
【整理】BeautifulSoup中的.string和.text的区别
crifan 13年前 (2013-09-09) 12436浏览 0评论
【背景】 是别人问我的: BeautifulSoup 4中,soup.string和soup.text何有区别。 【折腾过程】 1.去beautifulsoup的官网: bs3: http://www.crummy.com/software/Beau...
crifan 13年前 (2013-09-09) 12436浏览 0评论
【背景】 是别人问我的: BeautifulSoup 4中,soup.string和soup.text何有区别。 【折腾过程】 1.去beautifulsoup的官网: bs3: http://www.crummy.com/software/Beau...
crifan 13年前 (2013-09-09) 3819浏览 0评论
1.搜到的一些参考资料,有空可以去试试: http://www.endlesslycurious.com/2012/06/13/scraping-pdf-with-python/ https://github.com/dpapathanasi...
crifan 13年前 (2013-09-06) 8356浏览 2评论
Python 2.7手册中的官网解释为: (?:...) A non-capturing version of regular parentheses. Matches whatever regular expression is insi...
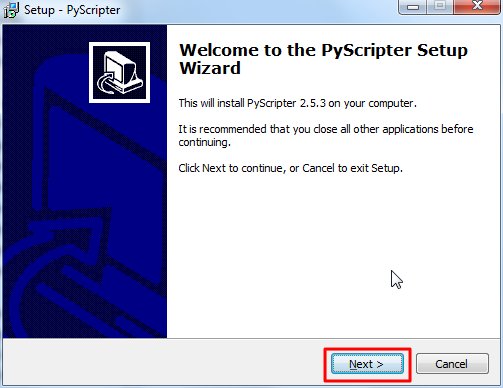
crifan 13年前 (2013-08-30) 16832浏览 17评论
关于什么是Python的IDE,不了解的先去看: 【整理】【多图详解】如何在Windows下开发Python:在cmd下运行Python脚本+如何使用Python Shell(command line模式和GUI模式)+如何使用Python IDE ...
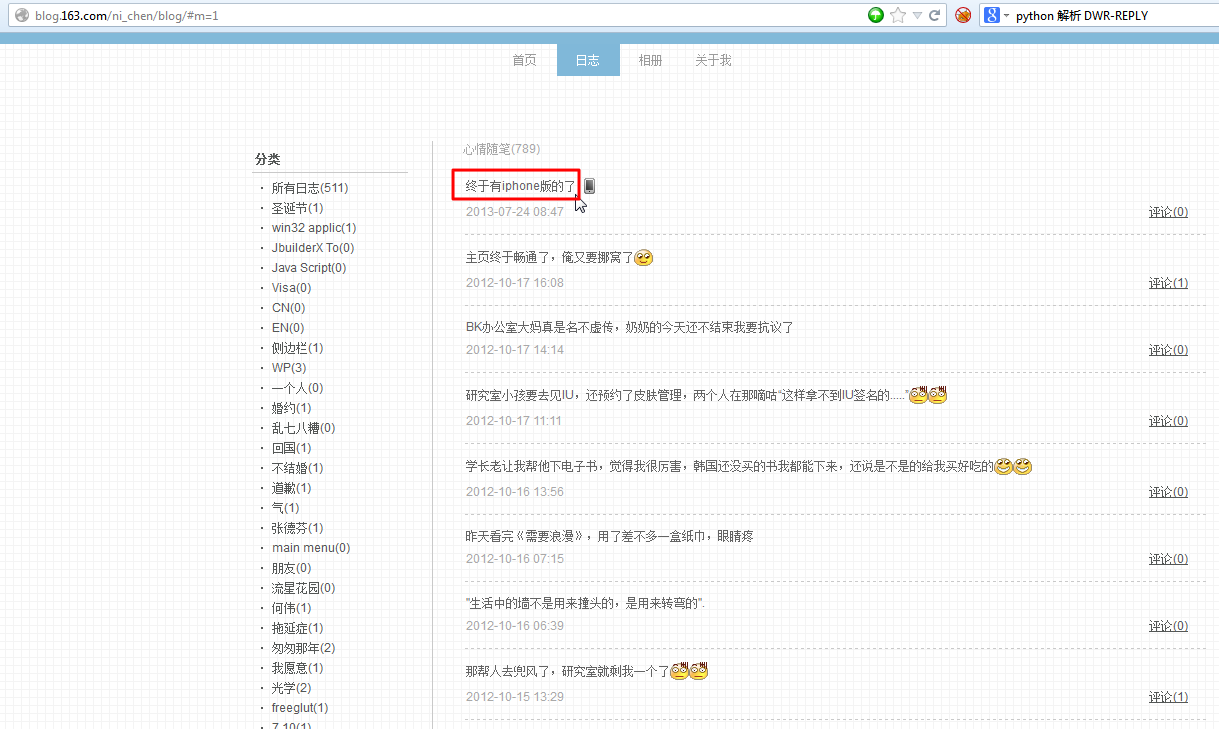
crifan 13年前 (2013-08-26) 4286浏览 2评论
【背景】 之前自己弄的BlogsToWordpress,后来希望添加支持,导出网易163博客中的心情随笔的内容。 之前已经通过代码,可以获得返回的DWR-REPLY数据了: 【记录】给BlogsToWordPress添加支持导出网易的心情随笔 现在就...
crifan 13年前 (2013-08-12) 11265浏览 6评论
【问题】 用Python脚本模拟登陆百度空间。 需要先获得最开始登陆的百度空间网页所返回的cookie。 【解决过程】 1.搜了一番,最后参考这个: 利用Python抓取需要登录网站的信息 实现了对应的代码: loginUrl = "htt...
crifan 13年前 (2013-08-01) 3578浏览 1评论
【背景】 之前用过Python的chardet: https://pypi.python.org/pypi/chardet (代码下载在:https://github.com/dcramer/chardet) 现在,在看Requests的编码方式时,...
crifan 13年前 (2013-07-28) 3147浏览 0评论
【背景】 之前在: 【记录】Android中用java的正则查找并替换宏定义中的参数 在java中,用如下代码: /** * @author Crifan Li * * @function test java regex look ahead...
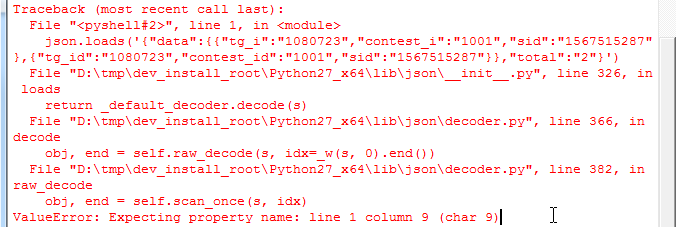
crifan 13年前 (2013-07-26) 5677浏览 1评论
【问题】 别人给了一个json(形式)的,非正常的json字符串 {data:{{tg_i":"1080723", contest_i":"1001", sid:"15675152...
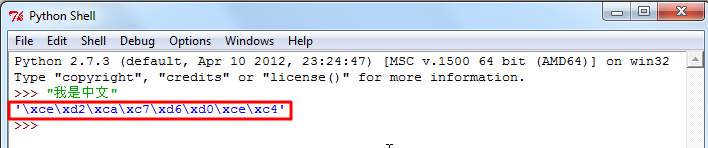
crifan 13年前 (2013-07-19) 9330浏览 6评论
【背景】 Python中的字符编码,其实的确有点复杂。 再加上,不同的开发环境和工具中,显示的逻辑和效果又不太相同,尤其是,中文的,初级用户,最常遇到的: (1)在Python自带的IDE:IDLE中折腾中文字符,结果看到的差不多都是乱码类的东西,比...