折腾:
【未解决】uiautomator2模拟安卓浏览器的百度搜索后去获取和解析搜索结果
期间,继续去看看,如何获取标题外的描述文字和网站来源
如果想要找 描述文字
则对比半天,才找到能区分开的规则:
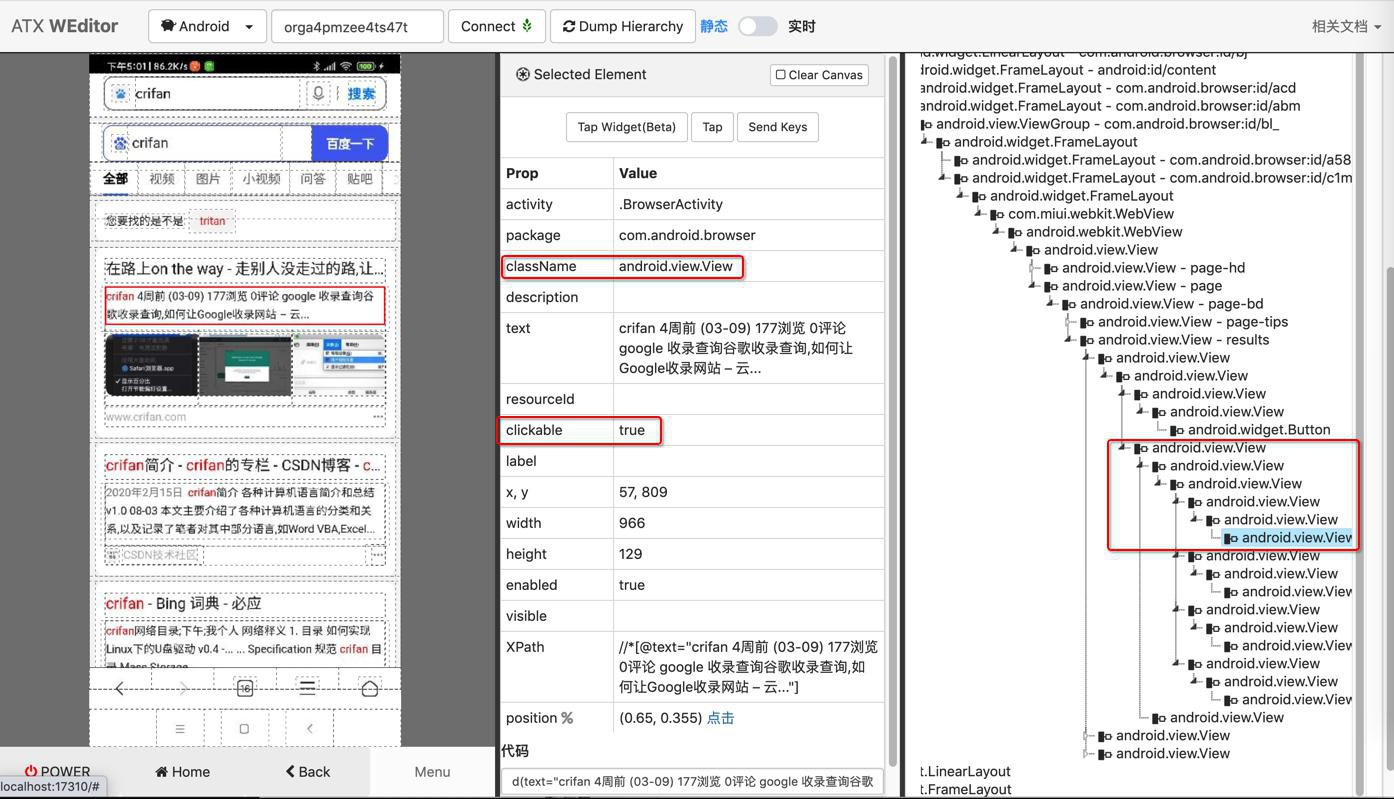
是results下面的,固定的
只能从父级元素去找:
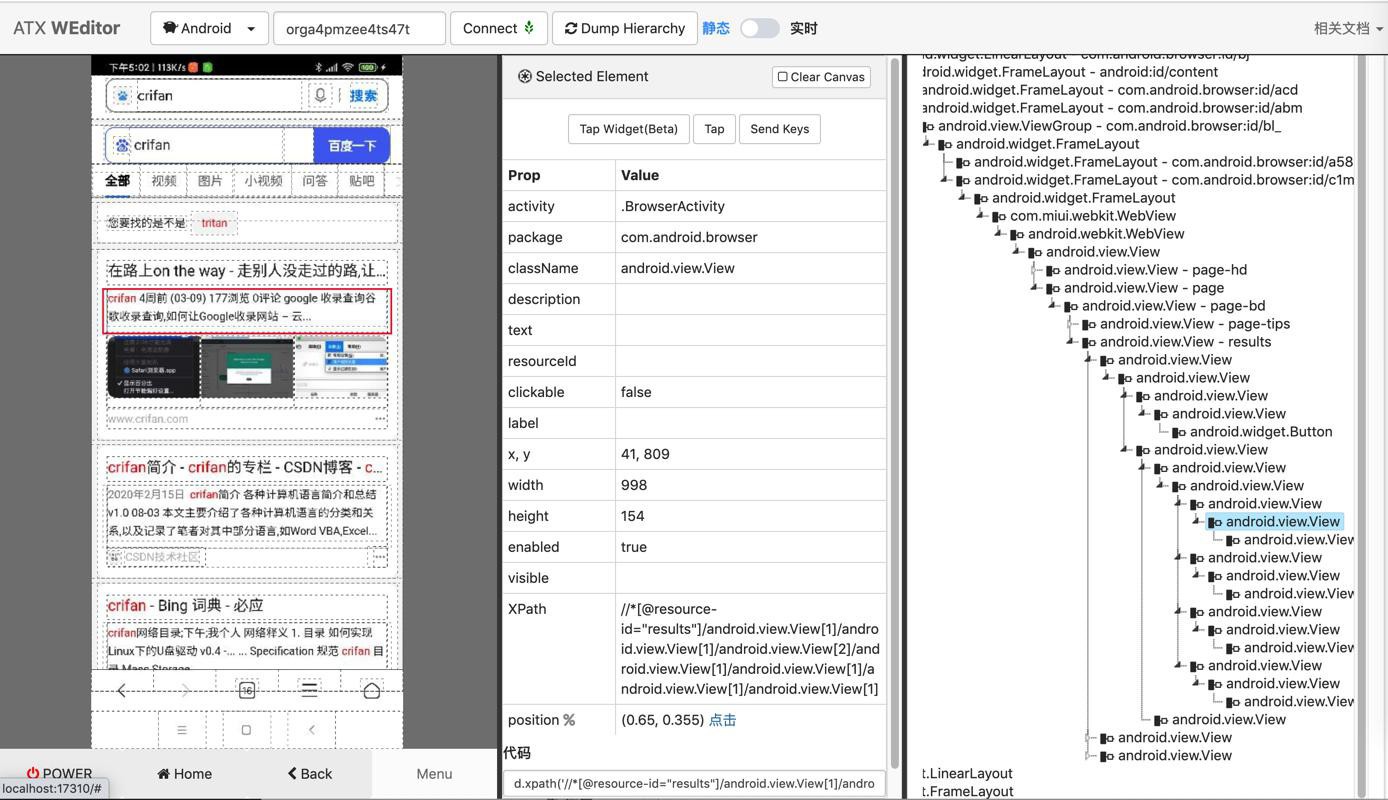
d.xpath('//*[@resource-id="results"]/android.view.View[1]/android.view.View[1]/android.view.View[2]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]')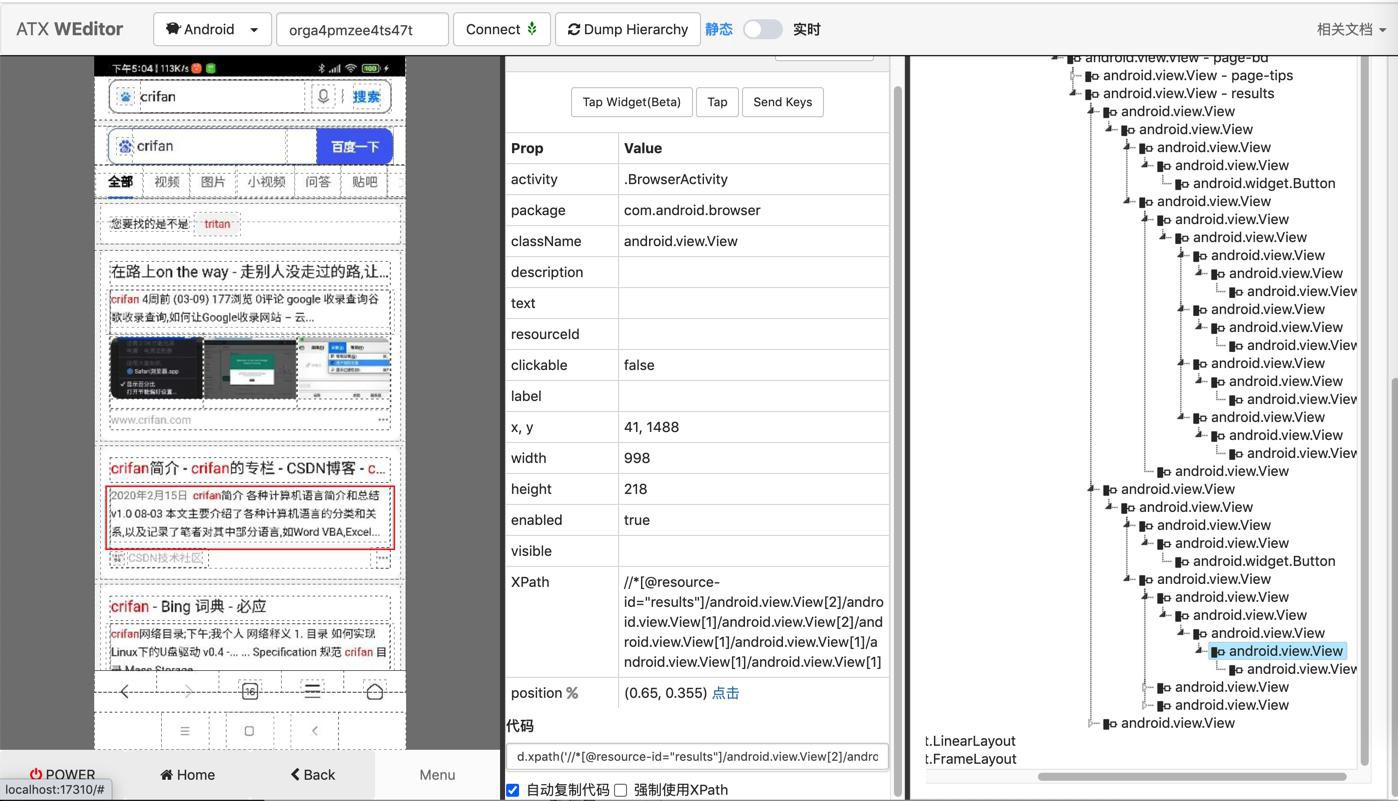
d.xpath('//*[@resource-id="results"]/android.view.View[2]/android.view.View[1]/android.view.View[2]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]')然后看看如何写代码去解析
本来是打算从顶层找的
现在发现,也可以从
title的button,去向上,然后再向下找sibling去找,即:
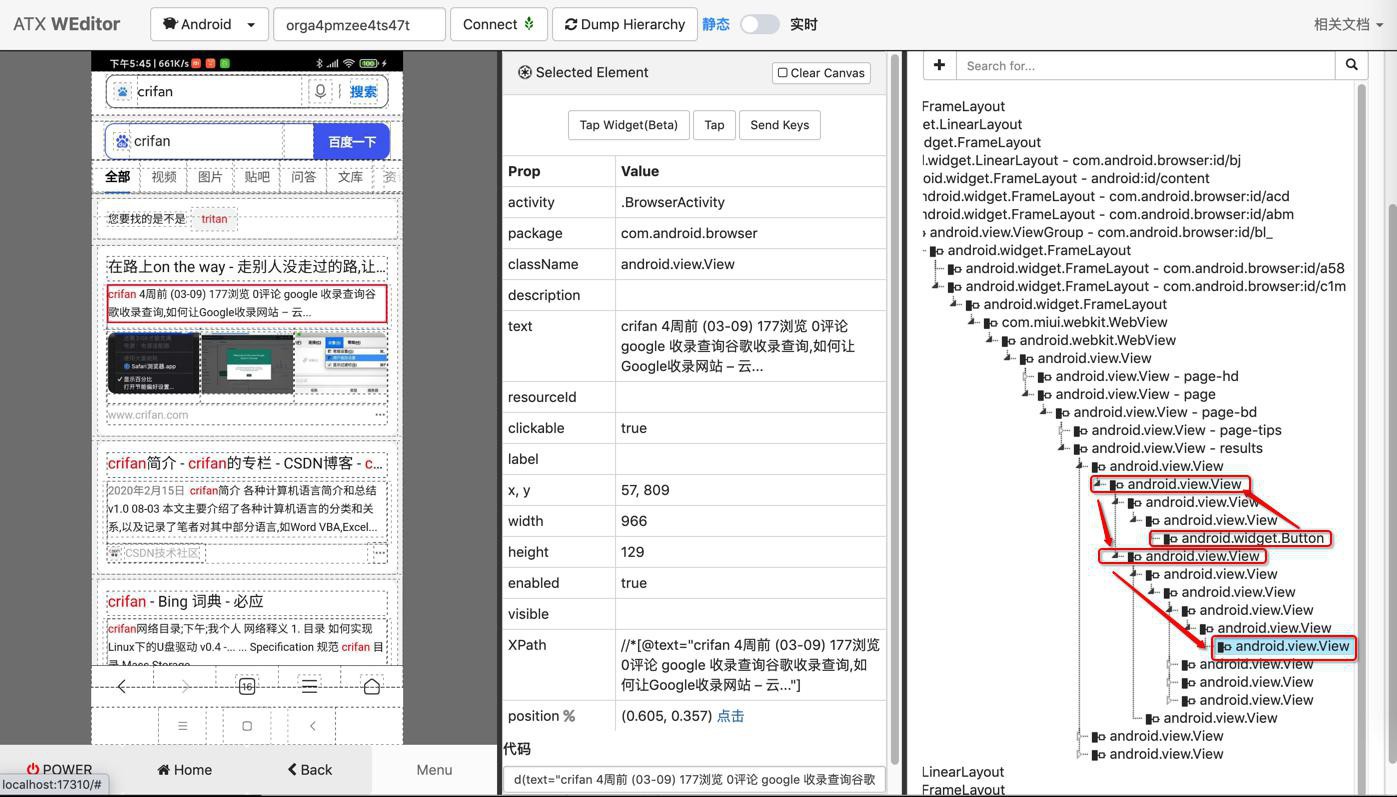
去写代码试试
# get description text titleParentElem = eachTitleButtonElement.parent titleParent2Elem = titleParentElem.parent
发现此处已经是 XMLElement了,不是Xpath的Selector,没法用xpath的语法去找sibling
好像不方便
先调试看看
或者去找 xml的element,如何找sibling
XMLElement的操作
没找到parent或sibling
去看看uiautomator2的源码
/Users/xxx/.pyenv/versions/3.8.0/Python.framework/Versions/3.8/lib/python3.8/site-packages/uiautomator2/xpath.py
class XMLElement(object):
def __init__(self, elem, parent: XPath):
"""
Args:
elem: lxml node
d: uiautomator2 instance
"""
self.elem = elem
self._parent = parent
self._d = parent._d
。。。
def click(self):
"""
click element, 100ms between down and up
"""
x, y = self.center()
self._parent.send_click(x, y)
...
@property
def text(self):
return self.elem.attrib.get("text")
@property
def attrib(self):
return self.elem.attrib
@property
def info(self):
ret = {}
for key in ("text", "focusable", "enabled", "focused", "scrollable",
"selected"):
ret[key] = self.attrib.get(key)
ret["className"] = self.elem.tag
lx, ly, rx, ry = self.bounds
ret["bounds"] = {'left': lx, 'top': ly, 'right': rx, 'bottom': ry}
ret["contentDescription"] = self.attrib.get("content-desc")
ret["longClickable"] = self.attrib.get("long-clickable")
ret["packageName"] = self.attrib.get("package")
return ret只是普通各种函数。
调试看,也的确没有parent
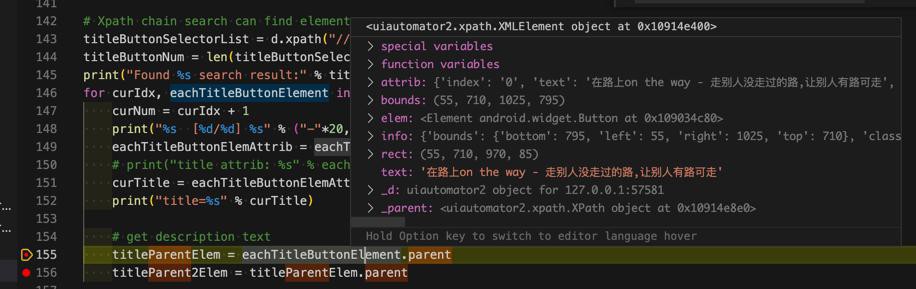
不过注意到有个_parent
好像是Xpath?
去看看?
parent会报错
Exception has occurred: AttributeError 'XMLElement' object has no attribute 'parent'

注意到代码中是:
__init__ self._parent = parent
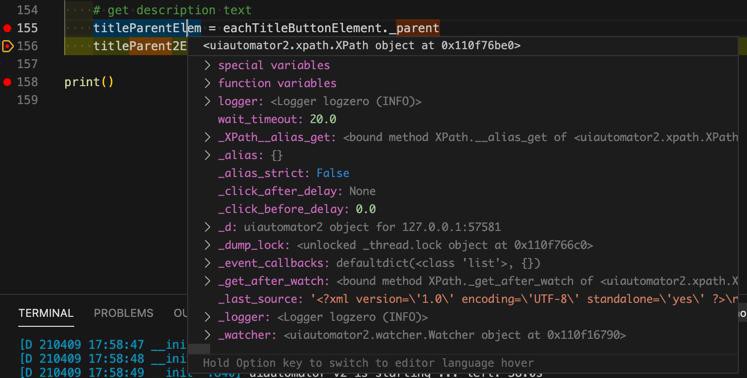
那去xpath找找试试
不过还是算了,用内部变量,本身就不是好做法。暂时不用。
不过还是看到之前的:
# 多个条件定位, 类似于AND
d.xpath('//android.widget.Button').xpath('//*[@text="私人FM"]')是支持 xpath的xpath的
此处为何无效,搜不到,很是奇怪
不过此处看代码
/Users/xxx/.pyenv/versions/3.8.0/Python.framework/Versions/3.8/lib/python3.8/site-packages/uiautomator2/xpath.py
class XMLElement(object): def __init__(self, elem, parent: XPath): """ Args: elem: lxml node d: uiautomator2 instance """ self.elem = elem self._parent = parent def all(self, source=None): """ Returns: list of XMLElement """ 。。 els = [XMLElement(node, self._parent) for node in match_nodes]
-》看来还是xpath就初始化给了_parent
-》看起来虽然是内部用的,外部用,也是可以的。
所以还是去试试_parent吧
# get description text
titleParentXpath = eachTitleButtonElement._parent
titleParent2Xpath = titleParentXpath.parent()
titleParent3Xpath = titleParent2Xpath.parent()
descriptionElemnt = titleParent3Xpath.xpath("//android.view.View[2]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]").get()
print("descriptionElemnt=%s" % descriptionElemnt)结果:
titleParent2Xpath = titleParentXpath.parent()
报错:
Exception has occurred: AttributeError 'XPath' object has no attribute 'parent'
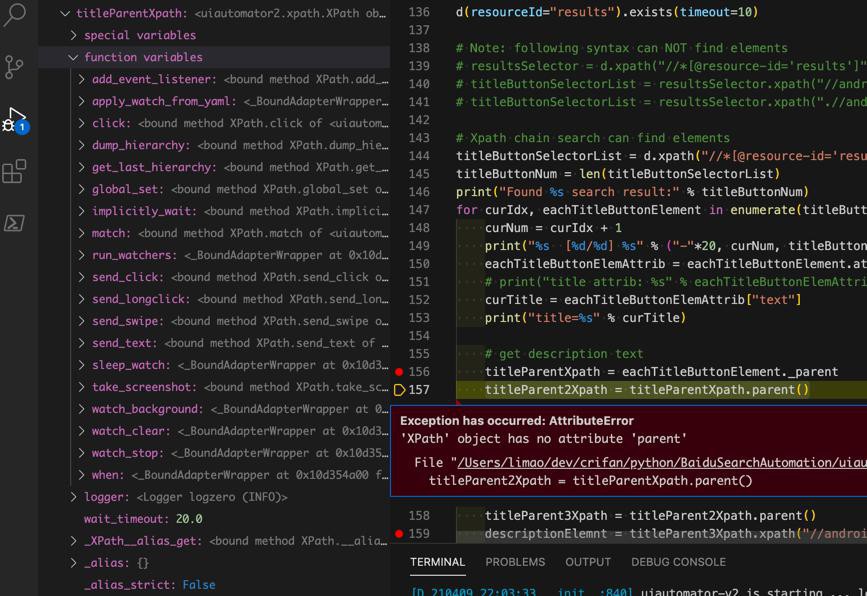
算了,换其他方式。
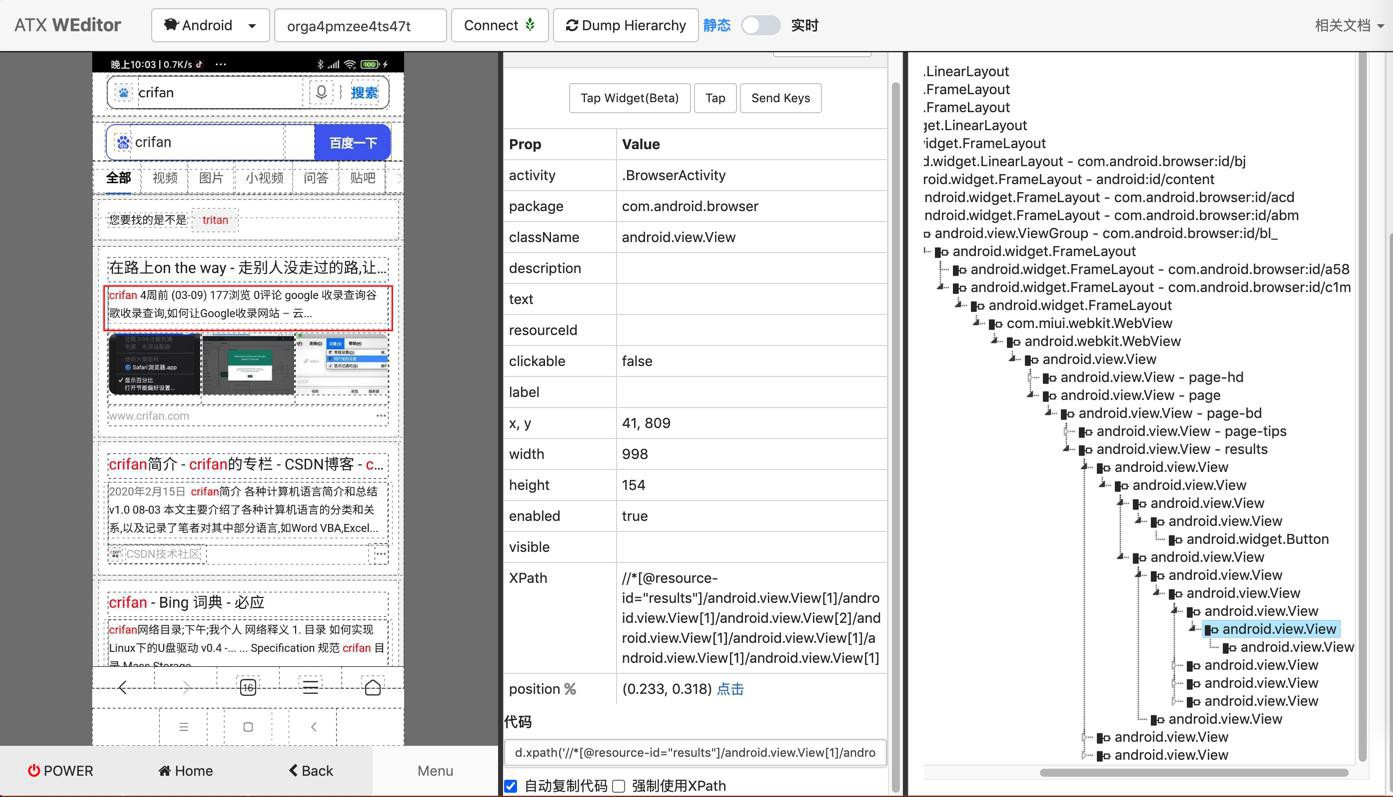
d.xpath('//*[@resource-id="results"]/android.view.View[1]/android.view.View[1]/android.view.View[2]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]')以及再加一个
/android.view.View[1]
变成代码:
descriptionElementList = d.xpath("//*[@resource-id='results']/android.view.View[1]/android.view.View[1]/android.view.View[2]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]").all()结果:

可以找到,但是是单个元素。
再去换成:
descriptionElementList = d.xpath("//*[@resource-id='results']/android.view.View/android.view.View[1]/android.view.View[2]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]").all()结果:
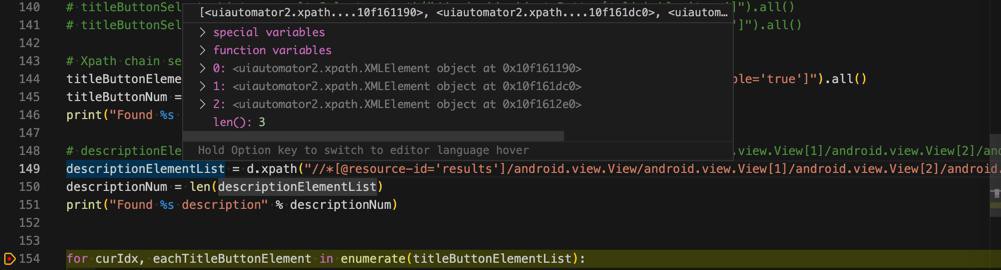
可以找到希望的3个了
继续用代码:
# descriptionElementList = d.xpath("//*[@resource-id='results']/android.view.View[1]/android.view.View[1]/android.view.View[2]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]").all()
descriptionElementList = d.xpath("//*[@resource-id='results']/android.view.View/android.view.View[1]/android.view.View[2]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]").all()
descriptionNum = len(descriptionElementList)
print("Found %s description" % descriptionNum)
。。。
curDescriptionElem = descriptionElementList[curIdx]
curDescription = curDescriptionElem.text
print("description=%s" % curDescription)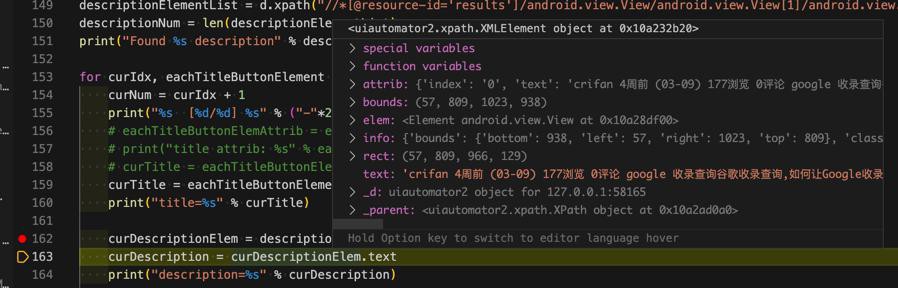
可以输出:
-------------------- [1/3] -------------------- title=在路上on the way - 走别人没走过的路,让别人有路可走 description=crifan 4周前 (03-09) 177浏览 0评论 google 收录查询谷歌收录查询,如何让Google收录网站 – 云...
继续去看看,来源网站的写法
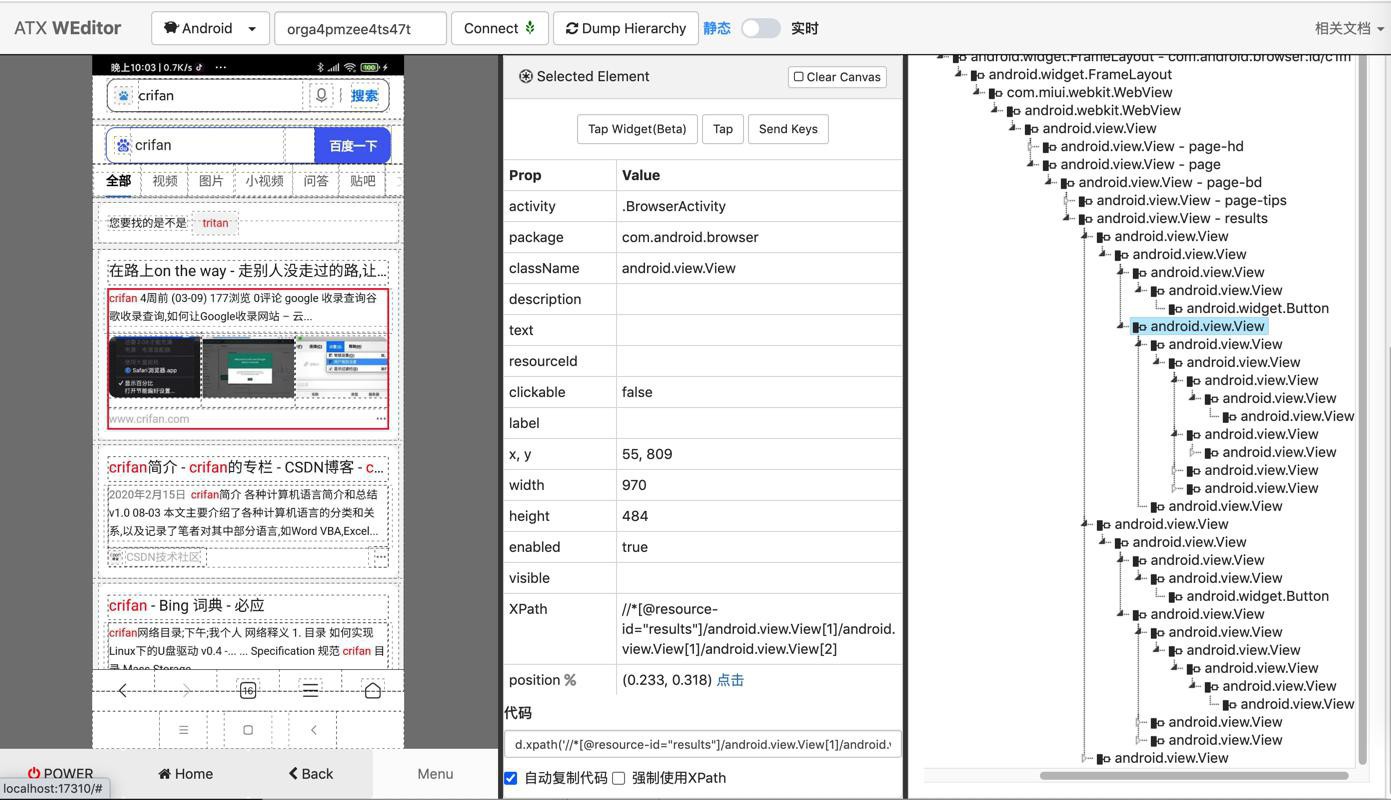
d.xpath('//*[@resource-id="results"]/android.view.View[1]/android.view.View[1]/android.view.View[2]')再加上:
/android.view.View[1]
即可。
以及:
再去看第二个:
d.xpath('//*[@resource-id="results"]/android.view.View[2]/android.view.View[1]/android.view.View[2]')-》
d.xpath('//*[@resource-id="results"]/android.view.View/android.view.View[1]/android.view.View[2]/android.view.View[1]')代码:
sourceWebsiteElementList = d.xpath('//*[@resource-id="results"]/android.view.View/android.view.View[1]/android.view.View[2]/android.view.View[1]').all()
sourceWebsiteNum = len(sourceWebsiteElementList)
print("Found %s source website" % sourceWebsiteNum)
curSourceWebsiteElem = sourceWebsiteElementList[curIdx]
curSourceWebsite = curSourceWebsiteElem.text
print("curSourceWebsite=%s" % curSourceWebsite)输出是空的
curSourceWebsite=
去搞清楚
sourceWebsiteElementList = d.xpath('//*[@resource-id="results"]/android.view.View/android.view.View[1]/android.view.View[2]/android.view.View[2]').all()结果:
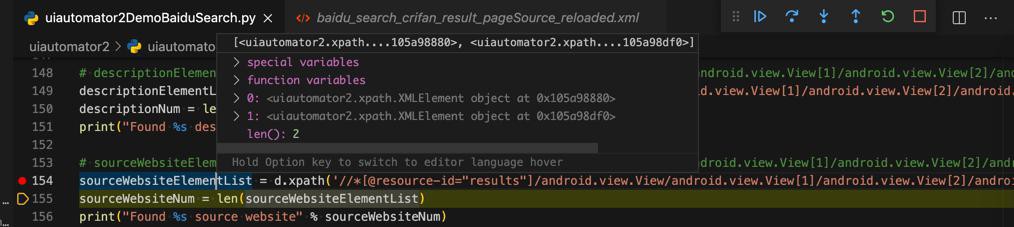
可以找到,但是只能找到2个
text依旧是空的
去看了看,写法没问题。但是为何是空?
去看了看
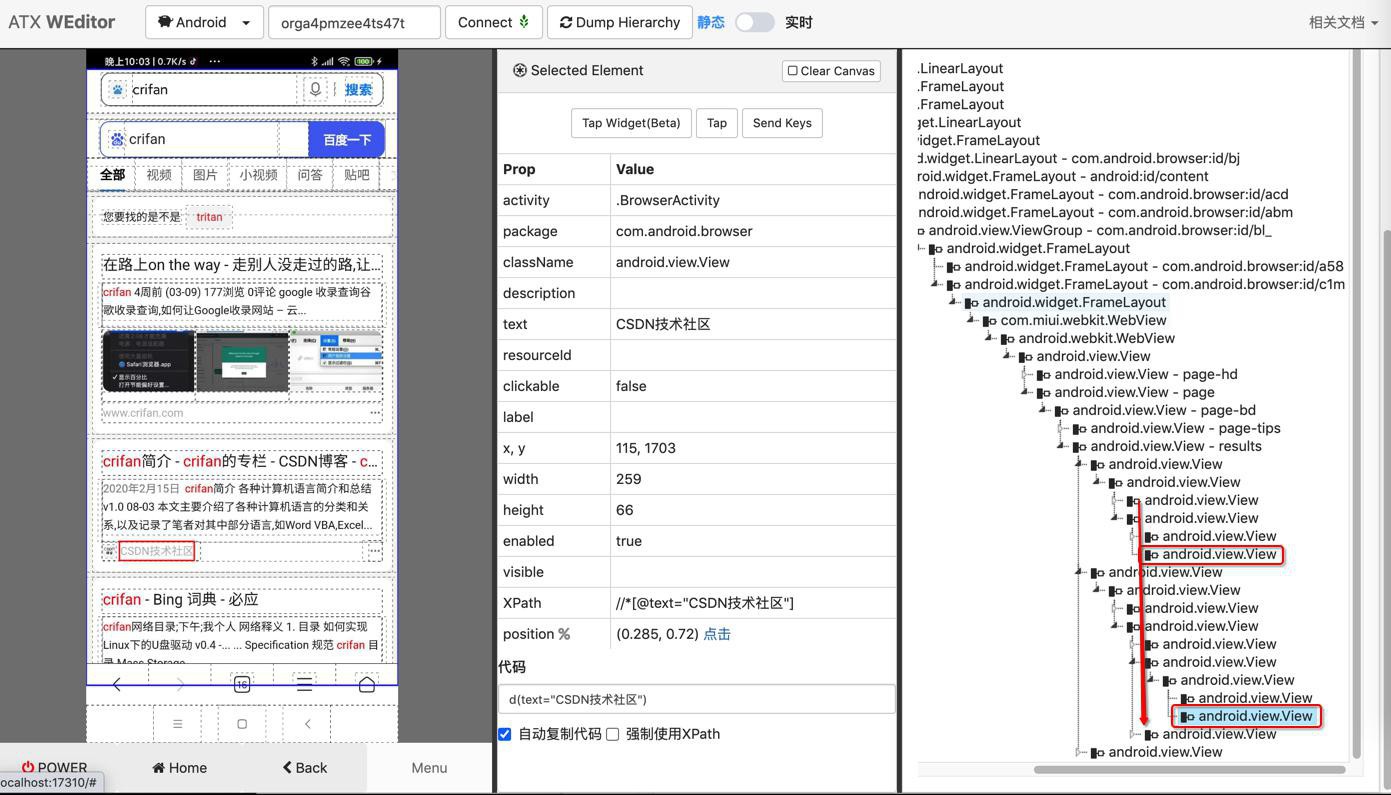
发现:竟然层级不同
算了,那就不去解决了。毕竟不规则的逻辑,不好处理。
以及,处理好了,此处只能找到2个,搜索的3个结果中,最后一个由于界面中只显示2个网站来源,所以是正常的。
会导致代码中不好处理。所以更加应该放弃,不去处理了。
【总结】
至此,此处用代码:
# Xpath chain search can find elements
titleButtonElementList = d.xpath("//*[@resource-id='results']//android.widget.Button[@clickable='true']").all()
titleButtonNum = len(titleButtonElementList)
print("Found %s search result title" % titleButtonNum)
# descriptionElementList = d.xpath("//*[@resource-id='results']/android.view.View[1]/android.view.View[1]/android.view.View[2]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]").all()
descriptionElementList = d.xpath("//*[@resource-id='results']/android.view.View/android.view.View[1]/android.view.View[2]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]/android.view.View[1]").all()
descriptionNum = len(descriptionElementList)
print("Found %s description" % descriptionNum)
# # sourceWebsiteElementList = d.xpath('//*[@resource-id="results"]/android.view.View/android.view.View[1]/android.view.View[2]/android.view.View[1]').all()
# sourceWebsiteElementList = d.xpath('//*[@resource-id="results"]/android.view.View/android.view.View[1]/android.view.View[2]/android.view.View[2]').all()
# sourceWebsiteNum = len(sourceWebsiteElementList)
# print("Found %s source website" % sourceWebsiteNum)
for curIdx, eachTitleButtonElement in enumerate(titleButtonElementList):
curNum = curIdx + 1
print("%s [%d/%d] %s" % ("-"*20, curNum, titleButtonNum, "-"*20))
# eachTitleButtonElemAttrib = eachTitleButtonElement.attrib
# print("title attrib: %s" % eachTitleButtonElemAttrib)
# curTitle = eachTitleButtonElemAttrib["text"]
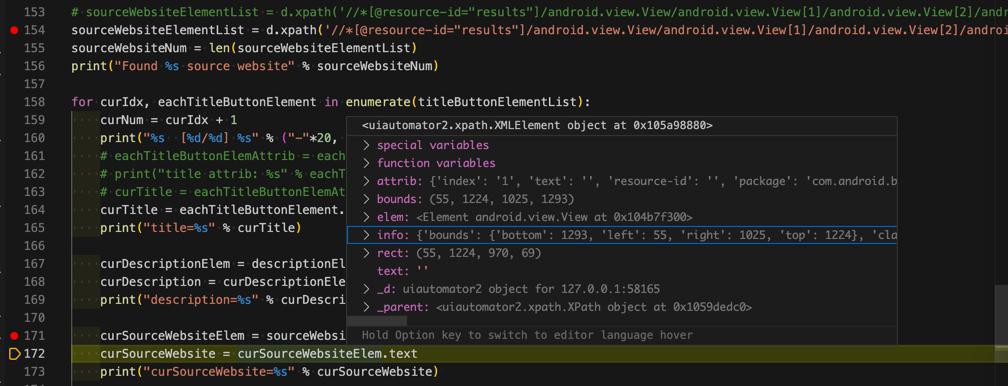
curTitle = eachTitleButtonElement.text
print("title=%s" % curTitle)
curDescriptionElem = descriptionElementList[curIdx]
curDescription = curDescriptionElem.text
print("description=%s" % curDescription)
# curSourceWebsiteElem = sourceWebsiteElementList[curIdx]
# curSourceWebsite = curSourceWebsiteElem.text
# print("curSourceWebsite=%s" % curSourceWebsite)可以搜索到title外,还能输出 描述
输出结果:
Found 3 search result title Found 3 description -------------------- [1/3] -------------------- title=在路上on the way - 走别人没走过的路,让别人有路可走 description=crifan 4周前 (03-09) 177浏览 0评论 google 收录查询谷歌收录查询,如何让Google收录网站 – 云... -------------------- [2/3] -------------------- title=crifan简介 - crifan的专栏 - CSDN博客 - crifan description=2020年2月15日crifan简介 各种计算机语言简介和总结 v1.0 08-03 本文主要介绍了各种计算机语言的分类和关系,以及记录了笔者对其中部分语言,如Word VBA,Excel... -------------------- [3/3] -------------------- title=crifan - Bing 词典 - 必应 description=crifan网络目录;下午;我个人 网络释义 1. 目录 如何实现Linux下的U盘驱动 v0.4 -... ... Specification 规范 crifan 目录 Mass Storage ...
效果:
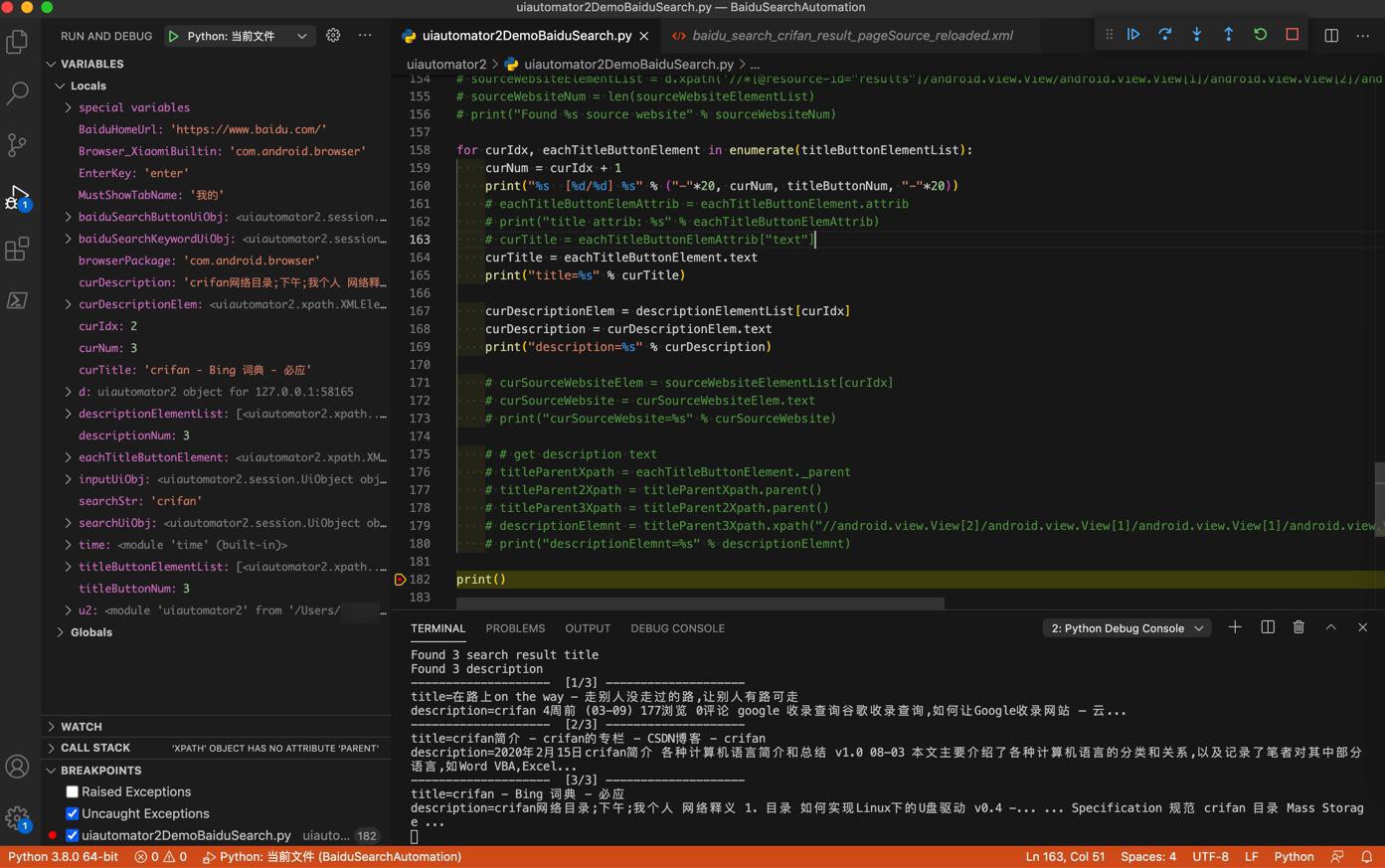
其中,由于来源网站source website的值,不规则,不好定位,放弃获取。
此处是即使获取到,也是只有2个(页面是就显示了2个)
且还都是空(没有获取到真正要的值)
所以懒得继续深究了。