折腾:
【未解决】如何破解大众点评网页爬取时的反扒验证verify.meituan.com
期间,去看看,是否可以设置对应的,合适的cookie,从而避免触发大众点评的反扒。
如何绕过反扒 verify.meituan.com
感觉此处或许是
“判断Header,比如如果User-agent是爬虫或者检测工具,或者非正常的浏览器,就禁止该次连接”
再去加上之前的cookie等参数
不过加之前,还是找个干净的浏览器环境,看看首次访问的request相关header等内容是啥
结果用Chrome调试期间,clear清除了:
- 所有的cookie和storage
- network
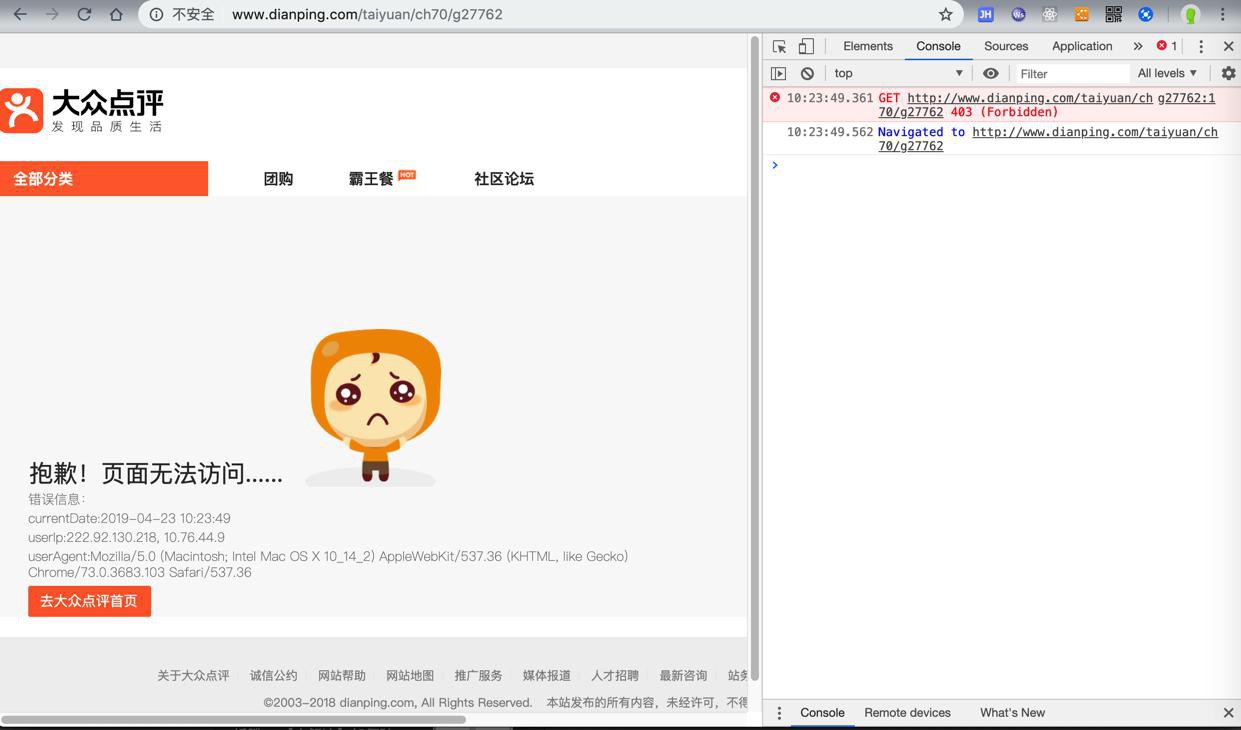
等内容,再去访问页面,竟然出现另外错误:
1 2 3 4 5 | 抱歉!页面无法访问......错误信息:currentDate:2019-04-23 10:23:49userIp:222.92.130.218, 10.76.44.9userAgent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36 |
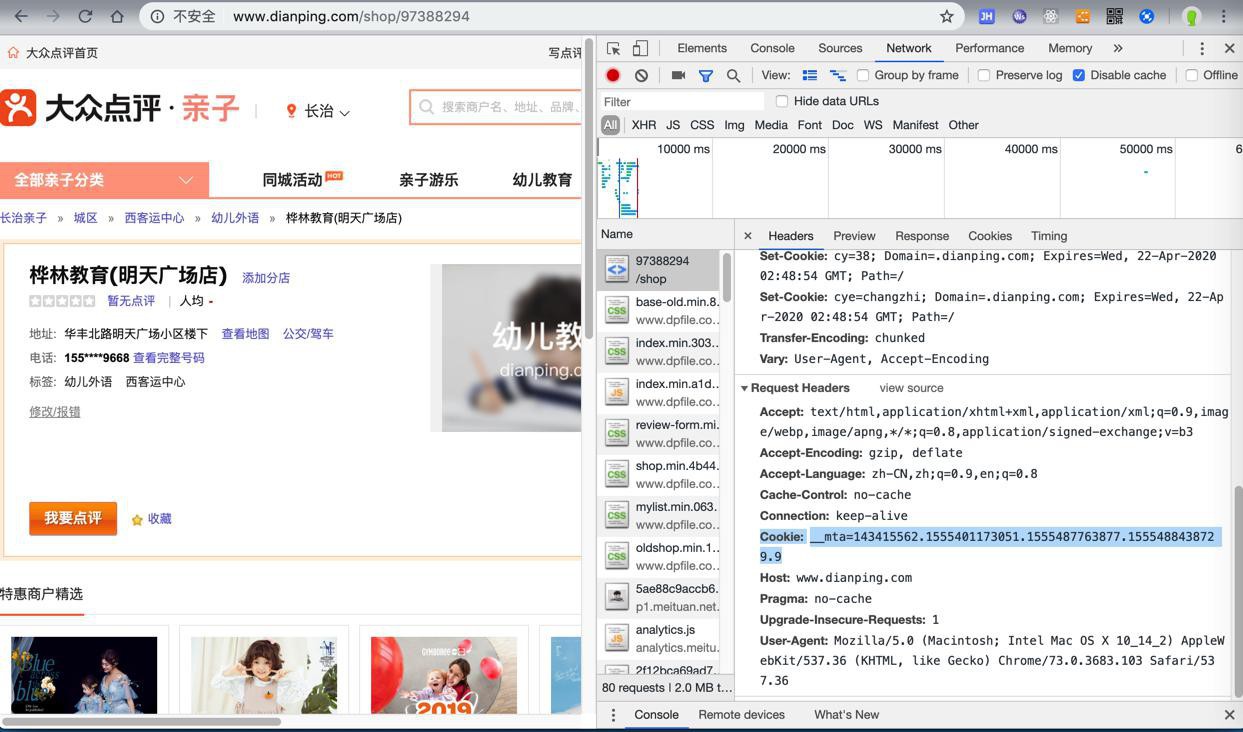
继续研究,发现首次访问页面,除了其他header,还会有个cookie
1 2 | Cookie:__mta=1434xxx01173051.1555487763877.1555488438729.9 |
不过再去试试其他页面,貌似没有这个Cookie
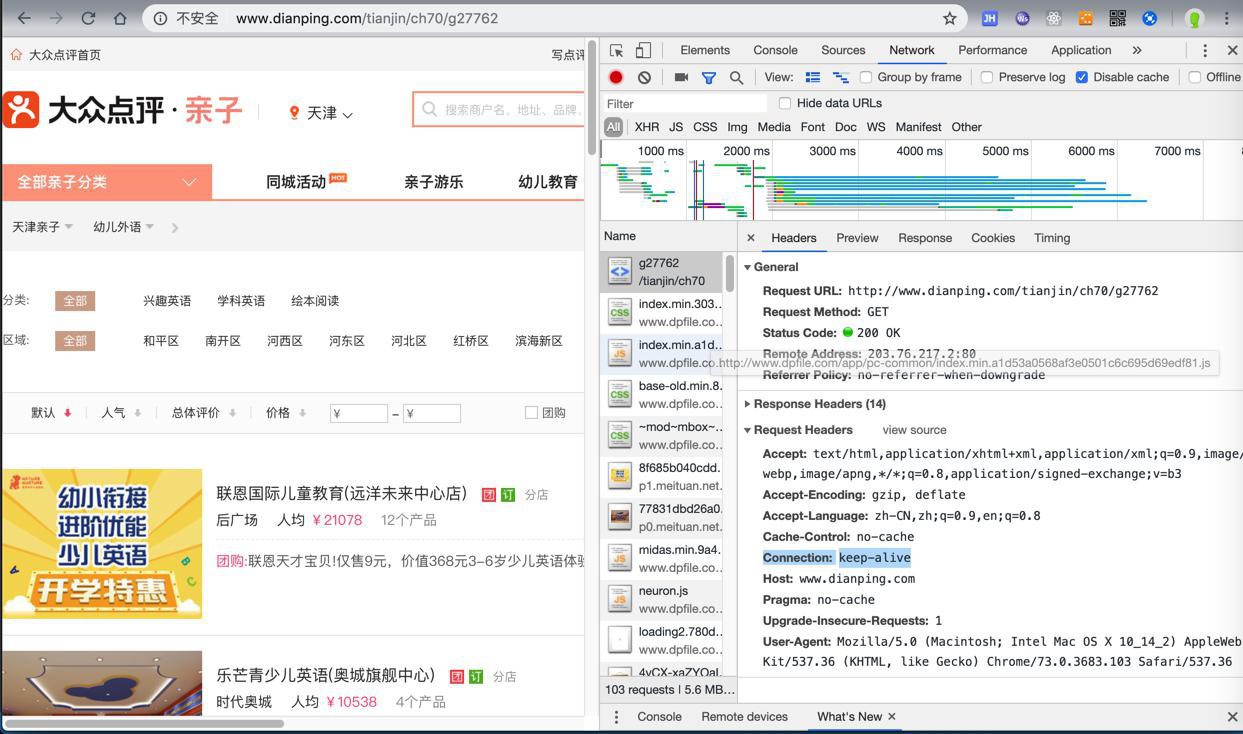
再去看看cookie。
对比了两次请求:
其中cookie部分:
1 2 3 4 5 | __mta=1434xxx01173051.1555487763877.1555488438729.9; aburl=1; cy=1; cye=shanghai; _hc.v=7f7a2906-c69c-60ba-1b77-4d80608c536b.1555988402; _lxsdk_cuid=16a4822cf0bc8-0d887e1d6c0a14-366f7e04-fa000-16a4822cf0bc8; _lxsdk=16a4822cf0bc8-0d887e1d6c0a14-366f7e04-fa000-16a4822cf0bc8; Hm_lvt_dbeeb675516927da776beeb1d9802bd4=1555988407; Hm_lpvt_dbeeb675516927da776beeb1d9802bd4=1555997885; _lxsdk_s=16a48b34b96-771-c57-e15%7Cuser-id%7C4aburl=1; cy=1; cye=shanghai; _hc.v=7f7a2906-c69c-60ba-1b77-4d80608c536b.1555988402; _lxsdk_cuid=16a4822cf0bc8-0d887e1d6c0a14-366f7e04-fa000-16a4822cf0bc8; _lxsdk=16a4822cf0bc8-0d887e1d6c0a14-366f7e04-fa000-16a4822cf0bc8; Hm_lvt_dbeeb675516927da776beeb1d9802bd4=1555988407; Hm_lpvt_dbeeb675516927da776beeb1d9802bd4=1555988407; _lxsdk_s=16a48b34b96-771-c57-e15%7Cuser-id%7C1 |
去用上其中的共同的部分:
1 | aburl=1; cy=1; cye=shanghai; _hc.v=7f7a2906-c69c-60ba-1b77-4d80608c536b.1555988402; _lxsdk_cuid=16a4822cf0bc8-0d887e1d6c0a14-366f7e04-fa000-16a4822cf0bc8;_lxsdk=16a4822cf0bc8-0d887e1d6c0a14-366f7e04-fa000-16a4822cf0bc8;Hm_lvt_dbeeb675516927da776beeb1d9802bd4=1555988407; |
去试试效果。
问题依旧:稍微调试了几个url,就verify了。
突然想到,难道PySpider中默认开启了cookie?
如果是,那么去禁止cookie试试?
【已解决】PySpider中如何禁止cookie
不过从
-》
看到了cookies是可以直接设置的。
所以自己此处把:
1 2 3 4 5 | constHeaders = { ... "Cookie": "aburl=1; cy=1; cye=shanghai; _hc.v=7f7a2906-c69c-60ba-1b77-4d80608c536b.1555988402; _lxsdk_cuid=16a4822cf0bc8-0d887e1d6c0a14-366f7e04-fa000-16a4822cf0bc8;_lxsdk=16a4822cf0bc8-0d887e1d6c0a14-366f7e04-fa000-16a4822cf0bc8;Hm_lvt_dbeeb675516927da776beeb1d9802bd4=1555988407;"...} |
去改为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | class Handler(BaseHandler): crawl_config = { "proxy": ProxyUri, ... "cookies": { "aburl": "1", "cy": "1", "cye": "shanghai", "_hc.v": "7f7a2906-c69c-60ba-1b77-4d80608c536b.1555988402", "_lxsdk_cuid": "16a4822cf0bc8-0d887e1d6c0a14-366f7e04-fa000-16a4822cf0bc8", "_lxsdk": "16a4822cf0bc8-0d887e1d6c0a14-366f7e04-fa000-16a4822cf0bc8", "Hm_lvt_dbeeb675516927da776beeb1d9802bd4": "1555988407", } } |
试试效果。问题依旧。
此处,调试发现,在确定换了IP
(先后调用get api确定IP已经换了)
结果还会出现:
1 2 | respUrl=https://verify.meituan.com/v2/web/general_page?action=spiderindefence&requestCode=0bff7476ccef4fffa67b5476ddc900cc&platform=1000&adaptor=auto&succCallbackUrl=https%3A%2F%2Foptimus-mtsi.meituan.com%2Foptimus%2FverifyResult%3ForiginUrl%3Dhttp%253A%252F%252Fwww.dianping.com%252Fbaoding%252Fch70%252Fg27762&theme=dianping |
->貌似其反扒可以识别IP代理背后的,我此处的地址?
现在感觉是:
Chrome调试发现:这种shop的detail页面,貌似需要一点其他参数才能进来
-》否则很容易就出错了:
所有cookie都清除后
容易出现报错页面
继续调试,发现清除cookie后:
有时候返回出错
有时候还是可以访问shop页的,且有个cookie:
1 | Cookie:_lxsdk_s=16a4946bb7c-9d8-b5c-c47%7C%7C1 |
偶尔又是:
1 | Cookie:_lxsdk_s=16a4949e875-db8-d33-123%7C%7C2 |
Safari中是:
1 | _lxsdk_s=16a494c1a16-58a-a82-c0e%7C%7C1 |
再多次请求是:
1 2 3 | _lxsdk_s=16a494c1a16-58a-a82-c0e%7C%7C4_lxsdk_s=16a494c1a16-58a-a82-c0e%7C%7C7_lxsdk_s=16a494c1a16-58a-a82-c0e%7C%7C10 |
好像每次加3
那此处只用1即可
1 2 3 4 5 6 7 8 9 10 | self.crawl( shopUrl, callback=self.shopDetailCallback, headers=self.genCurHeaders(), cookies={ "_lxsdk_s": "16a4946bb7c-9d8-b5c-c47%7C%7C1", # chrome # "_lxsdk_s": "16a494c1a16-58a-a82-c0e%7C%7C1", # safari }, save=curInfo, ) |
问题依旧:
还是会出现verify,还是刷新一下又好了。
先不管,先去PySpider运行试试效果
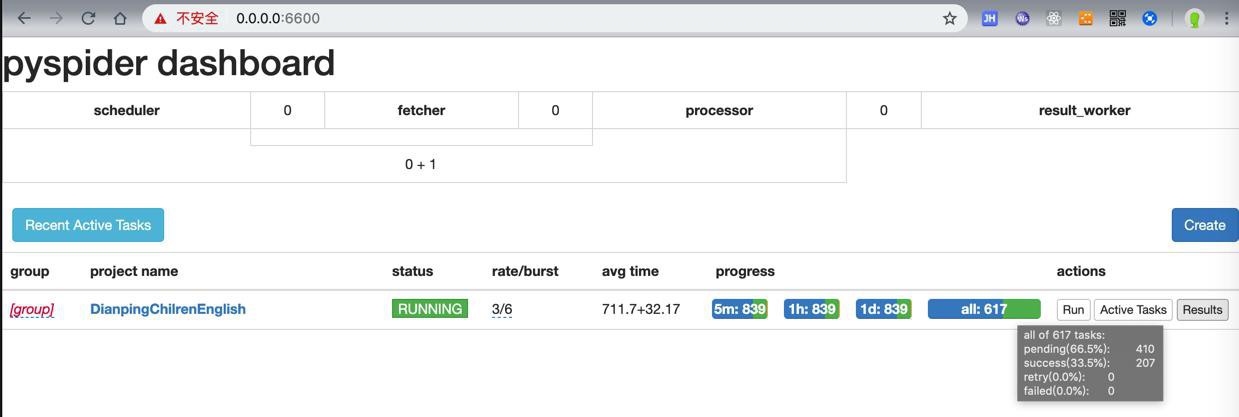
爬了几十秒后,还是各种问题了:
结果中要爬的字段都是空
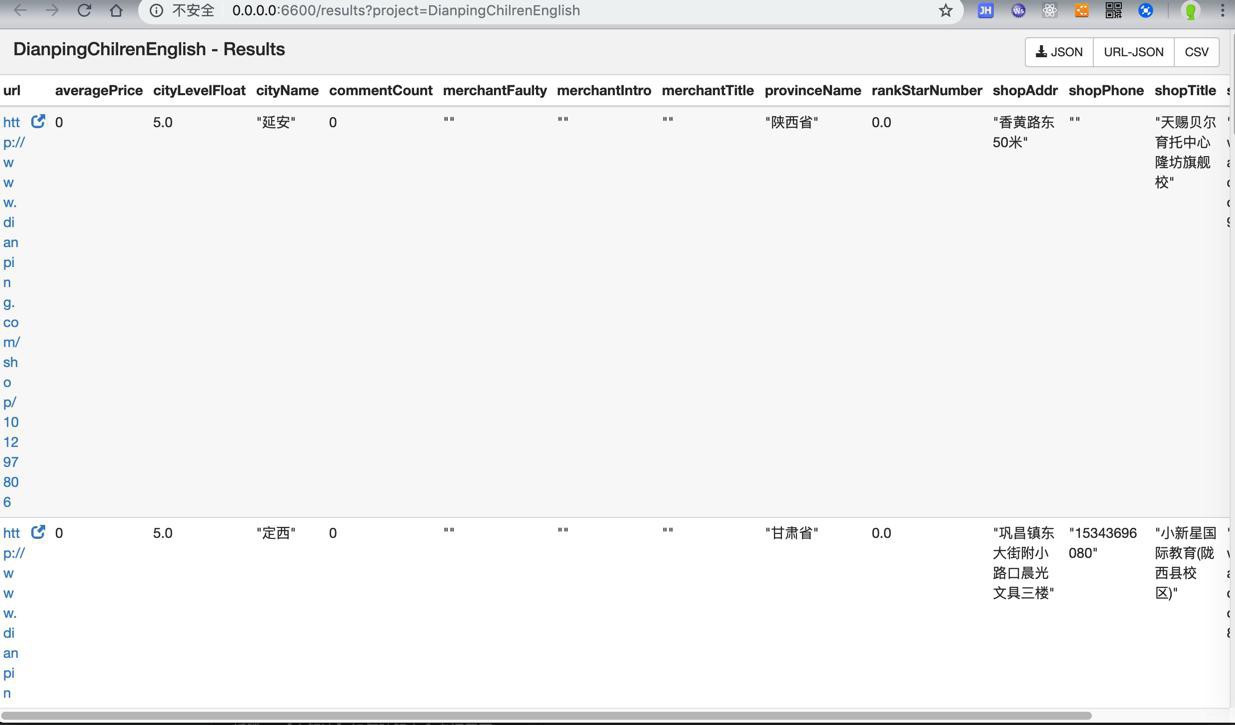
->说明页面没有获取到内容
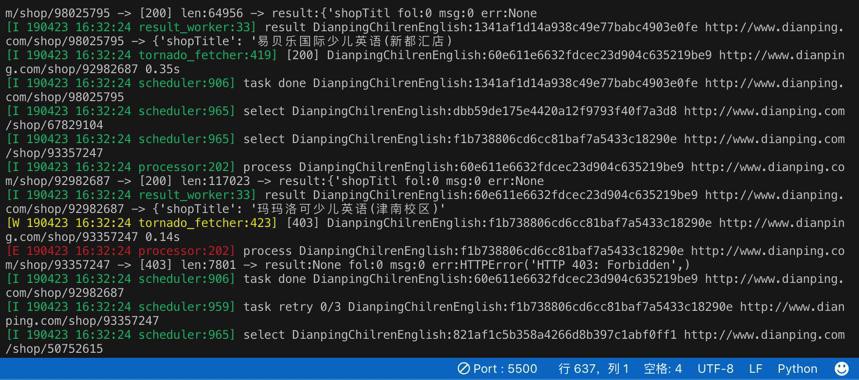
log出错:
1 2 3 4 5 6 | [W 190423 16:32:24 tornado_fetcher:423] [403] DianpingChilrenEnglish:f1b738806cd6cc81baf7a5433c18290e http://www.dianping.com/shop/93357247 0.14s[E 190423 16:32:24 processor:202] process DianpingChilrenEnglish:f1b738806cd6cc81baf7a5433c18290e http://www.dianping.com/shop/93357247 -> [403] len:7801 -> result:None fol:0 msg:0 err:HTTPError('HTTP 403: Forbidden',) |
再去加回来:
“Connection”: “keep-alive”,
结果:
好像效果还行。
不过突然:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | [E 190423 16:46:05 base_handler:203] HTTP 599: LibreSSL SSL_connect: SSL_ERROR_SYSCALL in connection to verify.meituan.com:443 Traceback (most recent call last): File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 196, in run_task result = self._run_task(task, response) File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 175, in _run_task response.raise_for_status() File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/pyspider/libs/response.py", line 172, in raise_for_status six.reraise(Exception, Exception(self.error), Traceback.from_string(self.traceback).as_traceback()) File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/six.py", line 692, in reraise raise value.with_traceback(tb) File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/pyspider/fetcher/tornado_fetcher.py", line 378, in http_fetch response = yield gen.maybe_future(self.http_client.fetch(request)) File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/tornado/httpclient.py", line 102, in fetch self._async_client.fetch, request, **kwargs)) File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/tornado/ioloop.py", line 458, in run_sync return future_cell[0].result() File "/Users/crifan/.local/share/virtualenvs/crawler_dianping_com-sGcMRJTS/lib/python3.6/site-packages/tornado/concurrent.py", line 238, in result raise_exc_info(self._exc_info) File "<string>", line 4, in raise_exc_info Exception: HTTP 599: LibreSSL SSL_connect: SSL_ERROR_SYSCALL in connection to verify.meituan.com:443 |
刷新后,还是之前verify错误:
1 2 | respUrl=https://verify.meituan.com/v2/web/general_page?action=spiderindefence&requestCode=933f1b20a82a487480f4c7cbdce391cc&platform=1000&adaptor=auto&succCallbackUrl=https%3A%2F%2Foptimus-mtsi.meituan.com%2Foptimus%2FverifyResult%3ForiginUrl%3Dhttp%253A%252F%252Fwww.dianping.com%252Fshop%252F67535963&theme=dianping |
Safari调试
看到cookie有:
1 | Cookie: _lxsdk_s=16a494c1a16-58a-a82-c0e%7C%7C18; aburl=1; cy=38; cye=changzhi; wed_user_path=27762|0; _hc.v="\"1396e0a9-49ff-43e7-9869-4e8b4fddf846.1556007886\""; _lxsdk=16a494c1d87c8-0b48673994cbc1-481c3400-fa000-16a494c1d87c8; _lxsdk_cuid=16a494c1d87c8-0b48673994cbc1-481c3400-fa000-16a494c1d87c8 |
想办法加进来一些。
- cye=changzhi;
- 说明不是固定的shanghai
- 看出来是:changzhi 江西省 吉安
- -》看来是 http://www.dianping.com/suzhou/ch70/g27762中的suzhou,即cityEnName
- wed_user_path=27762|0;
- 27762是
- CategoryLevel2ChildEnglish = “g27762” # 幼儿教育 -> 幼儿外语
- 中的27762
问题依旧。
转载请注明:在路上 » 【未解决】PySpider中尝试设置Cookie避免大众点评的反扒