根据需求,需要去爬取:
中,对应的内容的:
字幕,去掉各种标注的
音频,如果有
视频,如果有
参考之前自己的:
【记录】用Python的Scrapy去爬取Youtube中Humf的字幕
去操作:
<code>➜ childes git:(master) ✗ /Users/crifan/dev/dev_root/company/naturling/projects/crawler_projects ➜ crawler_projects git:(master) ll total 8 -rw-r--r-- 1 crifan staff 187B 3 21 14:01 README.md drwxr-xr-x 8 crifan staff 256B 3 21 13:58 scrapyYoutubeSubtitleHumf ➜ crawler_projects git:(master) scrapy startproject scrapyChildes New Scrapy project 'scrapyChildes', using template directory '/usr/local/lib/python2.7/site-packages/scrapy/templates/project', created in: /Users/crifan/dev/dev_root/company/naturling/projects/crawler_projects/scrapyChildes You can start your first spider with: cd scrapyChildes scrapy genspider example example.com ➜ crawler_projects git:(master) ✗ cd scrapy cd: no such file or directory: scrapy ➜ crawler_projects git:(master) ✗ cd scrapyChildes ➜ scrapyChildes git:(master) ✗ ll total 8 -rw-r--r-- 1 crifan staff 270B 3 22 15:41 scrapy.cfg drwxr-xr-x 8 crifan staff 256B 3 22 15:41 scrapyChildes ➜ scrapyChildes git:(master) ✗ cd scrapyChildes ➜ scrapyChildes git:(master) ✗ scrapy genspider Childes https://childes.talkbank.org/access/Eng-NA/ Created spider 'Childes' using template 'basic' in module: scrapyChildes.spiders.Childes </code>
然后初始化后是: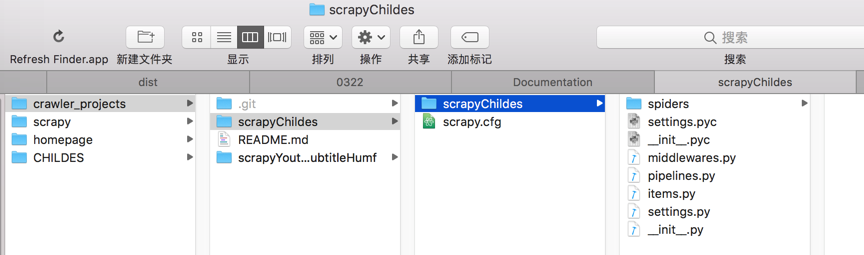
然后就可以继续去写代码了
然后用:
<code># -*- coding: utf-8 -*-
import scrapy
from urllib import urlencode, unquote
import re
import json
from bs4 import BeautifulSoup
import os
class ChildesSpider(scrapy.Spider):
name = 'Childes'
allowed_domains = ['talkbank.org']
start_urls = [
# https://childes.talkbank.org/access/Eng-NA/
'https://childes.talkbank.org/access/Eng-NA/Bliss.html',
'https://childes.talkbank.org/access/Eng-NA/Bloom70.html',
'https://childes.talkbank.org/access/Eng-NA/Bohannon.html',
'https://childes.talkbank.org/access/Eng-NA/Braunwald.html',
'https://childes.talkbank.org/access/Eng-NA/Brown.html',
'https://childes.talkbank.org/access/Eng-NA/Carterette.html',
'https://childes.talkbank.org/access/Eng-NA/Clark.html',
'https://childes.talkbank.org/access/Eng-NA/Cornell.html',
'https://childes.talkbank.org/access/Eng-NA/Demetras1.html',
'https://childes.talkbank.org/access/Clinical-MOR/EllisWeismer.html',
'https://childes.talkbank.org/access/Eng-NA/Garvey.html',
'https://childes.talkbank.org/access/Eng-NA/Gathercole.html',
'https://childes.talkbank.org/access/Clinical-MOR/Gillam.html',
'https://childes.talkbank.org/access/Eng-NA/Gleason.html',
'https://childes.talkbank.org/access/Eng-NA/Hall.html',
'https://childes.talkbank.org/access/Eng-NA/HSLLD.html',
'https://childes.talkbank.org/access/Eng-NA/Kuczaj.html',
'https://childes.talkbank.org/access/Eng-NA/MacWhinney.html',
'https://childes.talkbank.org/access/Eng-NA/McCune.html',
'https://childes.talkbank.org/access/Eng-NA/McMillan.html',
'https://talkbank.org/access/ASDBank/English/Nadig.html',
'https://childes.talkbank.org/access/Eng-NA/Nelson.html',
'https://childes.talkbank.org/access/Clinical-MOR/Nicholas/NH.html',
'https://childes.talkbank.org/access/Eng-NA/Peters.html',
'https://phonbank.talkbank.org/access/Eng-NA/Providence.html',
'https://childes.talkbank.org/access/Clinical-MOR/Rondal/Normal.html',
'https://childes.talkbank.org/access/Eng-NA/Sachs.html',
'https://childes.talkbank.org/access/Eng-NA/Sawyer.html',
'https://childes.talkbank.org/access/Eng-NA/Snow.html',
'https://childes.talkbank.org/access/Eng-NA/Sprott.html',
'https://childes.talkbank.org/access/Eng-NA/Suppes.html',
'https://childes.talkbank.org/access/Eng-NA/Tardif.html',
'https://childes.talkbank.org/access/Eng-NA/VanHouten.html',
'https://childes.talkbank.org/access/Eng-NA/VanKleeck.html',
'https://childes.talkbank.org/access/Eng-NA/Warren.html',
'https://childes.talkbank.org/access/Eng-NA/Weist.html',
'https://childes.talkbank.org/access/Clinical-MOR/Feldman/Narrative.html',
'https://childes.talkbank.org/access/Clinical-MOR/Feldman/ParentChild.html',
'https://childes.talkbank.org/access/Clinical-MOR/Feldman/Twins.html',
# https://childes.talkbank.org/access/Biling/
'https://childes.talkbank.org/access/Biling/Singapore.html',
# https://childes.talkbank.org/access/Eng-UK/
'https://childes.talkbank.org/access/Eng-UK/Belfast.html',
'https://childes.talkbank.org/access/Eng-UK/Cruttenden.html',
'https://childes.talkbank.org/access/Eng-UK/Fletcher.html',
'https://childes.talkbank.org/access/Eng-UK/Forrester.html',
'https://childes.talkbank.org/access/Eng-UK/Gathburn.html',
'https://childes.talkbank.org/access/Eng-UK/Lara.html',
'https://childes.talkbank.org/access/Eng-UK/Manchester.html',
'https://childes.talkbank.org/access/Eng-UK/MPI-EVA-Manchester.html',
'https://childes.talkbank.org/access/Eng-UK/Thomas.html',
'https://childes.talkbank.org/access/Eng-UK/Tommerdahl.html',
'https://childes.talkbank.org/access/Eng-UK/Wells.html',
]
outputRootFolder = "output"
def jsonToStr(self, jsonDict, indent=2):
return json.dumps(jsonDict, indent=indent, ensure_ascii=False)
def saveToFile(self, filename, content, folder=outputRootFolder, suffix=".html"):
if not os.path.exists(folder):
os.makedirs(folder)
filename = filename + suffix
fullFilename = folder + "/" + filename # 'output/Eng-NA/Bliss/Bliss.html'
with open(fullFilename, 'wb') as f:
f.write(content)
def saveHtml(self, response):
respUrl = response.url
self.logger.info("respUrl=%s", respUrl) # https://childes.talkbank.org/access/Eng-NA/Bliss.html
htmlData = response.body
htmlFilename = respUrl.split("/")[-1] # 'Bliss.html'
self.logger.info("htmlFilename=%s", htmlFilename)
saveFolder = self.extractSaveFolerFromUrl(respUrl)
self.logger.info("saveFolder=%s", saveFolder) # 'Eng-NA/Bliss'
saveFolder = self.outputRootFolder + "/" + saveFolder
self.logger.info("saveFolder=%s", saveFolder) # 'output/Eng-NA/Bliss'
self.saveToFile(htmlFilename, htmlData, folder=saveFolder, suffix="")
def extractSaveFolerFromUrl(self, url):
groupAndFilename = None
foundProupAndFilename = re.search(r'talkbank\.org/access/(?P<groupAndFilename>[\w\-/]+)\.html$', url)
if foundProupAndFilename:
groupAndFilename = foundProupAndFilename.group("groupAndFilename") # 'Eng-NA/Bliss'
self.logger.info("groupAndFilename=%s", groupAndFilename)
else:
self.logger.warning("can not find ground and file name from url: %s", url)
return groupAndFilename
def parse(self, response):
self.saveHtml(response=response)
</code>已经可以下载到html了:
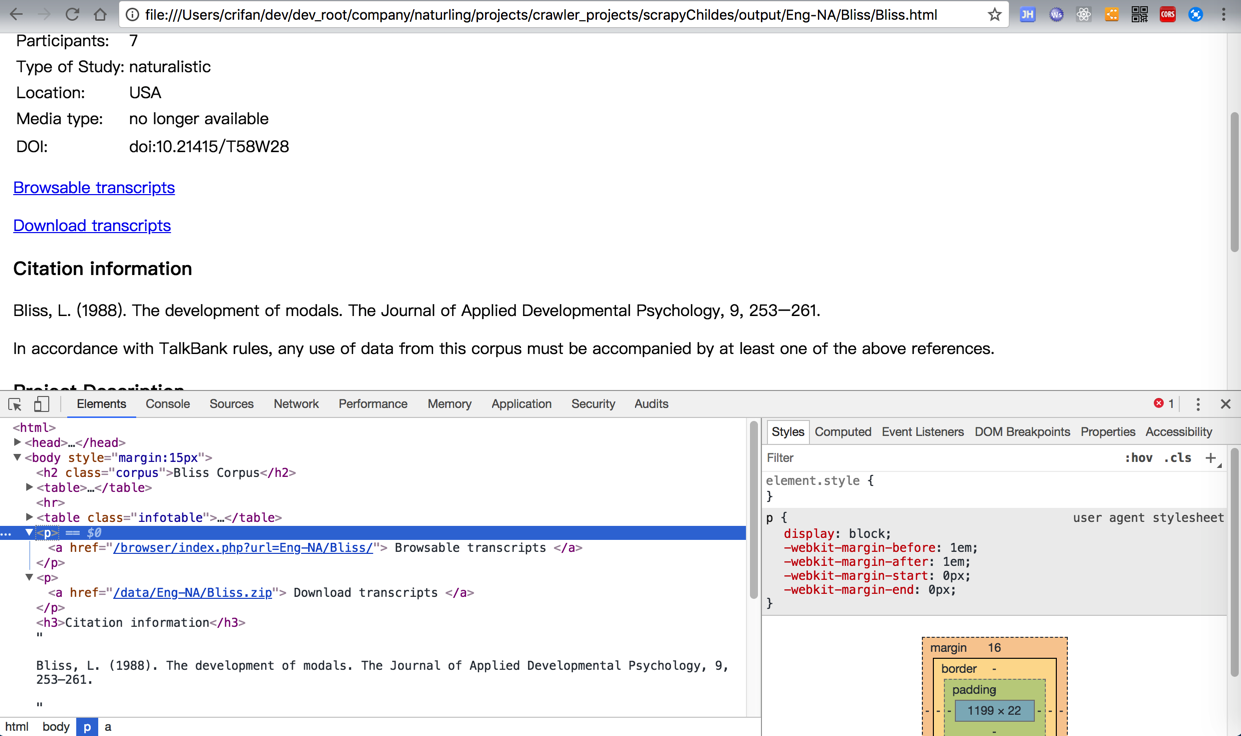
现在需要去提取,找出对应的:
<code><p> <a href="/browser/index.php?url=Eng-NA/Bliss/"> Browsable transcripts </a> </p> </code>
的部分。
即:
如何通过scrapy中,查找a的href的值是/browser/index.php?url开头的,或者是a的值包含Browsable transcripts
所以去搜:
scrapy find by value
选择器(Selectors) — Scrapy 0.24.6 文档
去试试xpath,好像用contains之类的函数是可以实现的
然后通过调试:
<code>scrapy shell
fetch("https://childes.talkbank.org/access/Eng-NA/Bliss.html")
</code>是可以找到的:
<code>>>> response.xpath('//p/a[starts-with(@href, "/browser/index.php?url=")]')
[<Selector xpath='//p/a[starts-with(@href, "/browser/index.php?url=")]' data=u'<a href="/browser/index.php?url=Eng-NA/B'>]
>>> response.xpath('//p/a[contains(text(), "Browsable transcripts")]')
[<Selector xpath='//p/a[contains(text(), "Browsable transcripts")]' data=u'<a href="/browser/index.php?url=Eng-NA/B’>]
>>> response.xpath('//p/a[contains(text(), "Browsable transcripts")]').xpath('@href').extract()
[u'/browser/index.php?url=Eng-NA/Bliss/']
</code>所以可以用代码去继续处理了。
转载请注明:在路上 » 【记录】爬取CHILDES中的字幕和音视频文件