折腾:
【未解决】pandas输出结果到excel文件中且第一行是其他特殊内容
期间,已经可以把数据用pandas输出到excel了
但是希望此处额外加上第一行,特殊的格式
类似于这种:
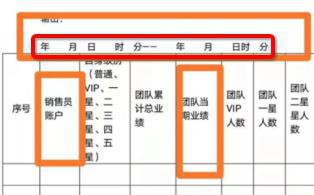
去找找看,是否有合适的办法
pandas output excel first special row
突然感觉:或许是:直接用第一行输出值,即可?
pandas write excel first special row
算了,去试试
另外,看到
df = pd.read_excel('file.xlsx',
sheet_name ='Data_sheet',
header=None,
index_col=False)好像是可以指定第一列?
去找找,是否有此参数
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None, storage_options=None)
有我们希望的:startrow=0
如果是这样,需要再用pandas(或openpyxl等)去打开excel,再去写入第一行的值,也挺麻烦的。
所以还是一次性输出比较好
python datetime year month day
datetime.year Between MINYEAR and MAXYEAR inclusive. datetime.month Between 1 and 12 inclusive. datetime.day Between 1 and the number of days in the given month of the given year. datetime.hour In range(24). datetime.minute In range(60). datetime.second In range(60). datetime.microsecond In range(1000000).
去试试:
【部分解决】pandas输出excel报错:If using all scalar values, you must pass an index
虽然解决了语法,但是输出结果不对。
算了,暂时换个方式,显示数据:
summaryData = {
"销售员账户": personList,
"团队当前业绩": moneyList,
}
outputDf = pd.DataFrame(data=summaryData)
outputSheetName = "%s年%s月%s日%s时%s分 -- %s年%s月%s日%s时%s分" % \
(beginYear, beginMonth, beginDay, beginHour, beginMinute, endYear, endMonth, endDay, endHour, endMinute)
outputDf.to_excel(OutputFullPath, sheet_name=outputSheetName)有警告:
/Users/crifan/.local/share/virtualenvs/TeamSaleStatistic-VIYlkgMt/lib/python3.9/site-packages/openpyxl/workbook/child.py:99: UserWarning: Title is more than 31 characters. Some applications may not be able to read the file
warnings.warn("Title is more than 31 characters. Some applications may not be able to read the file")输出:
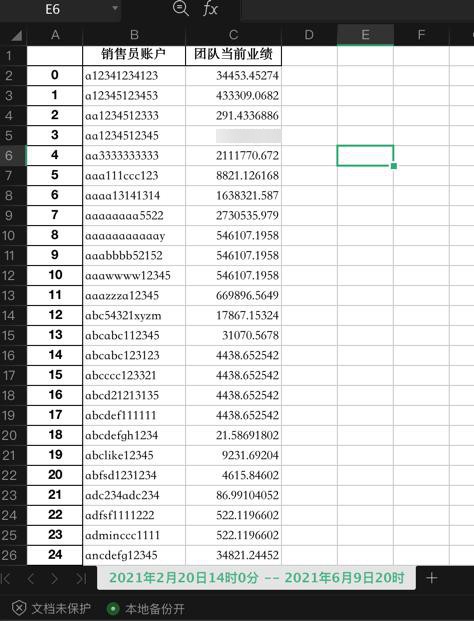
2021年2月20日14时0分 -- 2021年6月9日20时
sheet的name,丢失了最后的分
改为:
outputSheetName = "%s年%s月%s日%s时%s分-%s年%s月%s日%s时%s分" % \
结果:
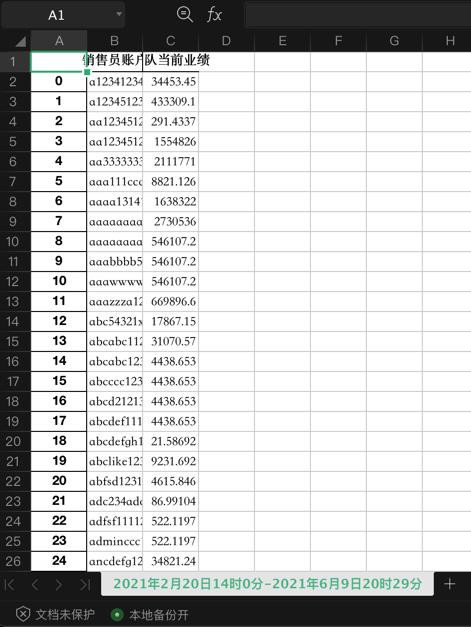
sheet的name正常了
至少可以显示完整了:2021年2月20日14时0分-2021年6月9日20时29分