自然语言理解,也就是人或机器理解人类语言
两种不同定义
- 一种基于表征:representation
- 语义角度
- 系统根据输入的语言产生相应的内部表征
- 这个过程也称为语义接地(semantic grounding)
- 另一种基于行为
- 语用角度
- 系统根据输入的语言采取相应的动作
- 比如,有人说“给我拿一杯茶”,机器人按照命令做了,就认为它理解了人的语言
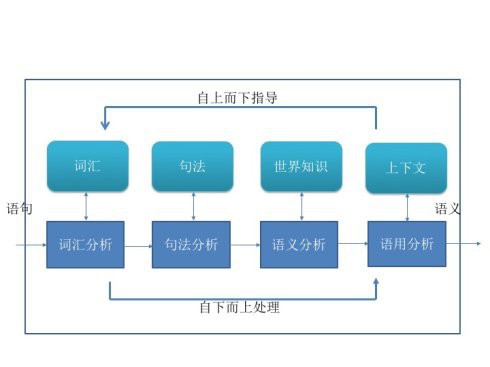
功能角度:语言理解过程,可以是人脑,也可以是计算机系统
- 输入:自然语言的语句
- 输出:语句的语义表征,包括:
- 词汇分析:将输入语句中的单词映射到单词的语义表征上。
- 每一个单词都有丰富的语义。
- 一个单词的语义包含了它的相关概念,以及使用方法。
- 一个语言的常用词汇量一般在5万到10万的范围。
- 句法分析:根据句法规则判断输入语句中的单词之间的语法关系,得到语句的语法表征。
- 句法既有一定的规律,也有大量的例外。
- 一个语言的语法是一个非常复杂的规则体系。
- 语义分析:基于单词的语义表征、语句的语法表征,根据系统中的世界知识的表征,构建语句的(可能是多个)语义表征。
- 语用分析:基于语句的语义表征,根据系统中的上下文,确定语句具体语义表征
- 核心:听到一句话或者读到一句话,把它映射到系统的一个表征上面。
- 这个映射是一个多对多的映射
- 必然产生:
- 多义性(ambiguity):一句话可以有多个意思
- 举例:“I saw a girl with a telescope”一句话表示两个不同的意思
- 多样性(variability):一个意思有多种方法表达
- 举例:“distance between sun and earth”和“how far is sun from earth”两句话表示的是同一个意思
人的自然语言理解:
- 整个大脑都在参与,是一个非常复杂的过程
- 有两个脑区和语言密切相关:布洛卡区(Broca’s area)和韦尼克区(Wernicke’s area)
- 有限状态机:
- 对话中要完成的任务一般可以由一个有限状态机表示,其中状态表示完成任务的一个阶段
- 有一个目标状态,若干个初始状态
- 从一个初始状态到达目标状态往往有多个路径,甚至许多路径。
- 完成对话对应着从初始状态出发,通过一条路径,到达目标状态。
- 举例:比如说订机票,需要通过与对方交流,提供相关信息,每一个状态表示目前为止明确的信息。
- 当任务简单的时候,有限状态机的状态数不多,模型的复杂度不高。但是,当任务变得复杂时,状态数和模型的复杂度会爆炸式地增加。
计算机上达到和人同等的对话能力还非常困难。
现在的技术,一般是数据驱动,基于机器学习的。
对话技术分单轮对话和多轮对话
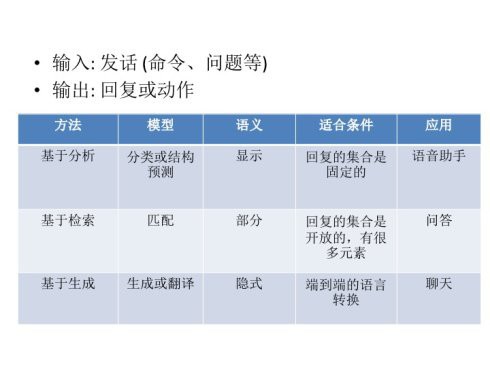
- 单轮对话,实现方法:
- 基于分析的:
- 把问题定义为分类和结构预测。
- 给定自然语言的发话,将发话转为内部的表征,之后产生系统的回复或动作。
- 这种方法有显式的内部语义表征,适合于命令型的对话,在语音助手和智能音箱等应用上被广泛使用。
- 基于检索的
- 把问题定义为匹配
- 给定自然语言的发话,将发话与内部的文本进行匹配,之后将匹配到的文本返回,作为回答。
- 这种方法,以文本(非结构化数据)形式拥有内部语义表征,可以做问答型的对话,在问答系统等应用被广泛使用。
- 基于生成的
- 把问题定义为文本的转换或翻译
- 给定自然语言的发话,一般利用深度学习模型,自动生成相应的回复。
- 这种方法不拥有显式的语义表征,适合于自动生成回答的场景,比如,邮件的智能回复。
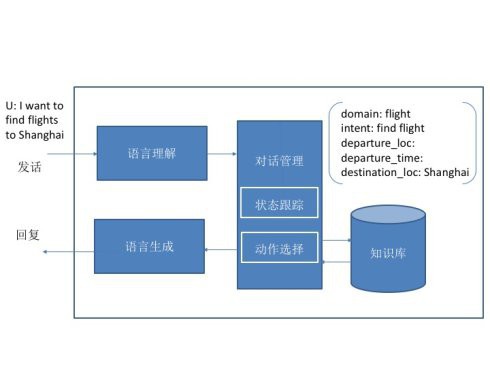
- 多轮对话系统
- 用到的技术:
- 深度学习
- 端到端的训练和表征学习是深度学习的主要特点
- 正是这些特点使深度学习成为自然语言处理的强大工具,对话也不例外
- 强化学习
- 适合于系统与环境互动并在这个过程中学习的贯序决策过程(sequential decision process)问题
- 多轮对话正是其应用
- 模型:
- 神经符号机(Neural Symbolic Machines)
- 从知识图谱三元组中找到答案
- 回答像“美国最大的城市是哪里?”这样的问题
- 模型:序列对序列(sequence-to-sequence)模型
- 将问题的单词序列转换成命令的序列
- 命令的序列是LISP语言的程序
- 最大特点是序列对序列模型表示和使用程序执行的变量,用附加的键–变量记忆(key-variable memory)记录变量的值,其中键是神经表征、变量是符号表征。
- 模型的训练是基于强化学习(策略梯度法)的端到端的学习。
- 神经查询器(Neural Enquirer)、符号查询器( Symbolic Enquirer),连接查询器(Coupled Enquirer )三个模型
- 用于自然语言的关系数据库查询
- 可以从奥林匹克运动会的数据库中找答案,回答“观众人数最多的奥运会的举办城市的面积有多大?”这样的问题。
- 问答系统包括语言处理模块、短期记忆、长期记忆、查询器,语言处理模块又包括编码器和解码器。
- 基于层次化深度强化学习(hierarchical reinforcement learning)的对话策略学习方法
- 可以通过多轮对话帮助用户做旅行安排,包括预订机票、订酒店
转载请注明:在路上 » 【整理】NLP 资料 知识