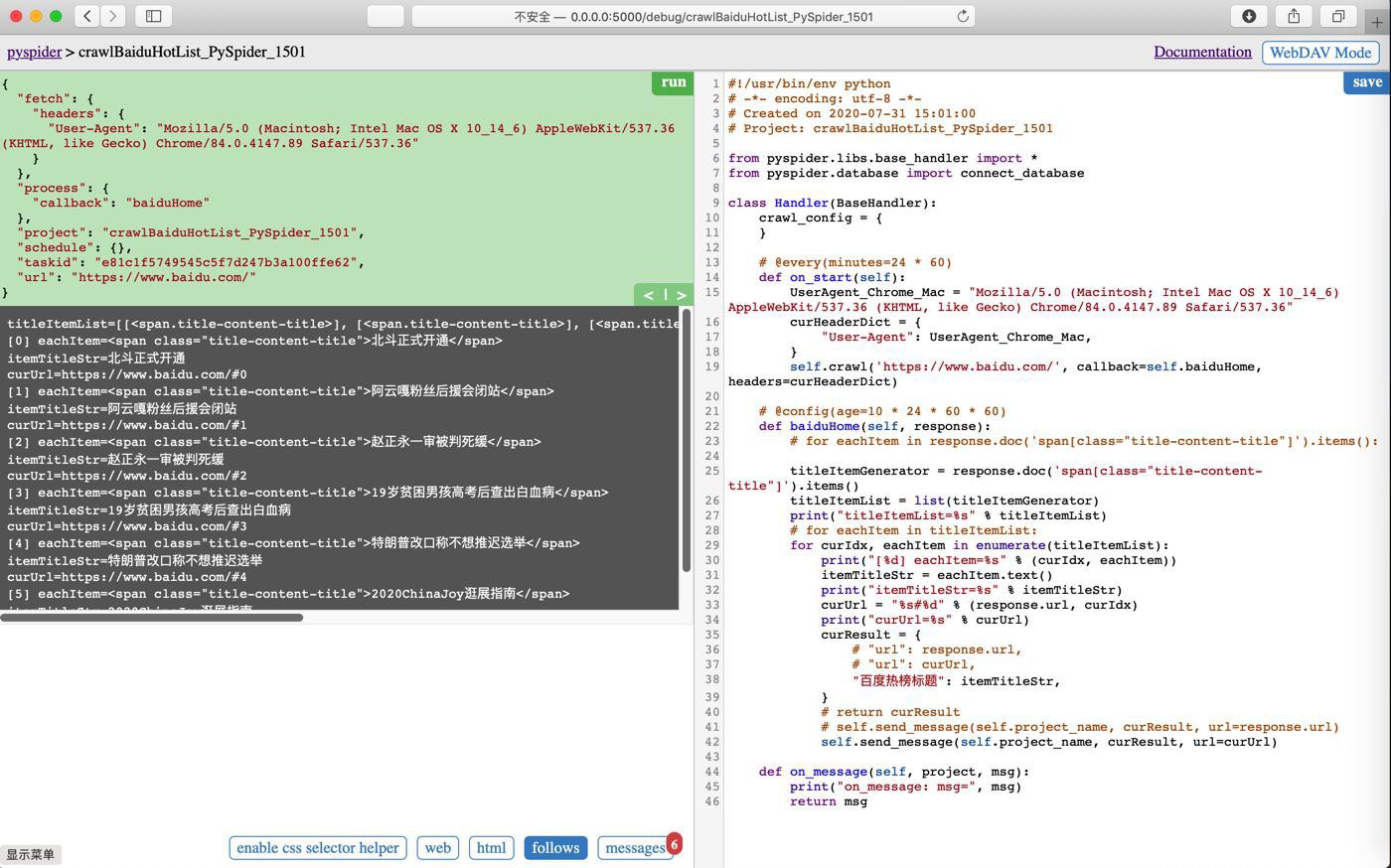
运行:
CSV:

预览效果:
即可。
【总结】
此处,单个页面的response处理函数中,想要返回多个结果
之前写法:
for eachItem in titleItemList:
print("eachItem=%s" % eachItem)
itemTitleStr = eachItem.text()
print("itemTitleStr=%s" % itemTitleStr)
return {
"百度热榜标题": itemTitleStr
}只能返回单个结果。
后来改为message方式:
curResult = {
"url": response.url,
"百度热榜标题": itemTitleStr,
}
# return curResult
self.send_message(self.project_name, curResult, url=response.url)
def on_message(self, project, msg):
print("on_message: msg=", msg)
return msg仍然只能返回单个项目
原因:url每次都是一样的,后续的由于url重复而导致被忽略,没有被保存下来
解决办法:确保每次url不同
方式之一:给url后面加上#xxx 其中xxx是任意值,确保不同即可。
常用做法,用循环的index或number
比如此处:
# for eachItem in titleItemList:
for curIdx, eachItem in enumerate(titleItemList):
print("[%d] eachItem=%s" % (curIdx, eachItem))
itemTitleStr = eachItem.text()
print("itemTitleStr=%s" % itemTitleStr)
curUrl = "%s#%d" % (response.url, curIdx)
print("curUrl=%s" % curUrl)
curResult = {
# "url": response.url,
# "url": curUrl,
"百度热榜标题": itemTitleStr,
}
# return curResult
# self.send_message(self.project_name, curResult, url=response.url)
self.send_message(self.project_name, curResult, url=curUrl)
def on_message(self, project, msg):
print("on_message: msg=", msg)
return msg确保了url不同,就可以保存出来了。
注意:
每次代码改动,按道理重新运行,即可产生新结果,但是貌似由于此处PySpider有bug了?
无论怎么尝试,都无法重新生成结果,最后无奈只能删除旧项目,重建新项目,才能得到最新结果。很是郁闷。