折腾:
【未解决】如何破解大众点评网页爬取时的反扒验证verify.meituan.com
期间,在页面报错后,重新清空再试,也还是没有cookie
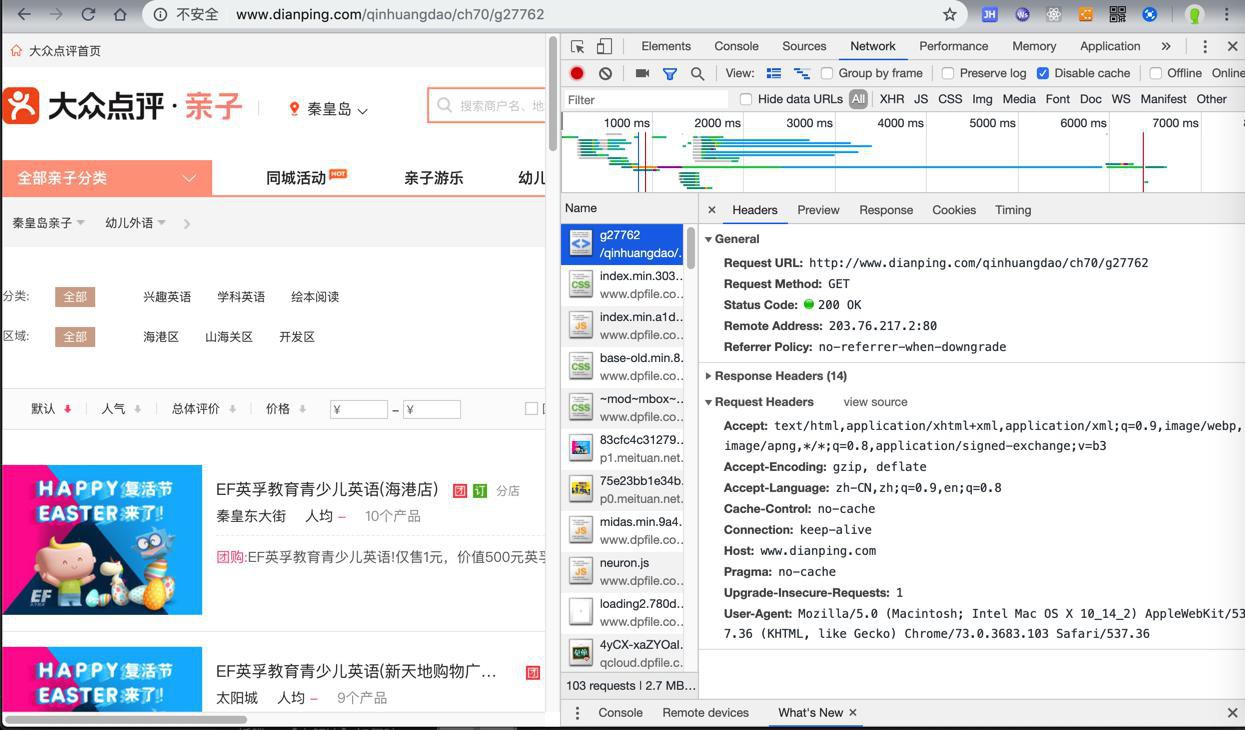
但是看到很多header:
把上面的header都加进来:
constUserAgentMacChrome = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
class Handler(BaseHandler):
crawl_config = {
"proxy": ProxyUri,
"connect_timeout": 100,
"timeout": 600,
"retries": 15,
"headers": {
# "Accept": "application/json, text/javascript, */*; q=0.01",
# "Accept": "application/json, text/javascript, text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*; q=0.8,application/signed-exchange;v=b3",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Host": "
www.dianping.com
",
"Pragma": "no-cache",
"Upgrade-Insecure-Requests": "1",
"User-Agent": constUserAgentMacChrome,
# "Content-Type": "application/json",
# "Origin": "
http://www.dianping.com
",
# "Cookie": "_lxsdk_cuid=16a200a8282c8-055d7d49cf2d47-12316d51-fa000-16a200a8282c8; _lxsdk=16a200a8282c8-055d7d49cf2d47-12316d51-fa000-16a200a8282c8; _hc.v=f301d625-2322-83f6-b7f0-4686373a858b.1555315721; aburl=1; Hm_lvt_dbeeb675516927da776beeb1d9802bd4=1555386214; wed_user_path=33780|0; cy=509; cye=wangdu; Hm_lpvt_dbeeb675516927da776beeb1d9802bd4=1555484470; _lxsdk_s=16a29fd395b-0ac-21b-f2%7C%7C34",
# "X-Requested-With": "XMLHttpRequest",
}
}测了几个页面,暂时可以正常访问了:
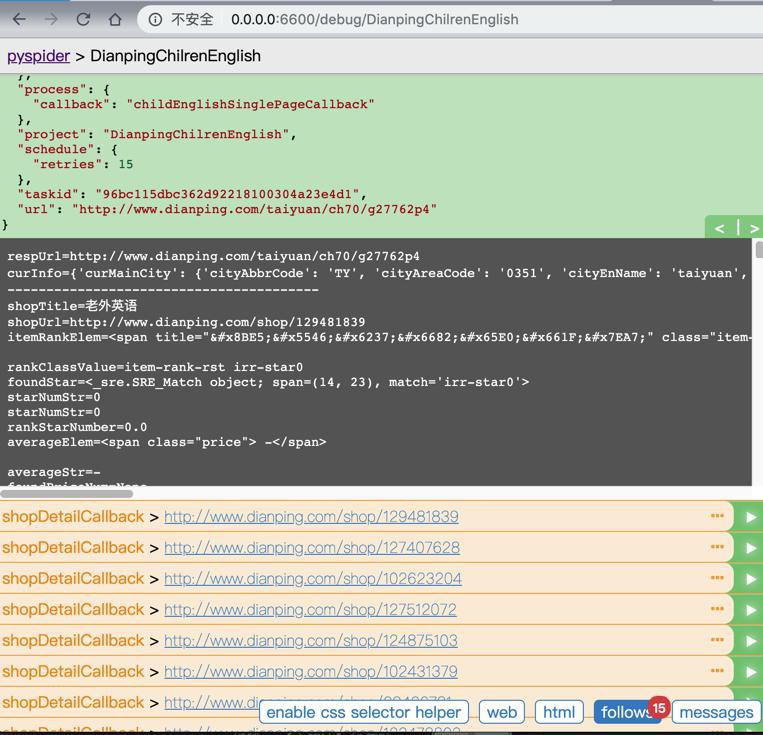
继续多测测,看看是否还会被反扒跳转验证
结果向上返回后,再去访问,就出错了,出现反扒了
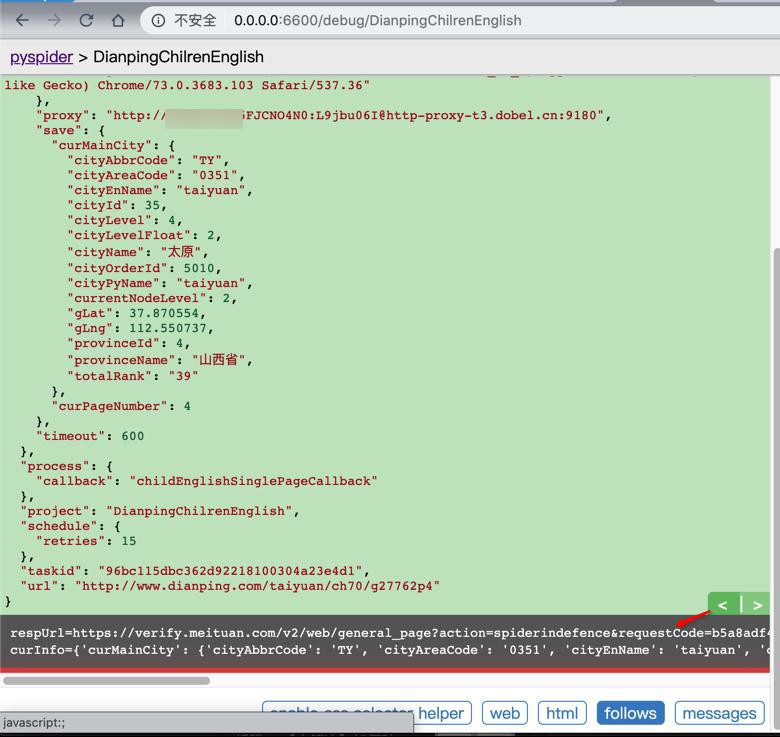
再去debug一次,又可以了。
然后后来又出现了。。
还是再去加上之前的cookie试试
算了。
“还不如搞个代理池(网上的免费代理基本没啥用,后面也用Tor+polipo搭了个代理网络),目的也是为了学习爬虫一些基础知识而已,这座大山也没翻过去(有翻过去的大大给点提示)。”
->看来美团和点评的这个反扒还是比较有效的
爬虫工程师如何绕过验证码?寻找阿登高地之路
那再去把随机的ua加进去:
【已解决】PySpider中实现每次请求使用随机的User-Agent
结果实现了随机UA,但是没过一会就还是触发反扒。
把headers中的
“Connection”: “keep-alive”,
去掉试试
因为记得好像说是影响每次请求都更换IP
问题依旧:
PySpider中调试时,多次请求IP都还是一样
重新进入后,有时候才能换IP。