折腾:
期间,用代码:
class Handler(BaseHandler):
crawl_config = {
'headers': {
"Host": "www.xiaohuasheng.cn:83",
"User-Agent": UserAgentNoxAndroid,
"Content-Type": "application/json",
"userId": UserId,
# "userId": "1134723",
"Authorization": Authorization,
"timestamp": Timestamp,
"signature": Signature,
"cookie": "ASP.NET_SessionId=dxf3obxgn5t4w350xp3icgy0",
# "Cookie2": "$Version=1",
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"cache-control": "no-cache",
"Connection": "keep-alive",
# "content-length": "202",
},
}
def on_start(self):
# for debug
self.crawl("http://www.baidu.com")竟然死掉了:
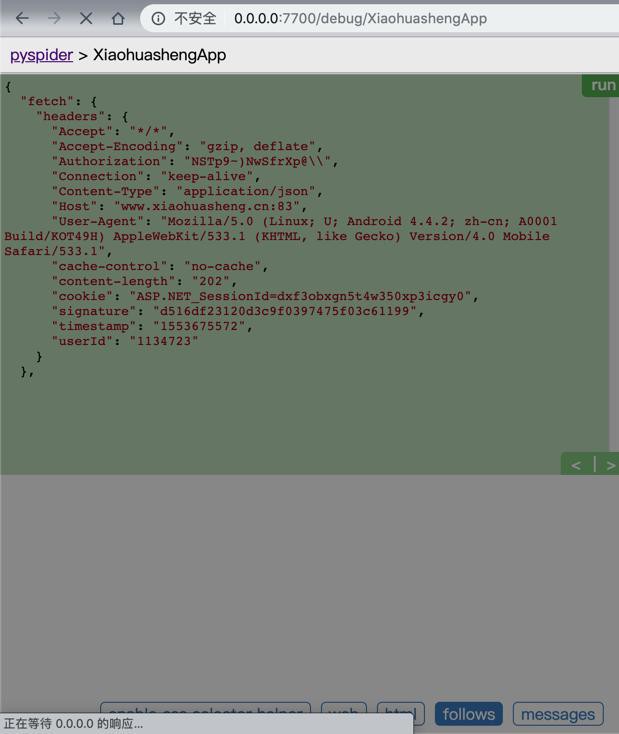
难道是执行了js导致很慢?那多等等
好像也不对,去掉:
# "content-length": "202",
结果可以返回了。
【总结】
此处PySpider中,由于之前调试其他问题,给headers加上了
"content-length": "202"
导致后续用普通的:
self.crawl("http://www.baidu.com")都无法正常返回,而挂掉,没有响应了。
解决办法:
去掉headers中的content-length即可。
不过又出现其他问题: