折腾:
【已解决】找个好用的IP代理池实现防止大众点评网站的反扒
期间,已经用代码测试了代理IP,的确可以实现我们要的
每次请求,都会变IP
然后接着就是去PySpider中,试试实际使用的效果了
看看能否能够实现绕过大众点评的反扒,从而正常下载数据
先去看看PySpider的self.crawl如何传递代理参数
“proxy
proxy server of username:password@hostname:port to use, only http proxy is supported currently.
class Handler(BaseHandler):
crawl_config = {
‘proxy’: ‘localhost:8080’
}
Handler.crawl_config can be used with proxy to set a proxy for whole project.”
好像不支持
proxies=proxies
的写法啊
不过貌似直接把拼出来的代理地址加上去,估计就可以了。
去试试
结果用:
### dobel 多贝云 IP代理
#http代理接入服务器地址端口
ProxyHost = "http-proxy-t3.dobel.cn"
ProxyPort = "9180"
#账号密码
ProxyUser = "xxx"
ProxyPass = "xxx"
ProxyUri = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
"host" : ProxyHost,
"port" : ProxyPort,
"user" : ProxyUser,
"pass" : ProxyPass,
}
class Handler(BaseHandler):
crawl_config = {
"proxy": ProxyUri,加上之前的
其中的保留之前的headers
class Handler(BaseHandler):
crawl_config = {
"proxy": ProxyUri,
"connect_timeout": 100,
"timeout": 600,
"retries": 15,
"headers": {
"User-Agent": constUserAgentMacChrome,
# "Accept": "application/json, text/javascript, */*; q=0.01",
# "Accept": "application/json, text/javascript, text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*; q=0.8,application/signed-exchange;v=b3",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
# "Content-Type": "application/json",
"Origin": "http://www.dianping.com",
"Host": "www.dianping.com",
"Cache-Control": "no-cache",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Upgrade-Insecure-Requests": "1",
"Pragma": "no-cache",
"Connection": "keep-alive",
"Cookie": "_lxsdk_cuid=16a200a8282c8-055d7d49cf2d47-12316d51-fa000-16a200a8282c8; _lxsdk=16a200a8282c8-055d7d49cf2d47-12316d51-fa000-16a200a8282c8; _hc.v=f301d625-2322-83f6-b7f0-4686373a858b.1555315721; aburl=1; Hm_lvt_dbeeb675516927da776beeb1d9802bd4=1555386214; wed_user_path=33780|0; cy=509; cye=wangdu; Hm_lpvt_dbeeb675516927da776beeb1d9802bd4=1555484470; _lxsdk_s=16a29fd395b-0ac-21b-f2%7C%7C34",
# "X-Requested-With": "XMLHttpRequest",
}
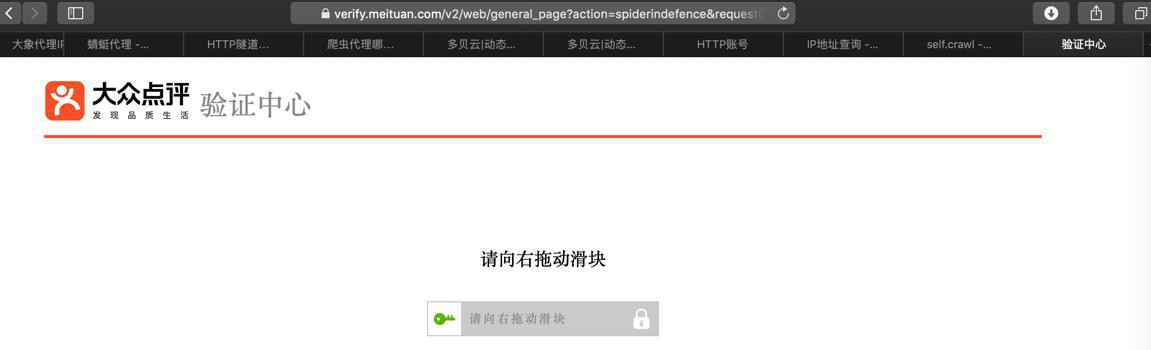
}但是去调试时,竟然很快就出现:之前的反扒页面了:
那去掉之前的cookie等参数试试
去掉:
“Connection”: “keep-alive”,
“Cookie”: xxx
结果:
还是
respUrl=https://verify.meituan.com/xxx

打开验证页面,输入了验证码后,页面可以正常访问了。
再去调试,结果又出错:
去用多贝云代理IP去调试,结果出错:
[E 190422 17:56:01 base_handler:203] HTTP 599: Proxy CONNECT aborted Traceback (most recent call last): File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 196, in run_task result = self._run_task(task, response) File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 175, in _run_task response.raise_for_status() File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/pyspider/libs/response.py", line 172, in raise_for_status six.reraise(Exception, Exception(self.error), Traceback.from_string(self.traceback).as_traceback()) File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/six.py", line 692, in reraise raise value.with_traceback(tb) File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/pyspider/fetcher/tornado_fetcher.py", line 378, in http_fetch response = yield gen.maybe_future(self.http_client.fetch(request)) File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/tornado/httpclient.py", line 102, in fetch self._async_client.fetch, request, **kwargs)) File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/tornado/ioloop.py", line 458, in run_sync return future_cell[0].result() File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/tornado/concurrent.py", line 238, in result raise_exc_info(self._exc_info) File "<string>", line 4, in raise_exc_info Exception: HTTP 599: Proxy CONNECT aborted
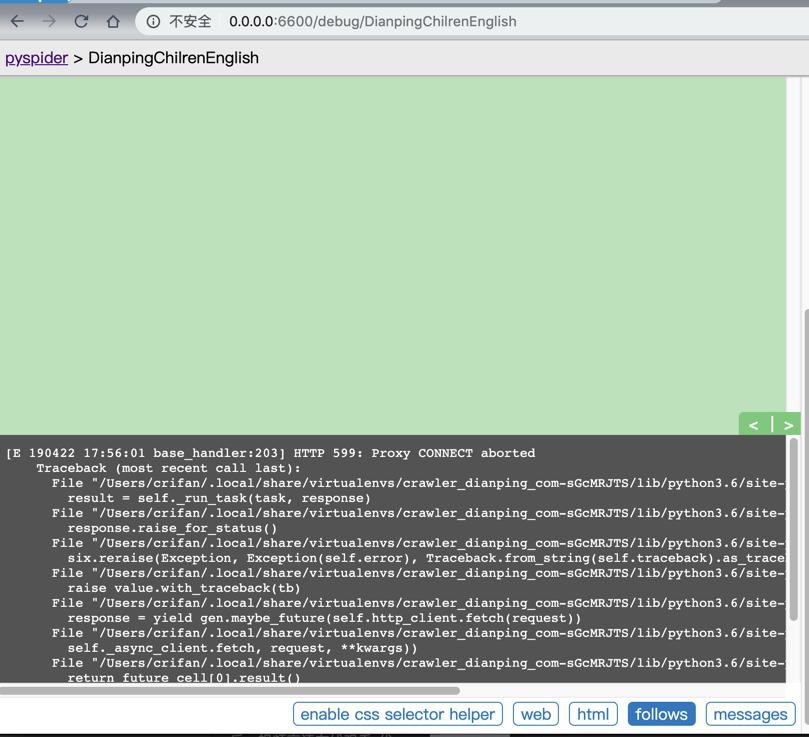
多贝云 IP代理 Exception HTTP 599 Proxy CONNECT aborted
PySpider proxy Exception HTTP 599 Proxy CONNECT aborted
后记:发现无需解决
加上额外测试代码,看看此处代理IP是否生效了,结果出错:
【已解决】PySpider中使用IP代理proxy出错:requests.exceptions.HTTPError HTTP 404 Not Found
再去看看上面的599问题。
又可以了。。没599的问题了。。。
这样至少通过:
class Handler(BaseHandler):
crawl_config = {
"proxy": ProxyUri,
"connect_timeout": 100,
"timeout": 600,
"retries": 15,
...
}
def testProxy(self):
# test proxy ip
# targetUrl = "https://api.ipify.org?format=json"
targetUrl = "https://www.taobao.com/help/getip.php"
self.crawl(
targetUrl,
# proxy=ProxyUri,
cookies={},
callback=self.testProxyCallback
)的方式,实现了PySpider中使用多贝云代理IP了,效果是:
respUrl=https://www.taobao.com/help/getip.php
respText=ipCallback({ip:"120.11.185.123"})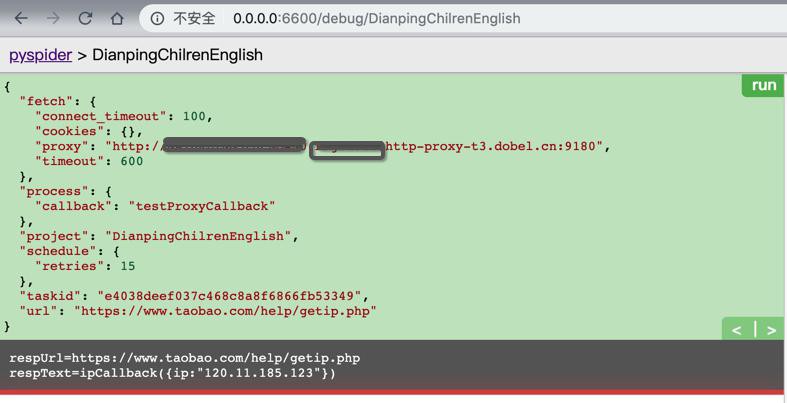
但是后来多次调试发现个问题:
调试时刷新页面,结果请求IP没变。
然后一直以为是此处PySpider中试用代理的问题呢。
后来无意间发现从:
看到了自己之前就想要试用的去测试IP的:
Mac中Safari效果是:
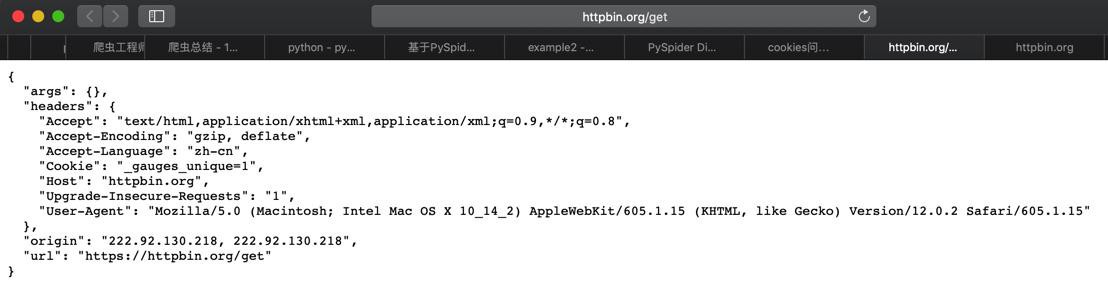
{
"args": {},
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-cn",
"Cookie": "_gauges_unique=1",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.2 Safari/605.1.15"
},
"origin": "222.92.130.218, 222.92.130.218",
"url": "https://httpbin.org/get"
}而换到PySpider中:
def testProxy(self):
# test proxy ip
# targetUrl = "https://api.ipify.org?format=json"
# targetUrl = "https://www.taobao.com/help/getip.php"
targetUrl = "http://httpbin.org/get"
self.crawl(
targetUrl,
# proxy=ProxyUri,
headers=self.genCurHeaders(),
cookies={},
callback=self.testProxyCallback
)效果是:
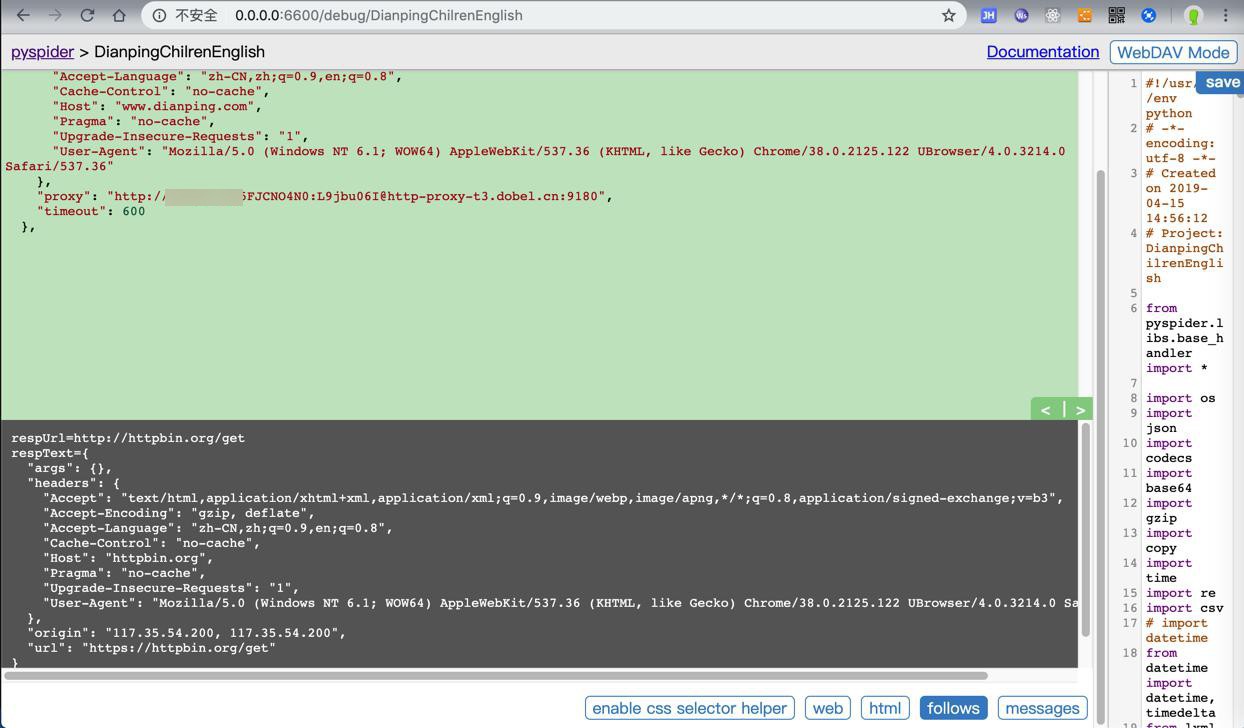
真的实现了我们希望的:多次请求,IP不同 的效果了:
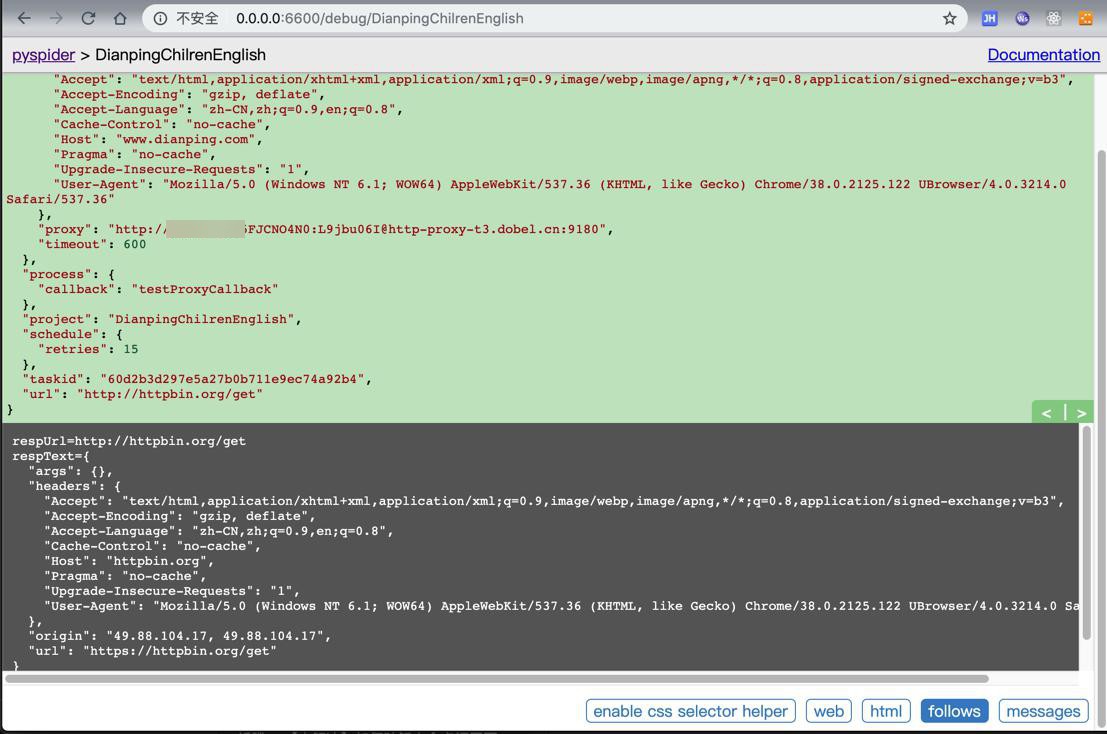
注意到:此处header中已经加上了,禁止缓存相关的参数:
"Cache-Control": "no-cache", "Pragma": "no-cache",
且去掉了:
"Connection": "keep-alive",
->可以确保不应该有缓存页面了
->而对于之前的:
https://www.taobao.com/help/getip.php
却对于后续请求返回同样的IP
反推出:淘宝的这个api是有缓存的,有问题的。
还是:
http://httpbin.org/get
做的专业,准确。
后来也在:
【未解决】如何破解大众点评网页爬取时的反扒验证verify.meituan.com
期间,参考:
去确认此处PySpider的版本是:
➜ crawler_dianping_com git:(master) ✗ pipenv graph pyspider==0.3.10 - chardet [required: >=2.2, installed: 3.0.4] - click [required: >=3.3, installed: 7.0] - cssselect [required: >=0.9, installed: 1.0.3] - Flask [required: >=0.10, installed: 1.0.2] - click [required: >=5.1, installed: 7.0] - itsdangerous [required: >=0.24, installed: 1.1.0] - Jinja2 [required: >=2.10, installed: 2.10.1] - MarkupSafe [required: >=0.23, installed: 1.1.1] - Werkzeug [required: >=0.14, installed: 0.15.2] - Flask-Login [required: >=0.2.11, installed: 0.4.1] - Flask [required: Any, installed: 1.0.2] - click [required: >=5.1, installed: 7.0] - itsdangerous [required: >=0.24, installed: 1.1.0] - Jinja2 [required: >=2.10, installed: 2.10.1] - MarkupSafe [required: >=0.23, installed: 1.1.1] - Werkzeug [required: >=0.14, installed: 0.15.2] - Jinja2 [required: >=2.7, installed: 2.10.1] - MarkupSafe [required: >=0.23, installed: 1.1.1] - lxml [required: Any, installed: 4.3.3] - pycurl [required: Any, installed: 7.43.0.2] - pyquery [required: Any, installed: 1.4.0] - cssselect [required: >0.7.9, installed: 1.0.3] - lxml [required: >=2.1, installed: 4.3.3] - requests [required: >=2.2, installed: 2.21.0] - certifi [required: >=2017.4.17, installed: 2019.3.9] - chardet [required: >=3.0.2,<3.1.0, installed: 3.0.4] - idna [required: >=2.5,<2.9, installed: 2.8] - urllib3 [required: >=1.21.1,<1.25, installed: 1.24.1] - six [required: >=1.5.0, installed: 1.12.0] - tblib [required: >=1.3.0, installed: 1.3.2] - tornado [required: >=3.2,<=4.5.3, installed: 4.5.3] - u-msgpack-python [required: >=1.6, installed: 2.5.1] - wsgidav [required: >=2.0.0, installed: 2.4.1] - defusedxml [required: Any, installed: 0.5.0] - jsmin [required: Any, installed: 2.2.2] - PyYAML [required: Any, installed: 5.1]
-》不是有问题的0.3.8的版本。
-》是最新的版本:0.3.10
【总结】
PySpider中设置了全局的代理:
### dobel 多贝云 IP代理
#http代理接入服务器地址端口
ProxyHost = "http-proxy-t3.dobel.cn"
ProxyPort = "9180"
#账号密码
ProxyUser = "UUUU"
ProxyPass = "PPPPP"
ProxyUri = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
"host" : ProxyHost,
"port" : ProxyPort,
"user" : ProxyUser,
"pass" : ProxyPass,
}
class Handler(BaseHandler):
crawl_config = {
"proxy": ProxyUri,
...
}后,之后的self.crawl正常调用url,即可用上此处的代理了。
其中ProxyUri是这种:
http://UserName:Password@http-proxy-t3.dobel.cn:9180
【后记】
如果账号过期了:
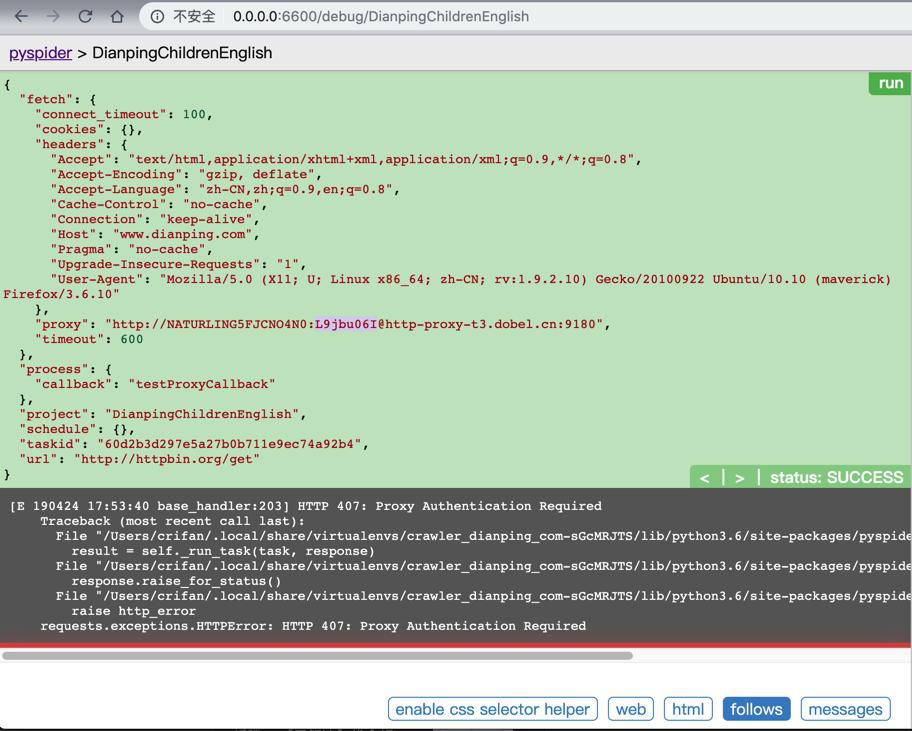
则会出现:
requests.exceptions.HTTPError: HTTP 407: Proxy Authentication Required
[E 190424 17:53:40 base_handler:203] HTTP 407: Proxy Authentication Required Traceback (most recent call last): File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 196, in run_task result = self._run_task(task, response) File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 175, in _run_task response.raise_for_status() File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/pyspider/libs/response.py", line 184, in raise_for_status raise http_error requests.exceptions.HTTPError: HTTP 407: Proxy Authentication Required