折腾:
【未解决】用Python实现解析excel计算业绩统计并打包成可执行文件
期间,需要去获取每一行的数据。
pandas get each row
但是此处没有df=dateframe
所以问题变成:
读取excel后,得到是什么变量
看看
Read an Excel file into a pandas DataFrame.
就是df
for index, row in dataFrame.iterrows(): print(row)
去试试
for curIdx, curRow in saleDf.itertuples():
报错:
发生异常: ValueError too many values to unpack (expected 2)
看来是:
for curIdx, curRow in saleDf.iterrows(): print(curIdx) print(curRow)
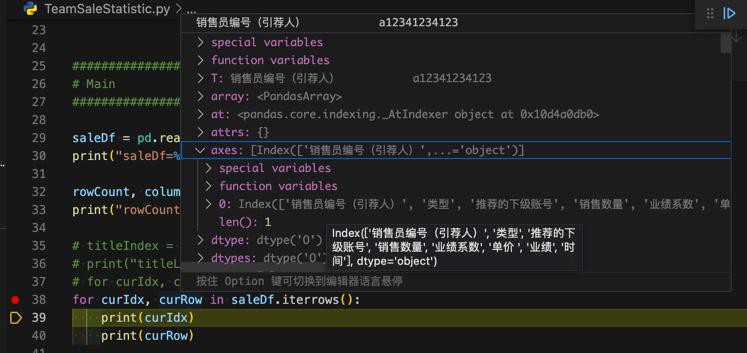
输出:
0 销售员编号(引荐人) a12341234123 类型 销售 推荐的下级账号 a12341234121 销售数量 0 业绩系数 0 单价 0.15 业绩 2584.008955 时间 2021-04-08 19:57:50 Name: 0, dtype: object 1 销售员编号(引荐人) a12345123453 类型 销售 推荐的下级账号 jgxhxhyq5555 销售数量 0 业绩系数 0 单价 0.15 业绩 1279.022171 时间 2021-04-22 08:41:21 Name: 1, dtype: object
后来发现弄错文件了。
改为:
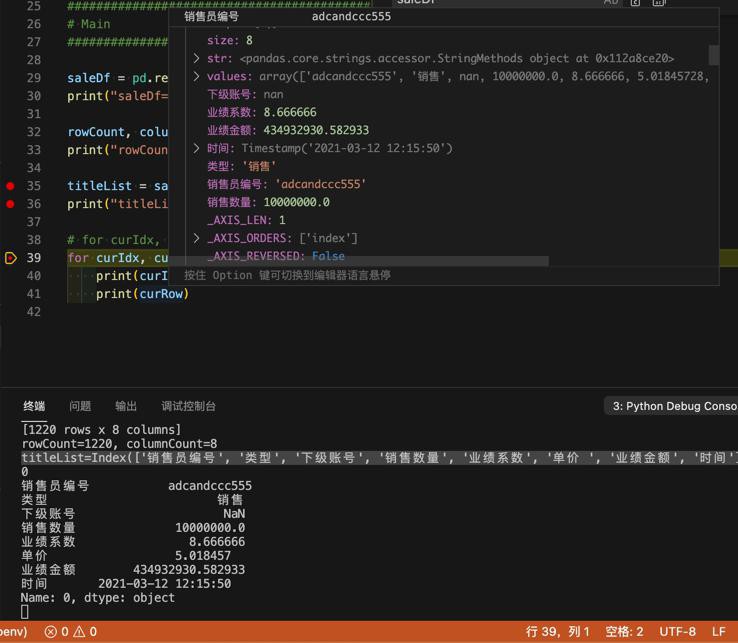
saleDf = pd.read_excel(io=SaleFullPath, engine="openpyxl")
输出:
rowCount=1220, columnCount=8 0 销售员编号 adcandccc555 类型 销售 下级账号 NaN 销售数量 10000000.0 业绩系数 8.666666 单价 5.018457 业绩金额 434932930.582933 时间 2021-03-12 12:15:50 Name: 0, dtype: object 1 销售员编号 yang12345ccc 类型 销售 下级账号 NaN 销售数量 40000.0 业绩系数 8.6666 单价 20.084027 业绩金额 6962409.110468 时间 2021-05-29 10:59:50 Name: 1, dtype: object
其中标题 第一行的内容是:
titleList = saleDf.columns
print("titleList=%s" % titleList)输出:
titleList=Index(['销售员编号', '类型', '下级账号', '销售数量', '业绩系数', '单价 ', '业绩金额', '时间'], dtype='object')
继续调试,发现每一个dateframe,自动帮忙 载入值,确定好类型了:
不过,也要看看,如何引用每一行中的每一列的数据,毕竟直接用变量引用,好像不对
即没法写成:
curRow.中文列名
pandas get row value
获取数据
In [30]: df.loc[dates[0], 'A'] Out[30]: 0.46911229990718628 In [37]: df.iloc[1, 1] Out[37]: -0.17321464905330858
In [3]: sub_df Out[3]: A B 2 -0.133653 -0.030854 In [4]: sub_df.iloc[0] Out[4]: A -0.133653 B -0.030854 Name: 2, dtype: float64 In [5]: sub_df.iloc[0]['A'] Out[5]: -0.13365288513107493
去试试
for curIdx, curRow in saleDf.iterrows():
print(curIdx)
print(curRow)
curRowDict = saleDf.iloc[curIdx]
saleId = curRowDict["销售员编号"]
saleMoney = curRowDict["业绩金额"]
print("saleId=%s, saleMoney=%s" % (saleId, saleMoney))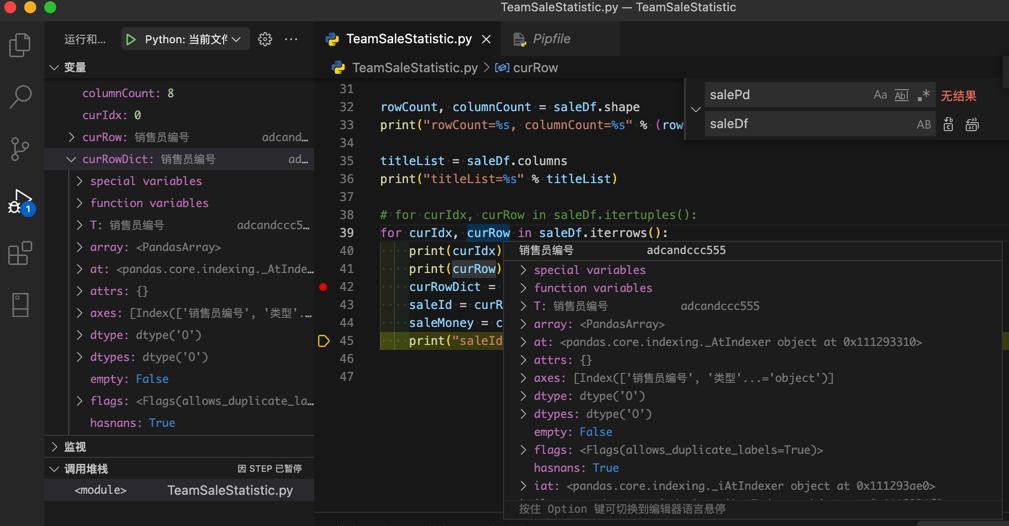
发现此处是:
curRow和curRowDict一样的
即:
- for curIdx, curRow in saleDf.iterrows() 中的curRow
- saleDf.iloc[curIdx]
是一致的。
即:
for curIdx, curRow in saleDf.iterrows()
后的curRow,其实可以当做一个dict了
【总结】
此处:
for curIdx, curRow in saleDf.iterrows(): print(curIdx) print(curRow)
然后想要获取到每个row的每一列的值的写法是:
curRow["columnName"]
即可。
或者是:
curRowDict = saleDf.iloc[curIdx] saleId = curRowDict["columnName"]
均可。
转载请注明:在路上 » 【已解决】pandas中如何获取读取了excel后的每一行的数据