折腾:
【记录】爬取大众点评中的幼儿外语培训机构数据
期间,在多次调试大众点评页面时,偶尔发现页面无法获取数据:
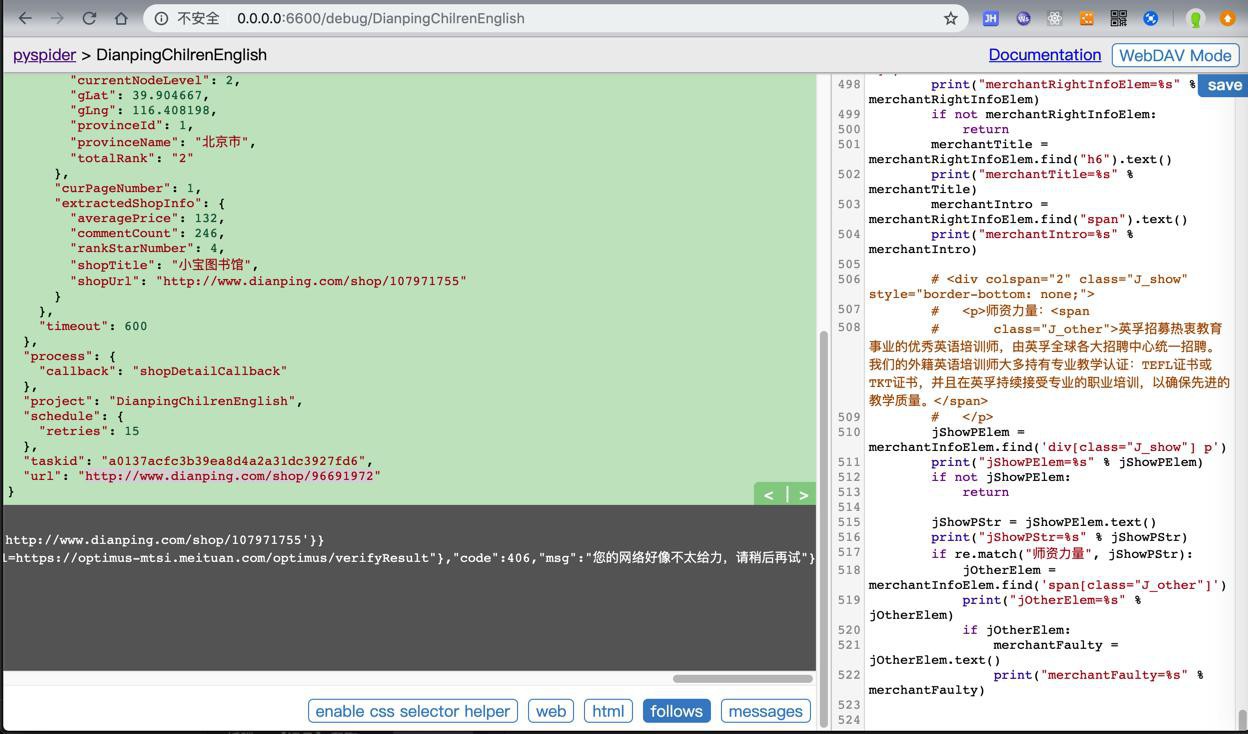
curInfo={'curMainCity': {'cityAbbrCode': 'BJ', 'cityAreaCode': '010', 'cityEnName': 'beijing', 'cityId': 2, 'cityLevel': 1, 'cityLevelFloat': 1, 'cityName': '北京', 'cityOrderId': 404, 'cityPyName': 'beijing', 'currentNodeLevel': 2, 'gLat': 39.904667, 'gLng': 116.408198, 'provinceId': 1, 'provinceName': '北京市', 'totalRank': '2'}, 'curPageNumber': 1, 'extractedShopInfo': {'averagePrice': 132, 'commentCount': 246, 'rankStarNumber': 4, 'shopTitle': '小宝图书馆', 'shopUrl': 'http://www.dianping.com/shop/107971755'}}
respText={"customData":{"requestCode":"590dfffd06284ebb9b25b7878312e0e7","verifyUrl":"https://optimus-mtsi.meituan.com/optimus/verify?request_code=590dfffd06284ebb9b25b7878312e0e7","imageUrl":"https://verify.meituan.com/v2/captcha?action=spiderindefence&request_code=590dfffd06284ebb9b25b7878312e0e7","verifyPageUrl":"https://verify.meituan.com/v2/app/general_page?action=spiderindefence&requestCode=590dfffd06284ebb9b25b7878312e0e7&platform=1000&adaptor=auto&succCallbackUrl=https://optimus-mtsi.meituan.com/optimus/verifyResult"},"code":406,"msg":"您的网络好像不太给力,请稍后再试"}之前不知道是什么原因。
后来发现了:是大众点评网站做了反扒措施了。
此时,再去用Chrome等浏览器打开
时,就会跳转到:
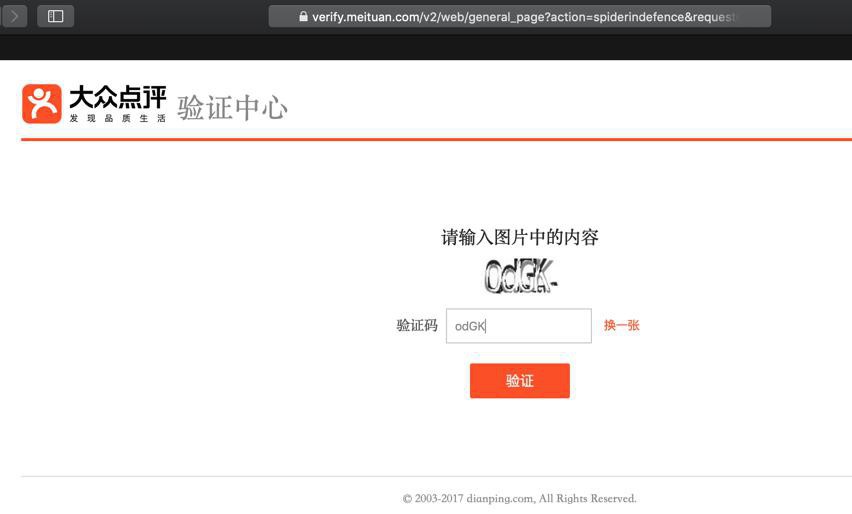
大众点评验证中心
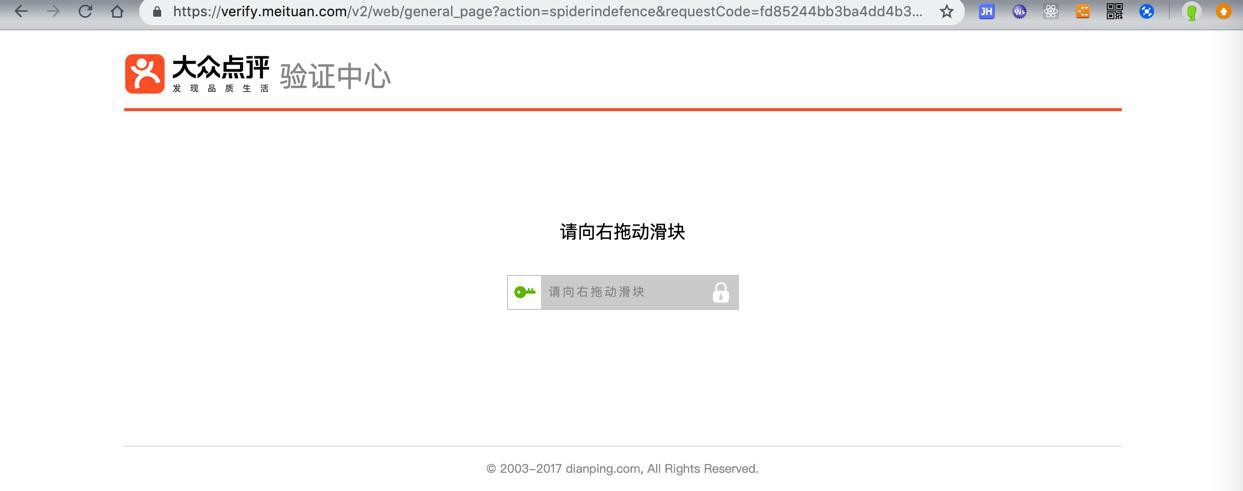
从url中的spiderindefence可以看出是:做了反扒措施
-》猜测:内部检测到,多次请求都来自同一个IP,且频率太高(或者内部参数不全,比如缺少cookie等情况)就会启用反扒,进入验证页面
-》只有人工拖动滑块后,(后记:有的是需要输入验证码)才能解锁进去正常页面
请向右拖动滑块
后记:
后来遇到其他类似的反扒现象:
返回的url是verify页面地址
比如:
尝试打开:
但是返回了:
https://verify.meituan.com/v2/web/general_page?action=spiderindefence&requestCode=eab31732585d4c09a7ae85b6082e1810&platform=1000&adaptor=auto&succCallbackUrl=https%3A%2F%2Foptimus-mtsi.meituan.com%2Foptimus%2FverifyResult%3ForiginUrl%3Dhttp%253A%252F%252Fwww.dianping.com%252Fshop%252F97388294&theme=dianping
总之:
大众点评
(现在和美团是一家了,所以verify地址用的是meituan.com)
有反扒机制
在触发后,要么是返回的内容是:
{"customData":{"requestCode":"590dfffd06284ebb9b25b7878312e0e7","verifyUrl":"https://optimus-mtsi.meituan.com/optimus/verify?request_code=590dfffd06284ebb9b25b7878312e0e7","imageUrl":"https://verify.meituan.com/v2/captcha?action=spiderindefence&request_code=590dfffd06284ebb9b25b7878312e0e7","verifyPageUrl":"https://verify.meituan.com/v2/app/general_page?action=spiderindefence&requestCode=590dfffd06284ebb9b25b7878312e0e7&platform=1000&adaptor=auto&succCallbackUrl=https://optimus-mtsi.meituan.com/optimus/verifyResult"},"code":406,"msg":"您的网络好像不太给力,请稍后再试"}要么是:
返回的url是,验证页面的地址
https://verify.meituan.com/v2/web/general_page?action=spiderindefence&requestCode=eab31732585d4c09a7ae85b6082e1810&platform=1000&adaptor=auto&succCallbackUrl=https%3A%2F%2Foptimus-mtsi.meituan.com%2Foptimus%2FverifyResult%3ForiginUrl%3Dhttp%253A%252F%252Fwww.dianping.com%252Fshop%252F97388294&theme=dianping
此时也是:
如果直接去打开希望的页面
比如:
也还是会跳转到验证页面。
输入验证码或拖动滑动后:
大众点评验证中心
请向右拖动滑块
或类似的:
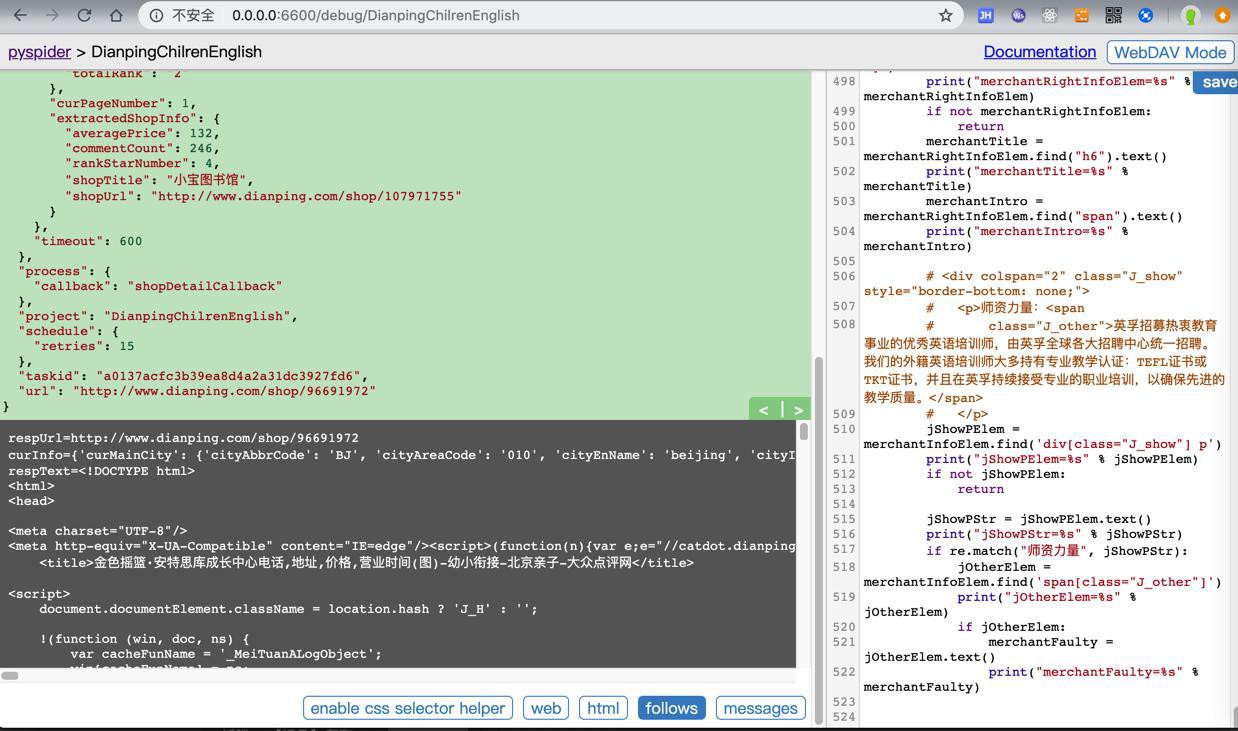
需要输入验证码:
才能解锁进入正常页面。
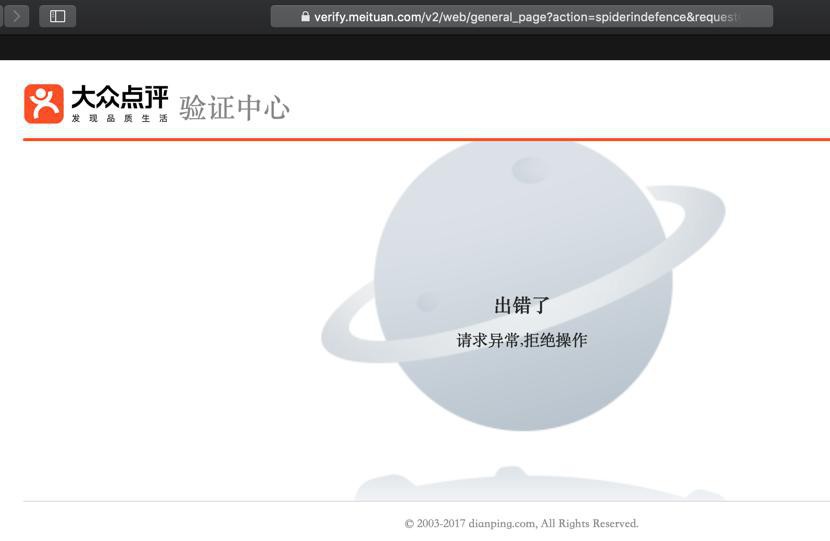
(甚至有时候,爬虫返回的验证页面去浏览器中都无法解锁会报错:
出错了
请求异常,拒绝操作
 )
)作为暂时的调试,是可以手动(输入验证码或滑动滑块去)解决,即可正常返回页面数据了:
-》不过代码中,及后续的批量去运行爬取页面,就需要去想办法,看看如何才能破解此问题,彻底解决这个问题
->目前想到的是:或许用IP代理,IP池?或许可以搞定?
大众点评 反扒 请向右拖动滑块
美团(类似于 大众点评) 也有这种 验证中心
大众点评 破解 请向右拖动滑块
很复杂,暂时还是想办法去弄 IP池 IP代理 吧
【已解决】找个好用的IP代理池实现防止大众点评网站的反扒
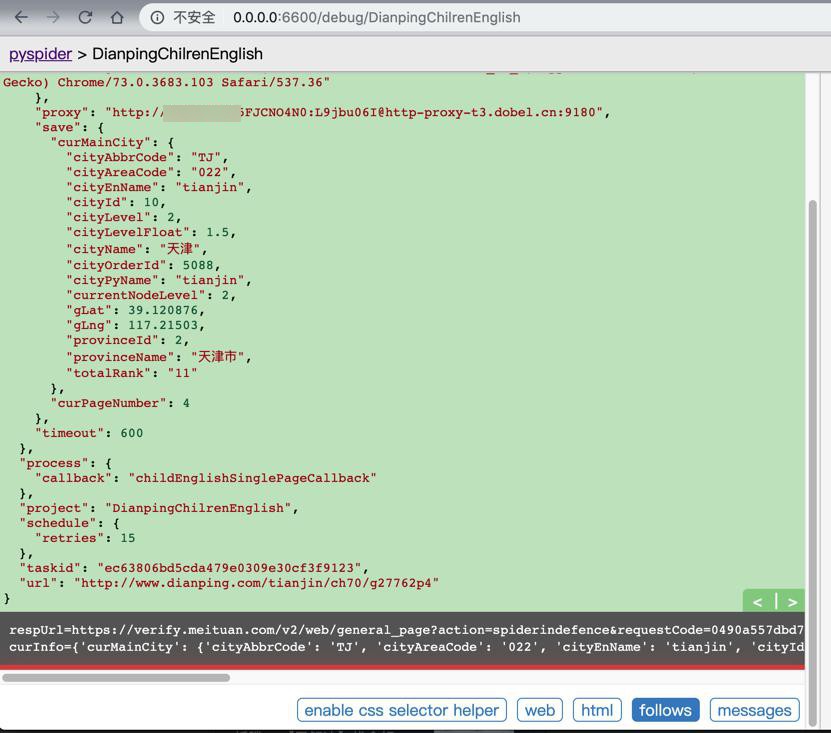
但是在公司的网络中,用了多贝云的IP代理了,调试没几次就又出现了:
respUrl=https://verify.meituan.com/
的问题:
然后继续试了试,感觉也不对。
继续回去找找,大众点评的反扒逻辑是什么
感觉好像不是,或不仅仅是IP限制的问题
毕竟已经用了IP代理池,每次请求(至少是每几次请求)是IP变化的,但还是会报错:
还是会返回
respUrl=https://verify.meituan.com/v2/web/general_page?action=spiderindefence&requestCode=9bab5b51e6444d13adce8a8181b60a2c&platform=1000&adaptor=auto&succCallbackUrl=https%3A%2F%2Foptimus-mtsi.meituan.com%2Foptimus%2FverifyResult%3ForiginUrl%3Dhttp%253A%252F%252Fwww.dianping.com%252Flangfang%252Fch70%252Fg27762p4&theme=dianping
再去看看cookie:
【未解决】PySpider中尝试设置Cookie避免大众点评的反扒
期间去禁止了cookie:
【已解决】PySpider中如何禁止cookie
期间再去:
【未解决】PySpider中尝试设置不同的header避免大众点评的反扒
截至此刻:
时不时的还会遇到verify问题,不过用了上面的
【已解决】PySpider中如何禁止cookie
触发反扒verify验证的问题,大大缓解
遇到了verify的话,重新debug请求一次,就可以获取内容了
对比之下,之前一直刷新多次都不行。
那继续调试看看效果,能否彻底规避掉verify的问题
把此处retry=15次,降低试试
crawl_config = {
"proxy": ProxyUri,
"connect_timeout": 100,
"timeout": 600,
# "retries": 15,结果问题依旧。
继续调试发现:
感觉是:
PySpider中,内部是用了多贝云的IP代理
但是还是经常,或时不时的出现反扒验证页面问题
至于原因,像是:
PySpider中内部调用代理的机制有啥特殊的?导致有时候IP没有更换
从而导致内反扒,无法获取页面内容
而偶尔的在PySpider的webui中刷新页面时,又可以了:估计就是IP更新成最新的了。
-》难道是:
多贝云的代理IP,IP刷新的效果有问题?
但是不像啊,因为http://httpbin.org/get测试每次IP都是刷新的了
那就像是:
PySpider中内部利用代理IP,有点未知原因的,导致IP没有每次都更换,导致时不时被禁止
而猜测是这个原因是:
内部用
http://httpbin.org/get
去测试,确认的确更换IP后
再去PySpider中测试,结果就可以正常消除verify页面了。
所以现在:
- 要么再去换个,每次请求IP都变化的
- 比如 之前的 阿布云
- 要么继续搞清楚
- 是否存在:PySpider中利用多贝云代理IP时,有时候IP是没有更换
- 如果存在,原因是啥
后来又试了试,好像又不是这个原因:
虽然切回去换了IP,但是还是verify页面
不过此处再去运行:
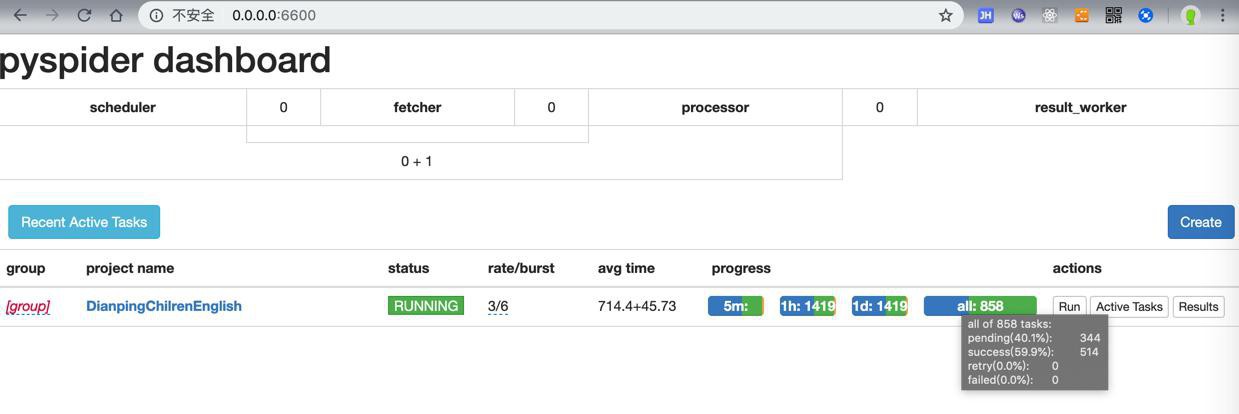
竟然,还是可以获取到不少页面的数据的:
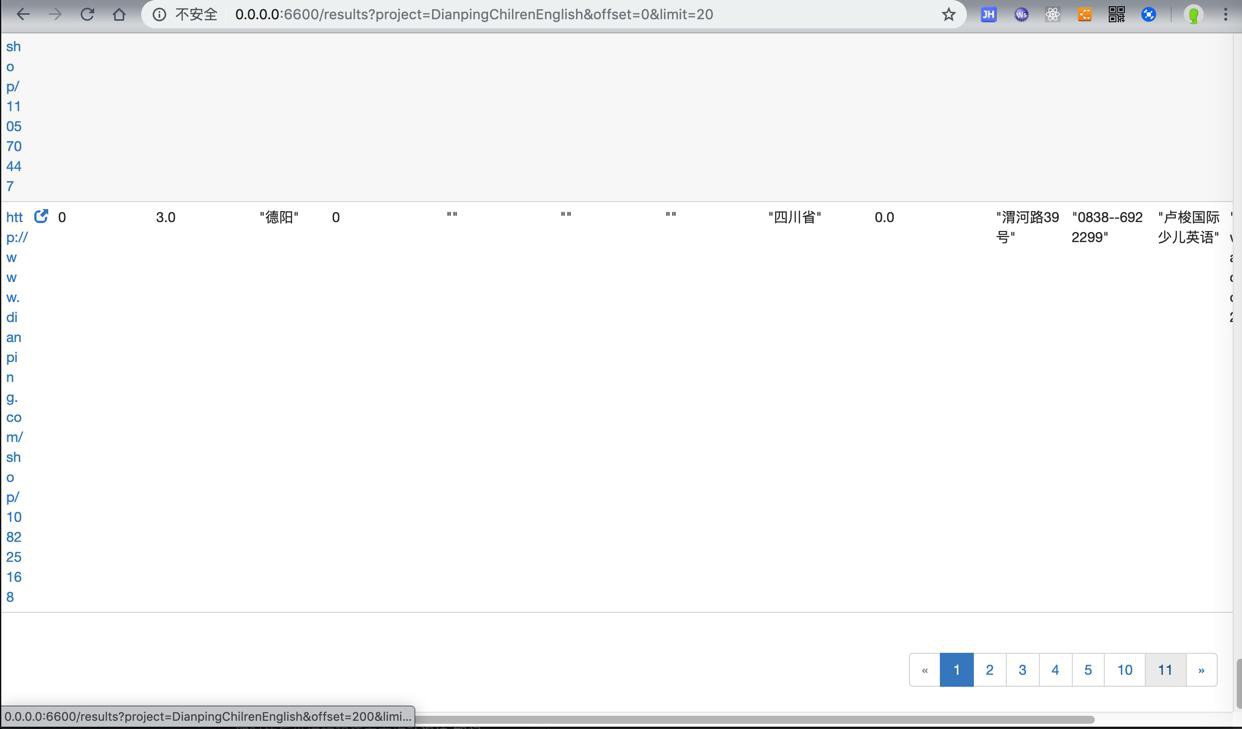
此处已经是11页=11×20=220个 结果
然后好像就可以接着继续运行了。
不过公司网络不太好,偶尔会出错retry:
抽空带回去用家里网络去下载试试
另外对于:
“在分页页面和详细页面点评都做了反爬,都是通过css来控制一些字和中文的显示”
我此处没有遇到
>直接可有从html解析到正常的数据
-》其帖子是2018年12月,现在是2019年4月,过了半年了
的验证机制了?
-》总之:该贴对破解,虽然关系很密切,但是帮助不大
倒是看到,对于其他类型的shop地址:
request的headers中,除了cookie是之前带上的,其他倒是没啥特殊的参数了
-》说明之前自己写的header,就是够用的了,没啥问题的。
-》如果需要cookie,那也是第一次访问之后才有的
-》而第一次,按逻辑上,是没有cookie的才对
-》所以后续可以正常工作的代码中,是不需要有cookie的
后来,用公司的网络去运行PySpider去下载,结果是可以获取到部分数据的。
担心公司网络和之前一样慢又容易出错,所以换到家里网络,是可以下载到1200左右个shop数据的。
然后回来公司增加出错保存机制,再去公司网络运行,结果全是出错:
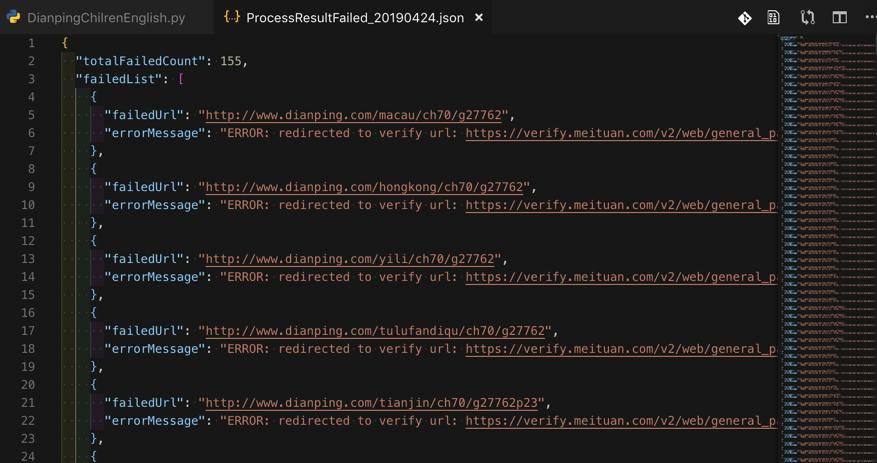
一点都没保存下来数据-》Results全是空:

看来还是抽空再回家下载看看吧
- 希望可以正常重新下载数据
- 万一出错了,也能从错误文件中找到原因
- 担心和之前一样,显示完成了,实际没完全
- 运行完成后,显示没有进展后,先STOP,再RUNNING,往往还能继续下载很多数据的
昨晚回家下载结果:
- 下载数据:63页
- 失败数:1862
PySpider的log中有些错误,去看看:
[W 190424 23:03:44 tornado_fetcher:423] [504] DianpingChildrenEnglish:5ebd6a44d695a2a80d4cfb8d3c12ce71 http://www.dianping.com/shop/93919897 14.97s
[E 190424 23:03:44 processor:202] process DianpingChildrenEnglish:5ebd6a44d695a2a80d4cfb8d3c12ce71 http://www.dianping.com/shop/93919897 -> [504] len:93 -> result:None fol:0 msg:0 err:HTTPError('HTTP 504: Gateway Timeout',)
[W 190424 23:04:29 tornado_fetcher:423] [403] DianpingChildrenEnglish:f568a48bff09959696734aa0d7b14fac http://www.dianping.com/shop/16672987 0.21s
[E 190424 23:04:29 processor:202] process DianpingChildrenEnglish:f568a48bff09959696734aa0d7b14fac http://www.dianping.com/shop/16672987 -> [403] len:7801 -> result:None fol:0 msg:0 err:HTTPError('HTTP 403: Forbidden',)没啥好办法能避免这些错误。
【部分解决】写代码继续下载之前PySpider运行期间被反扒的失败的数据
后来又去下载了几次,大概多了可以下载到50~60页的数据-》1000~1200条数据:
经过多次用家里网络下载,发现个现象:
虽然可以下载到部分数据,但是每次基本都是:
只能下载到一半左右的数据
比如共有
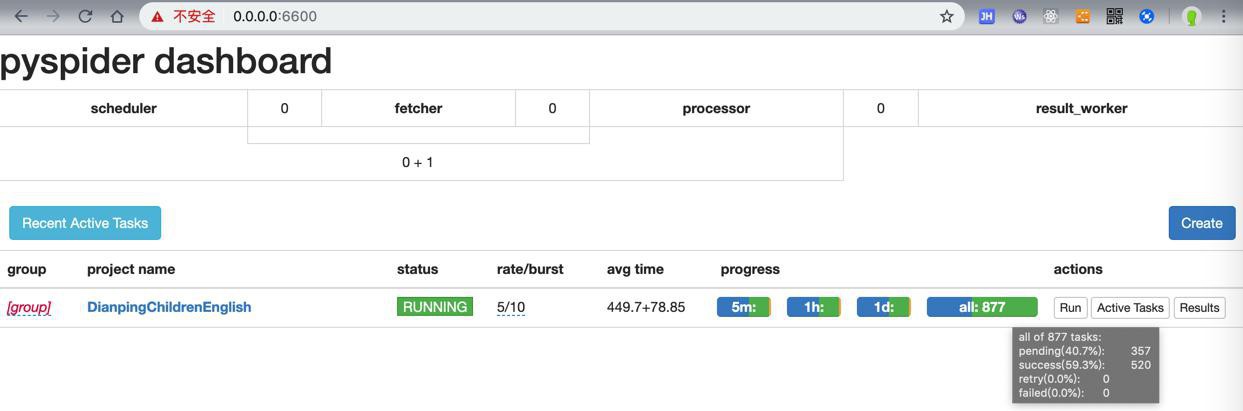
520个成功请求
520/2=260
260/20=13页左右的results
而此时是10页左右
而之前几次的最终结果大概都是:
3200左右的成功请求
下载到了60页左右的数据
差不多是总体一半的效果
所以:
- 要么是PySpider中内部发送代理有问题
- 导致不是每次请求IP都变化
- 要么是此处代理IP效果不够好
- 并发多个请求时,不是每次IP都变化
- 但是之前也试过每秒只请求1次,结果好像也是有问题
然后就是去:
【记录】写代码合并之前PySpider下载的部分的大众点评的数据
因为公司网络有问题,PySpider显示请求正常,但是完全下载不到数据。
所以还需要之后的,回去家里下载,然后合并下载的部分数据。
TODO:
- 回家后,去掉”Connection”: “keep-alive”,看看是否可以完全消除或部分缓解 被反扒的几率
- 回家后,用待会去新买的阿布云代理,试试代理效果是否如何
- 是否配合此处PySpider使用的效果能不能更好,被反扒几率更低些?
那此处先去买阿布云的IP代理:
【记录】购买阿布云的每次请求IP都不同的动态IP代理
那暂时不不购买,暂时用4小时内有效的测试账号。
现在去PySpider中测试,是否可以每次请求IP不同的:
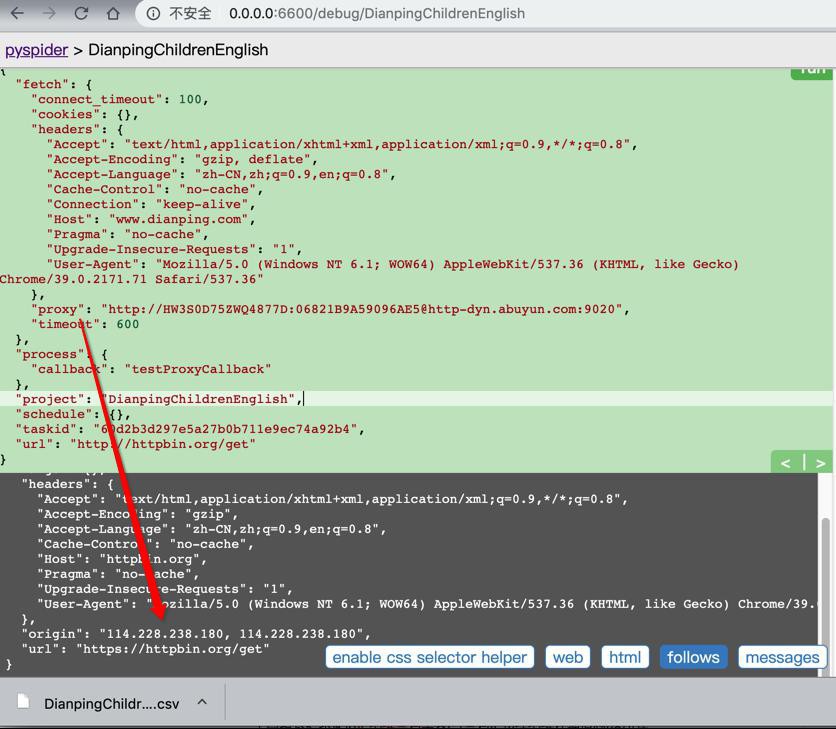
注意:此处是,容易出错的公司的网络
真的下载,要等到回家用家里网络
继续调试下载如何:
PySpider中阿布云的调试效果和之前多贝云的类似:
每次请求,往往会被反扒
但是刷新一次或几次,往往又可以下载了
-》像是内部IP没有变化
-》估计是PySpider的内部机制问题
-》估计是keep-alive的问题导致IP没有更换?
-》那去掉:
“Connection”: “keep-alive”,
试试,结果
不过先去:
【已解决】HTTP中如何设置连接Connection为不保持不是keep-alive
-》此处应该是http 1.1,然后此处需要设置:
Connection: close
才能强制关闭连接保持
-》或许就能确保每次IP不同了?
去用:
# "Connection": "keep-alive", "Connection": "close",
试试能否确保每次都不触发反扒了?
结果:被反扒几率没啥变化,还是调试期间还会出报错
甚至也还会偶尔403
requests.exceptions.HTTPError: HTTP 403: Forbidden
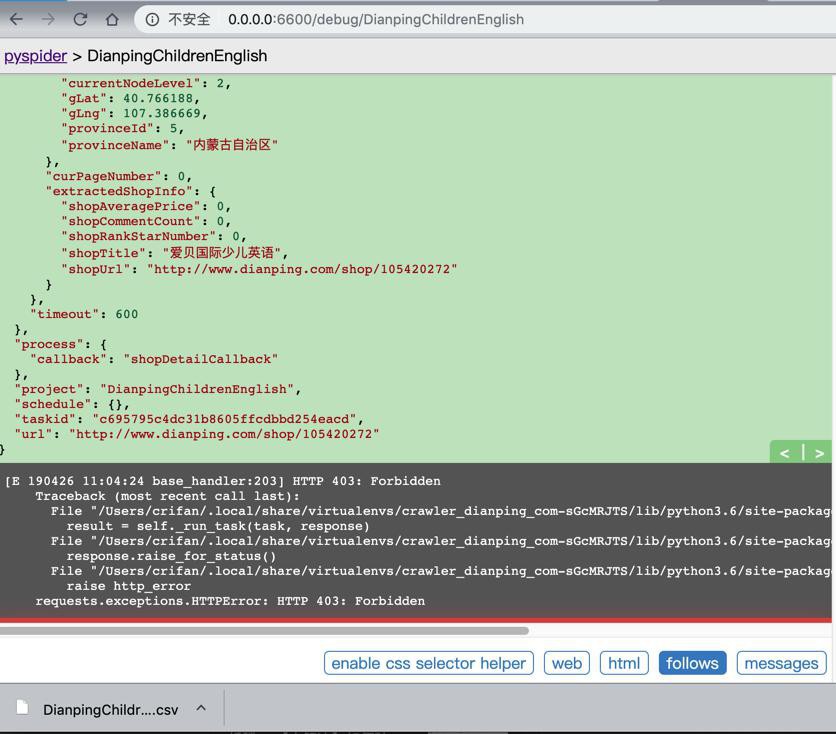
-》即:
此处公司网络中,即使确保连接不保持:
# "Connection": "keep-alive", "Connection": "close",
也还是会被反扒,甚至出现403(之前调试很少出现)
-》不知道用家里网络下载,效果是否能改善
不过现在用公司网络也去试试批量运行,能否下载到数据
此处效果很不错啊:
之前多贝云在公司网络,都无法下载到数据的
此处,阿布云+去掉保持连接,在公司网络下,可以下载到数据
成功率也是和 多贝云+保持连接+家里网络 是差不多的:50% 左右
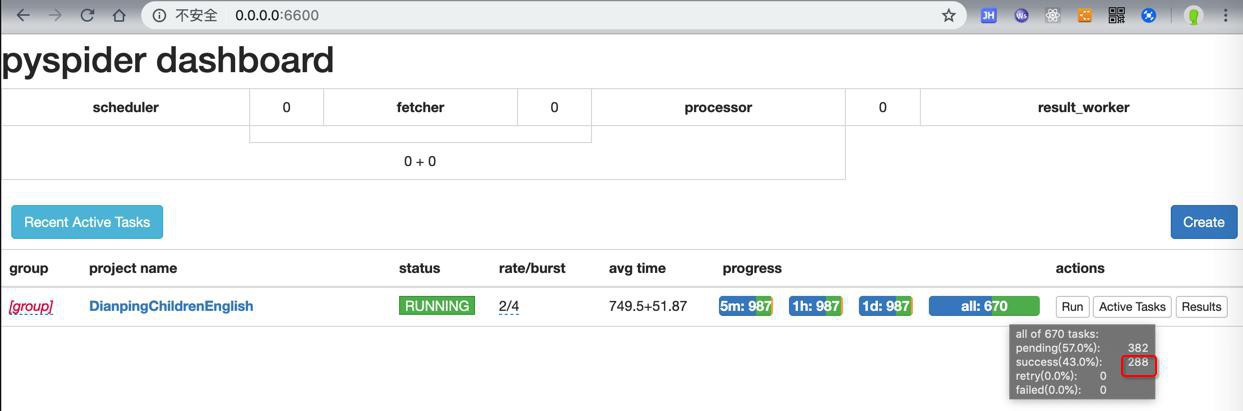
288的成功的
对应
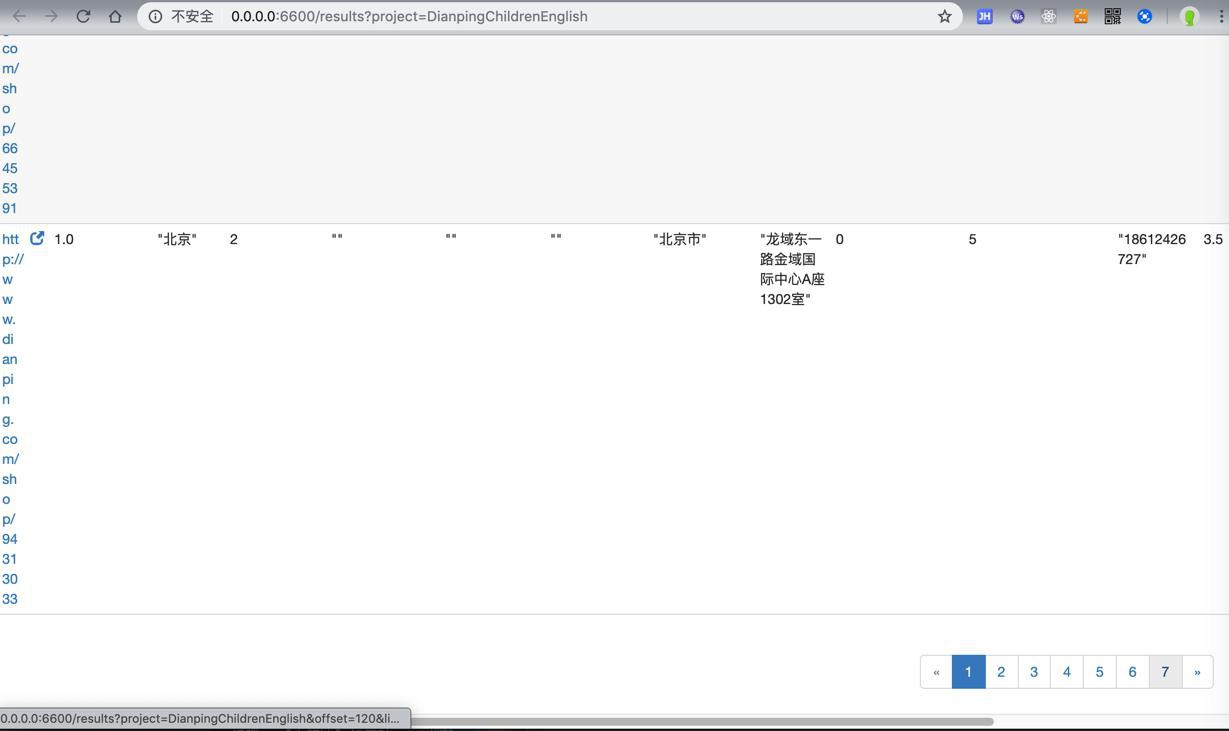
7页数据=7×20=140个数据
-》140/288=差不多也是50%=一半的成功率
截至目前:
从
不论是多贝云还是阿布云,PySpider中调试都会出现被反扒
很怀疑是:
不同请求时,IP没变化,而导致的
怀疑是PySpider的内部调试的逻辑导致的
所以抽空再去找找:
PySpider中如何确保每次请求,和之前请求没有关联,以便于(在用了动态IP代理情况下)每次不同请求的IP是变化的
然后:
- 已买阿布云的代理IP + connection为close + 家里网络下载
- 效果类似:也还是50%左右的成功率
- 大概下了50多页数据 -》1000多个
- 合并后,有效的是400多个
- 还有40%左右是之前没爬过的
- 看来还剩很多数据啊
看来需要继续想办法,看看如何完整下载
否则这么一点点的合并数据,也不是个办法
期间考虑过:如果实在不行,再换用备用方案:备用方案:
PySpider中如何使用Selenium实现绕开爬虫限制
而此处希望在PySpider中使用Selenium
PySpider selenium
-》但是后来想到了:
换用Selenium,只能实现模拟浏览器访问到页面,
但还是没法绕过IP限制
且现在通过前面措施已经开始可以获取到页面了
只是同一个IP多次访问被反扒了
所以换用Selenium也没用。放弃这个考虑。
然后去想办法实现之前就有考虑的:
【已解决】PySpider中当大众点评反扒时重新爬取希望获取到所有数据
总体效果还是不错的。
截至目前,运行了2次,每次都是爬取500多页数据,基本够用。
如果还不够,再抽空用家里网络,重新下载。
然后再去合并结果,即可。
期间如果阿布云账号过期,还会提示需要付款:
[W 190502 10:04:59 tornado_fetcher:423] [402] DianpingChildrenEnglish:03d7573282446a107bf426f38e30f406 http://www.dianping.com/shop/98532606#221048_745240 0.06s
[E 190502 10:04:59 processor:202] process DianpingChildrenEnglish:03d7573282446a107bf426f38e30f406 http://www.dianping.com/shop/98532606#221048_745240 -> [402] len:312 -> result:None fol:0 msg:0 err:HTTPError('HTTP 402: Payment Required',)最后是用家里网络下载了几次,每次都是超过500页。
最后再去合并得到最终的13000+的shop信息。
最终的配置,看起来是:
- 确保网络是好的
- 用自家的网络(比公司的好)
- 用了代理:阿布云的IP代理
- 确保每次IP变化
- connection为close
- 从 “Connection”: “keep-alive” 改为 “Connection”: “close”
- 清空cookie
- PySpider全局的crawl_config中:cookies={}
- 降低爬取频率
- 从 3/8 降低到 2/6
- 减少被反扒概率
最终:
可以成功爬取到1.3万多页数据。