折腾:
【未解决】如何破解大众点评网页爬取时的反扒验证verify.meituan.com
期间,现在只能去:
多次爬取,获得部分数据,然后去合并结果。
效率很低,且不能保证获取到完整的所有的数据。
现在继续想办法,看看能不能获取到完整数据。
考虑:
- 去当发现被反扒了,就再去重新爬取
- 给url后面加上#timestamp
- 强制重新爬取
- 再被反扒,再强制重新爬取,如此反复
- 看看最后能正常爬取多少
- 希望能获取到所有数据
写了代码,去测试效果:
对于出现被反扒验证时
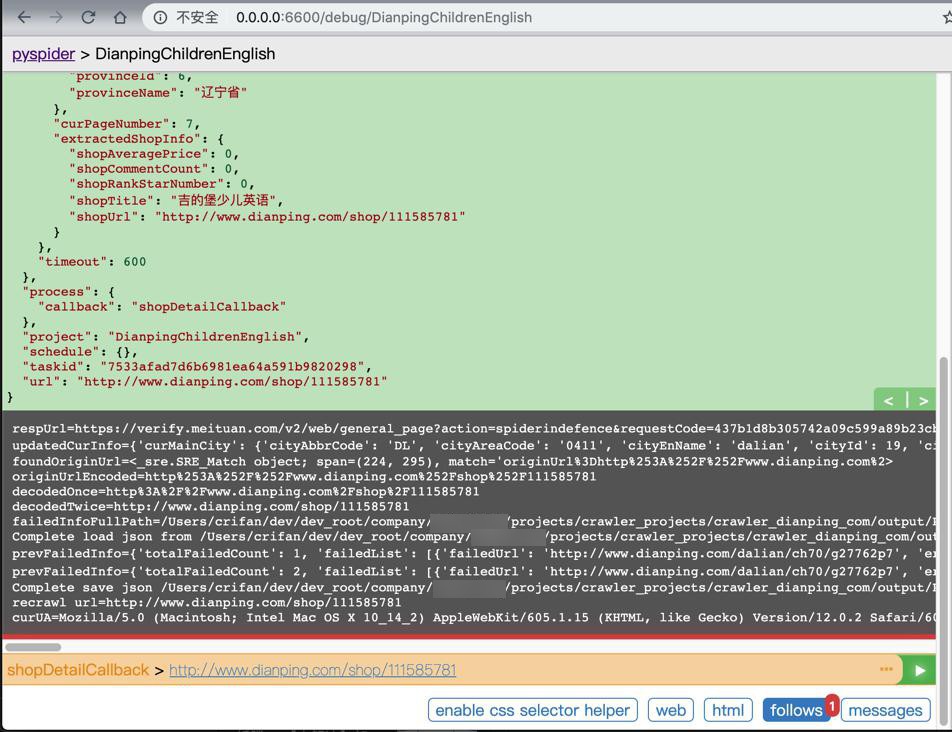
重新去爬一次
有时候还是会被反扒
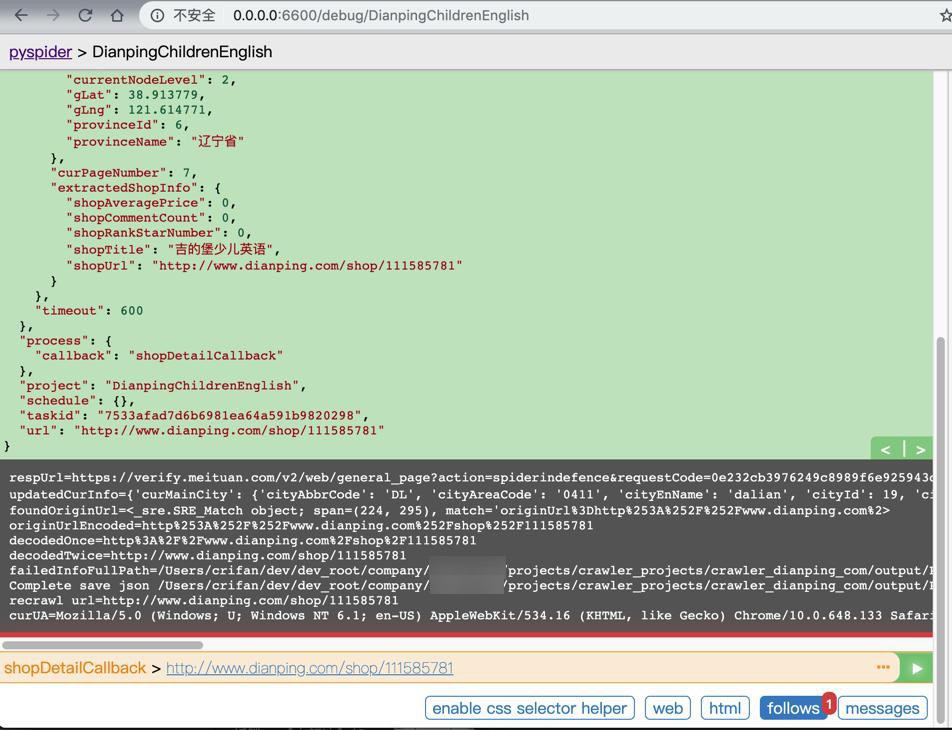
有时候可以正常获取数据
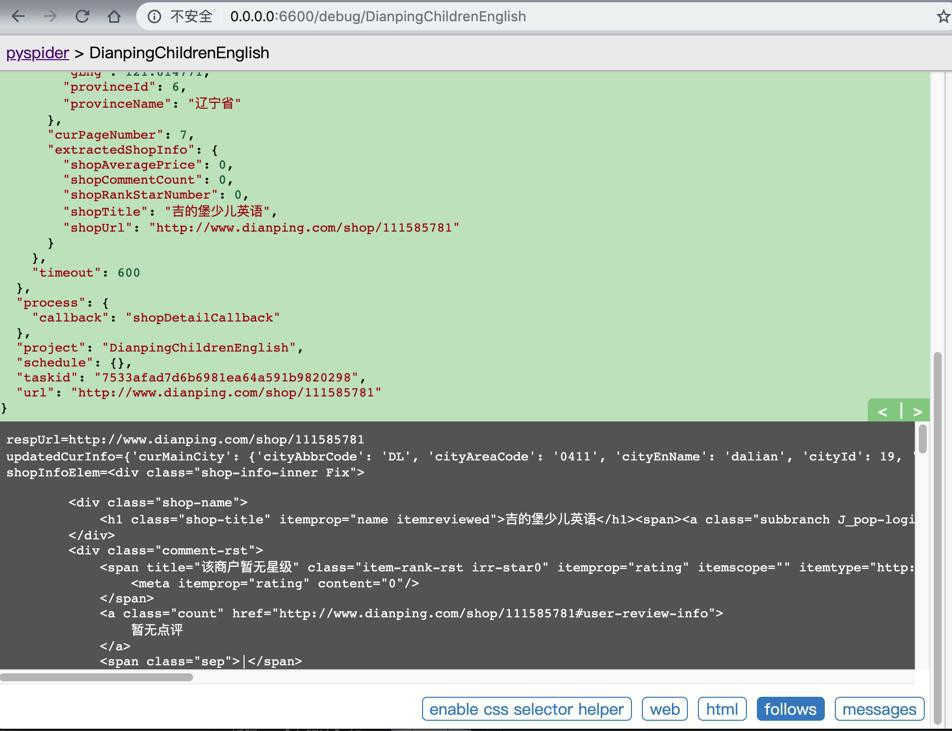
猜测:这时候,内部IP变化了,就可以正常获取数据了。
然后去批量爬取数据,看看重爬的效果如何。
不过,在url加上了hash后:
def childEnglishEntryCallback(self, response):
respUrl = response.url
print("respUrl=%s" % respUrl)
curMainCity = response.save
print("curMainCity=%s" % curMainCity)
if self.foundFailedAndSaveAndRecrawl(response, curMainCity, self.childEnglishEntryCallback):
return
def foundFailedAndSaveAndRecrawl(self, response, curInfo, recrawlCallback):
# check if found failed
isGetFailed, errorMessage, failedUrl = self.isGetContentFailed(response)
if isGetFailed:
# if found, then save failed
failedItem = {
"failedUrl": failedUrl,
"errorMessage": errorMessage,
"curInfo": curInfo,
}
self.saveFailedItem(failedItem)
# add hash value for url to force re-crawl when url is same
timestampStr = datetime.now().strftime("%H%M%S_%f") # 154134_660436
failedUrlWithHash = failedUrl + "#" + timestampStr
# re-crawl
print("recrawl failedUrlWithHash=%s" % failedUrlWithHash)
self.crawl(
failedUrlWithHash,
headers=self.genCurHeaders(),
cookies={},
save=curInfo,
callback=recrawlCallback,
)
return isGetFailed继续调试看看。
反扒后,去重爬:
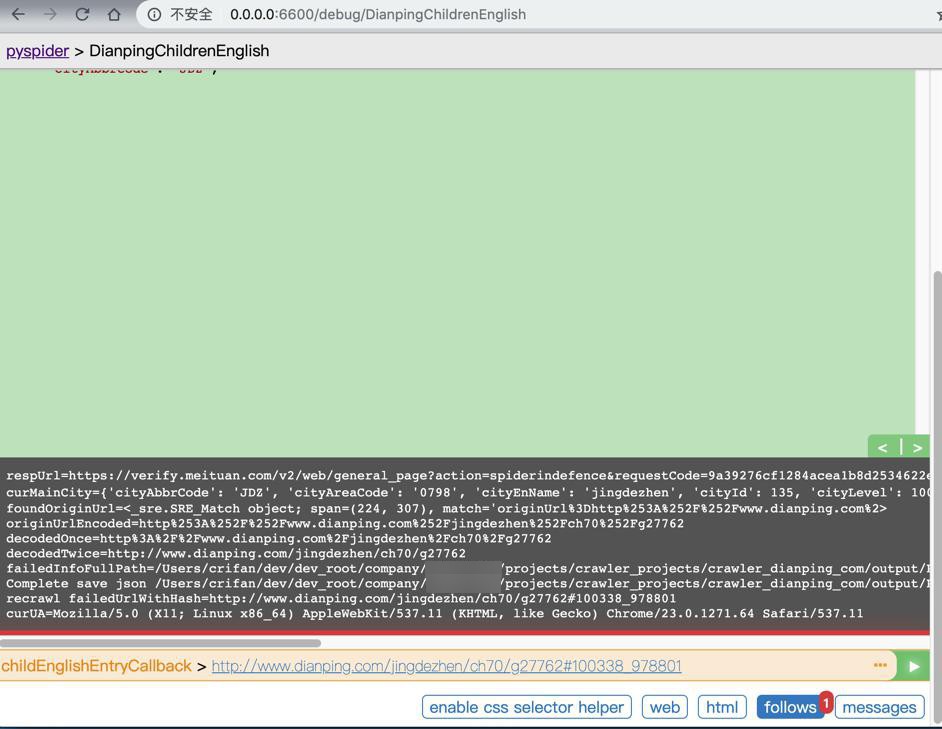
正常获取了:
又被反扒了:
还是被反扒:
经过几次重爬,是可以正常获取内容的:
嗯,可以去批量爬取试试了。
之前正常paqe爬取,总体共大概3000多的成功的url
现在带了重爬,对于出错的有1500+的url,重爬后,总体url成功总数,至少在4500+以上才对。
到时候看看结果是否是希望的。
结果竟然比平时还少,只有1600+
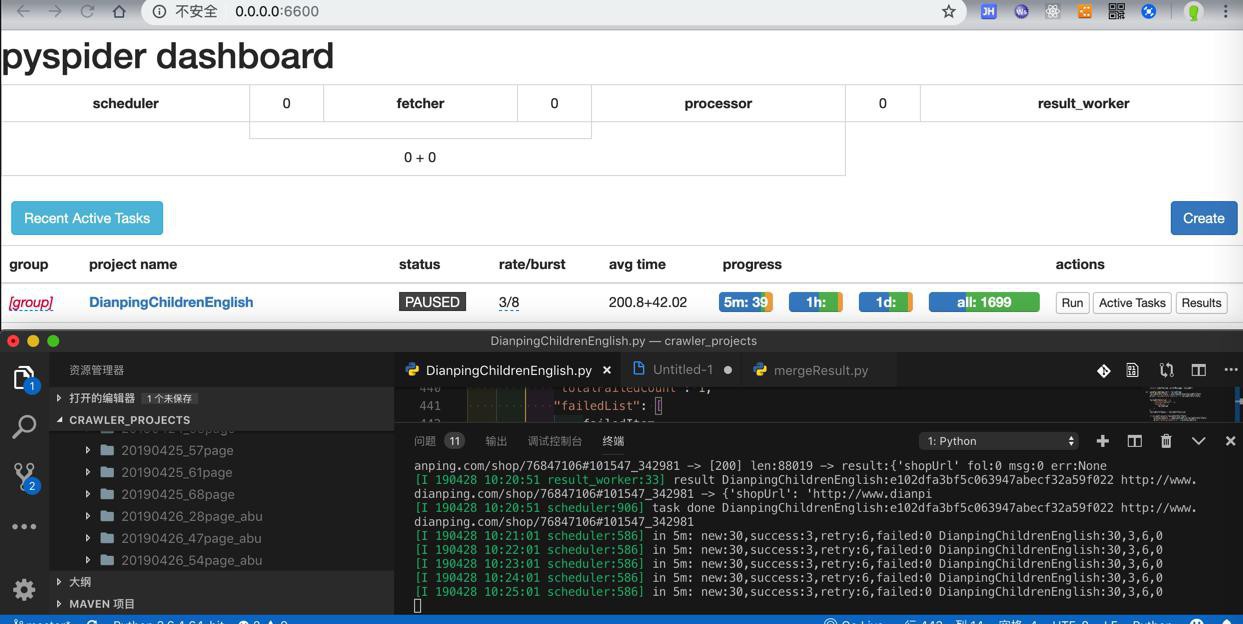
爬到数据也只有28页(之前都60+页)
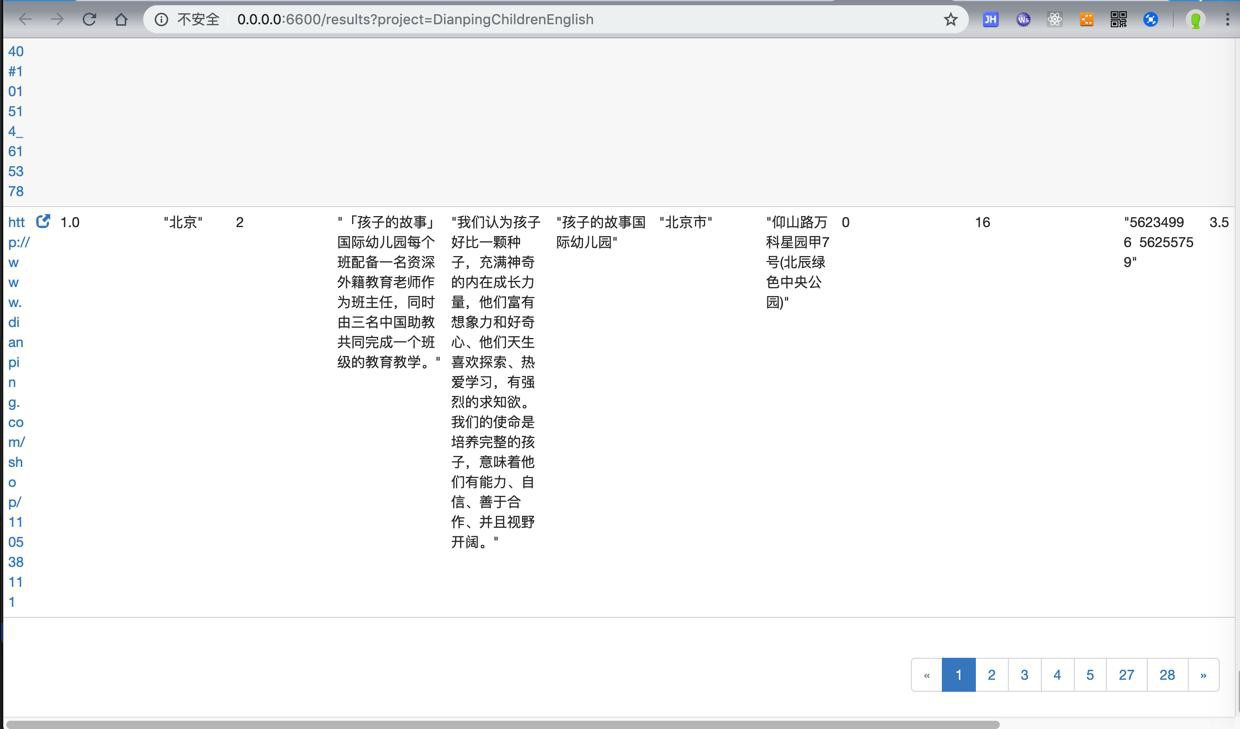
很是郁闷。
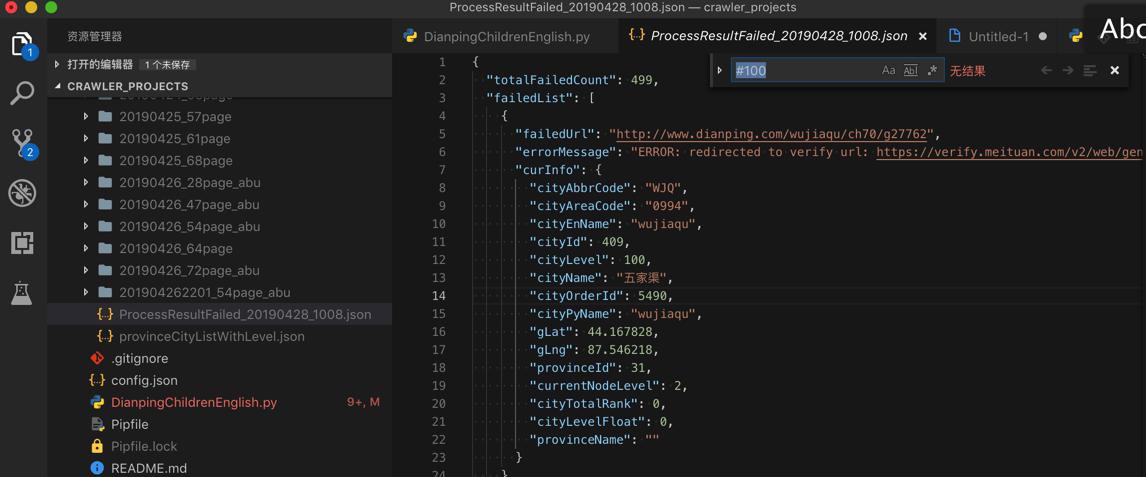
连failed的url,都很少,只有499个
-》之前一般有1500+个
需要去搞清楚原因
或者,还是公司网络问题?那抽空回家用家里网络下载试试?
再去重新试试。
此处,也是运行到3000多就PAUSED(估计是公司网络不够好,retry太多而PAUSED了)
再去STOP后再RUNNING,可以继续运行了。
先后弄了几次:

现已下载到7000+请求,150页数据了。
继续STOP后再RUNNING,看看最终能下载多少数据
感觉还是回家用家里网络下载,估计效果会更好
期间,还遇到:
[W 190428 15:57:41 tornado_fetcher:423] [429] DianpingChildrenEnglish:a9c879ae60eb6f61ac57ddde83a36741 http://www.dianping.com/shop/106637439 0.09s
[E 190428 15:57:41 processor:202] process DianpingChildrenEnglish:a9c879ae60eb6f61ac57ddde83a36741 http://www.dianping.com/shop/106637439 -> [429] len:267 -> result:None fol:0 msg:0 err:HTTPError('HTTP 429: Too Many Requests',)难道是:
超过代理IP的限制了?
那再去降低一些,从:
3/8
改为:
2/6
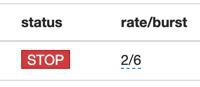
果然还真的可以继续下载了:
其中的部分url,比如:
http://www.dianping.com/shop/112051912#160051_178689 http://www.dianping.com/shop/18025820#160059_450046
就是我们希望的,重爬的url
但是很快就又卡死停住了,无法继续了:
出现了403:
[W 190428 16:01:05 tornado_fetcher:423] [403] DianpingChildrenEnglish:1392ffeb21f4f3c2eb5004de2e193f66 http://www.dianping.com/shop/83490716 0.15s
[E 190428 16:01:05 processor:202] process DianpingChildrenEnglish:1392ffeb21f4f3c2eb5004de2e193f66 http://www.dianping.com/shop/83490716 -> [403] len:0 -> result:None fol:0 msg:0 err:HTTPError('HTTP 403: Forbidden',)
还是抽空回家用家里网络下载吧,估计效果会不错
结果也还是经常403和出错,无法顺利大批量下载。
然后再去升级了最大请求数到10=5+5
结果:公司网络下载,还是会经常出错。
抽空:回去家里,完全重新开始下载,看看效果如何:能不能顺利批量下载。
然后回去家里,结果下载了一夜,下载到10000+url,200多页数据。
然后继续下载,也是可以下载到500多页数据的,效果还是可以的
虽然也还是会PAUSED,然后继续重试,
但至少比之前每次下载个50页左右,效率要高很多。