折腾:
【未解决】Python处理发布印象笔记帖子到WordPress后的部分细节优化
期间,发现之前帖子的代码,发布后,丢失了格式:
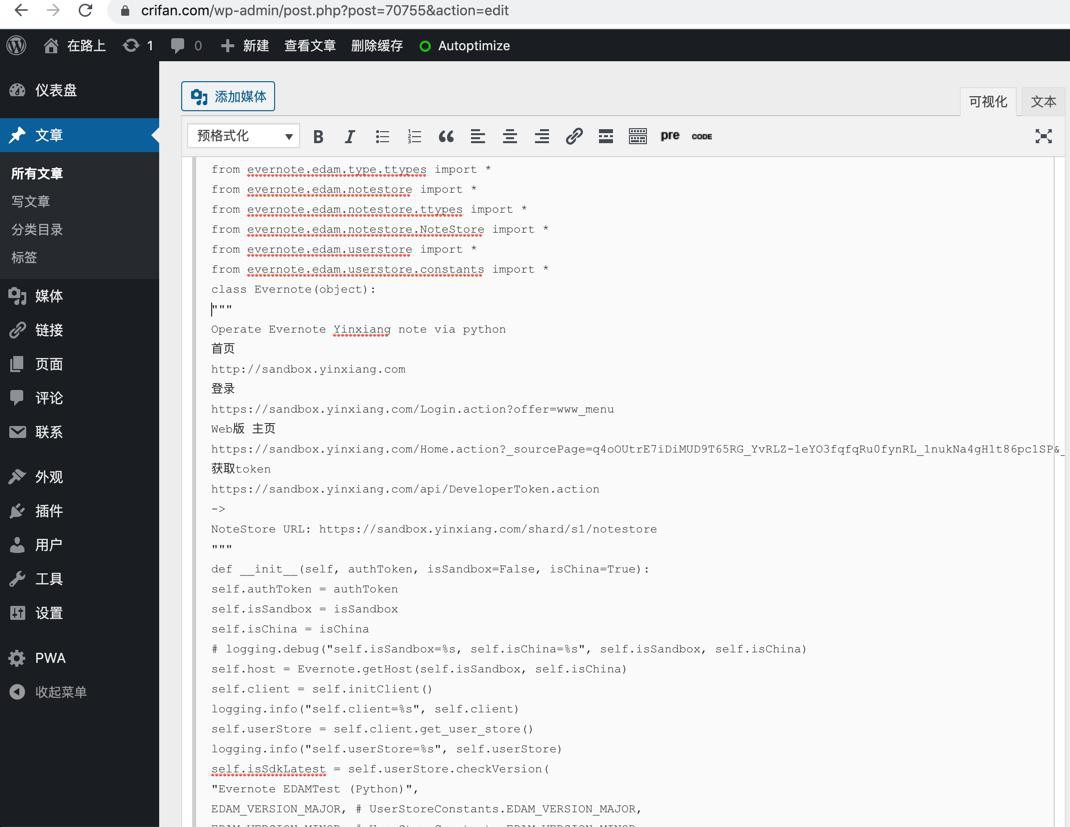
去看原贴是:

是有缩进的。
发布后,缩进都丢失了。
感觉是:soup转str,丢失了?
去找找原因
去调试,看看中间过程的html是什么样的
先去看看后台的html:
from evernote.edam.userstore.constants import * class Evernote(object): """ Operate Evernote Yinxiang note via python 首页 http://sandbox.yinxiang.com 登录 https://sandbox.yinxiang.com/Login.action?offer=www_menu Web版 主页
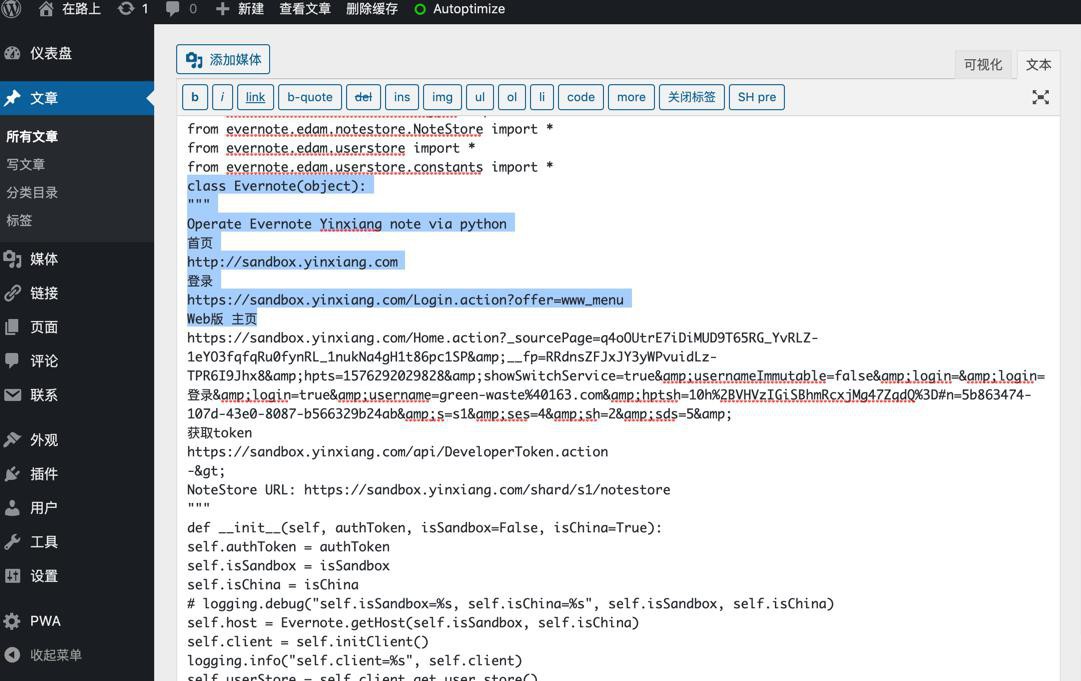
完全没有缩进了。
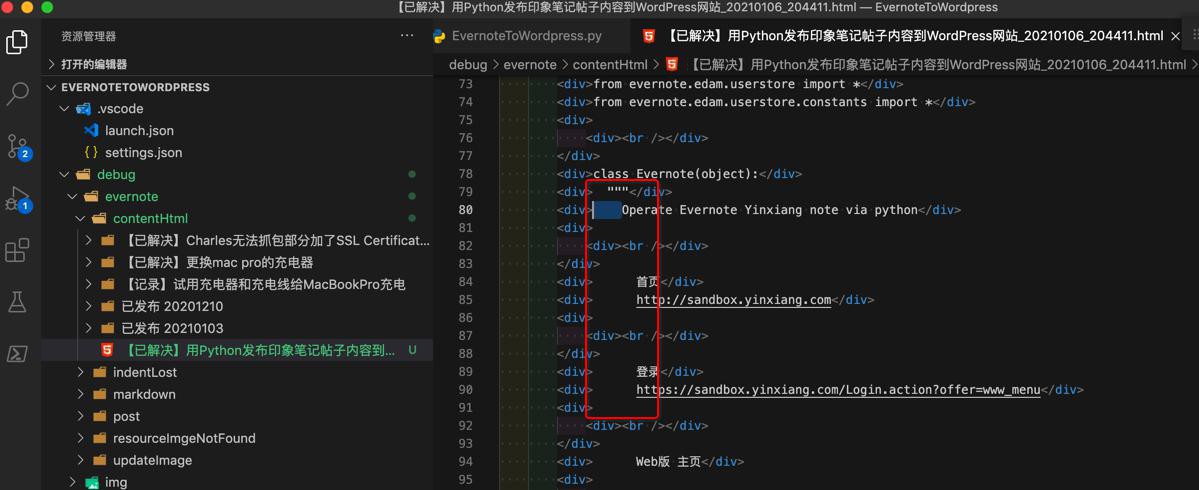
调试发现,原先是有空格的:
不过是div包括的:
<div>class Evernote(object):</div> <div> """</div> <div> Operate Evernote Yinxiang note via python</div> <div> <div><br /></div> </div> <div> 首页</div> <div> http://sandbox.yinxiang.com</div> <div> <div><br /></div>
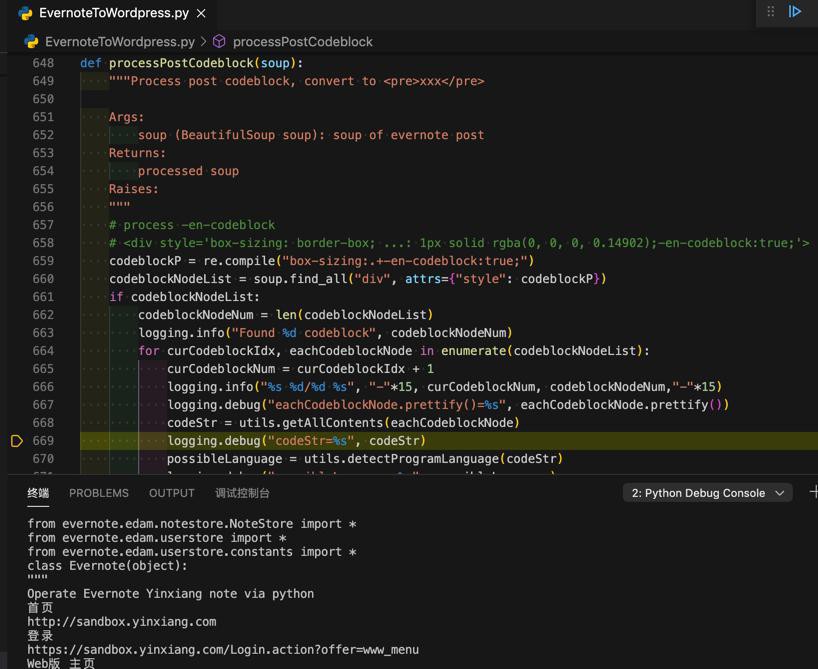
继续调试,看看处理后是什么样的
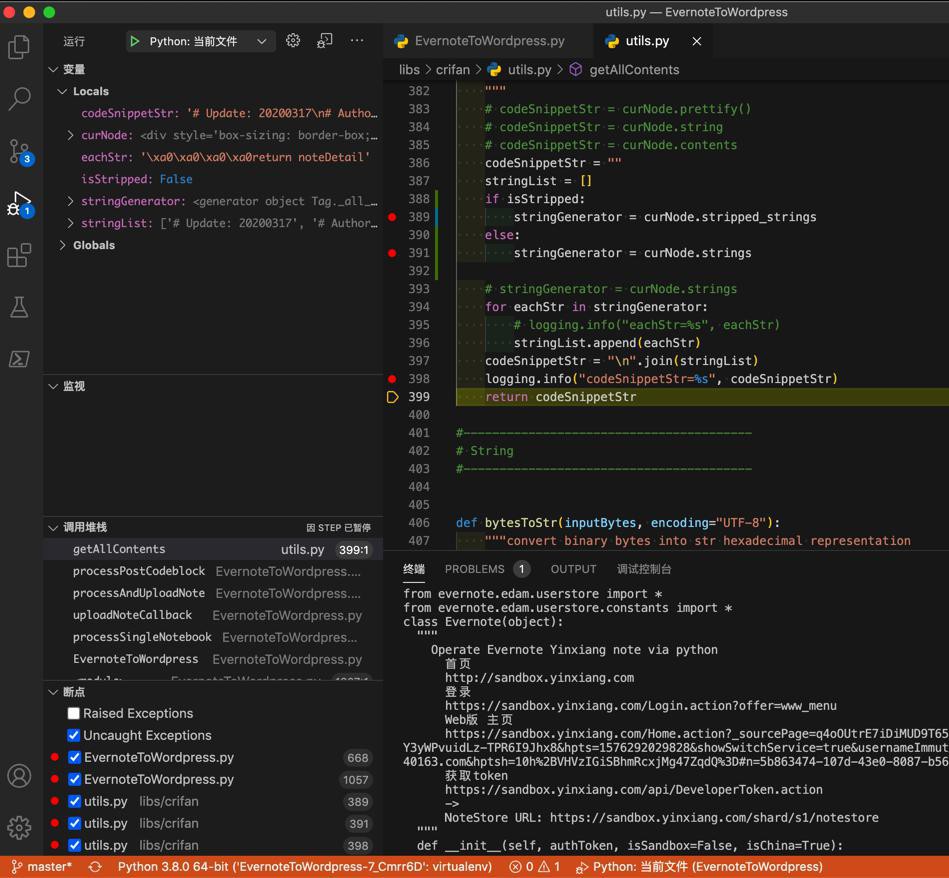
codeStr = utils.getAllContents(eachCodeblockNode)
代码输出:
。。。 from evernote.edam.userstore.constants import * class Evernote(object): """ Operate Evernote Yinxiang note via python 首页 http://sandbox.yinxiang.com 登录 。。。
很明显,就没有缩进了:
那去:
【已解决】BeautifulSoup中如何保留div内的字符串且保留空格等缩进
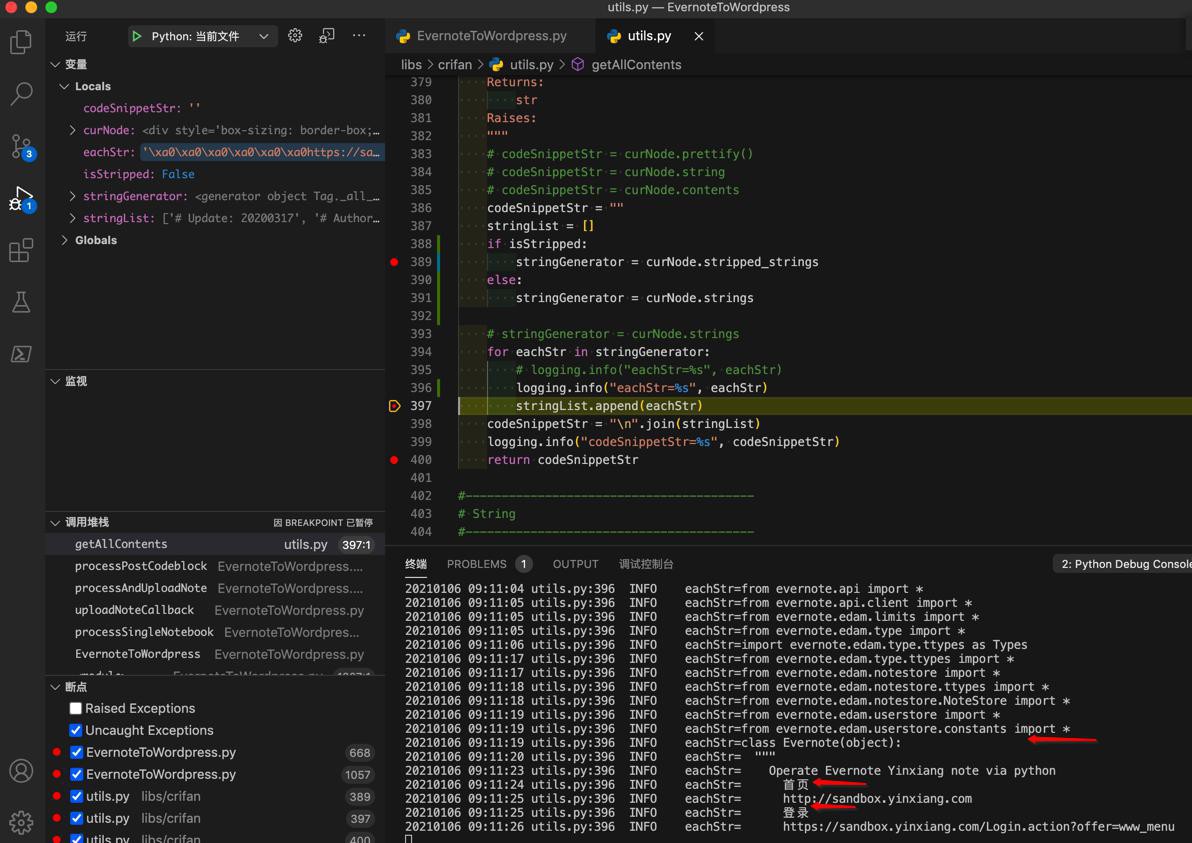
然后整体字符串是:
有保留缩进的。
但是和原始内容比
中间的空行丢失了
所以再去想办法看看
“如果tag中包含多个字符串 [2] ,可以使用 .strings 来循环获取:
输出的字符串中可能包含了很多空格或空行,使用 .stripped_strings 可以去除多余空白内容:”
此处是没有我们要的 空行啊
还是少了空行。
突然意识到:
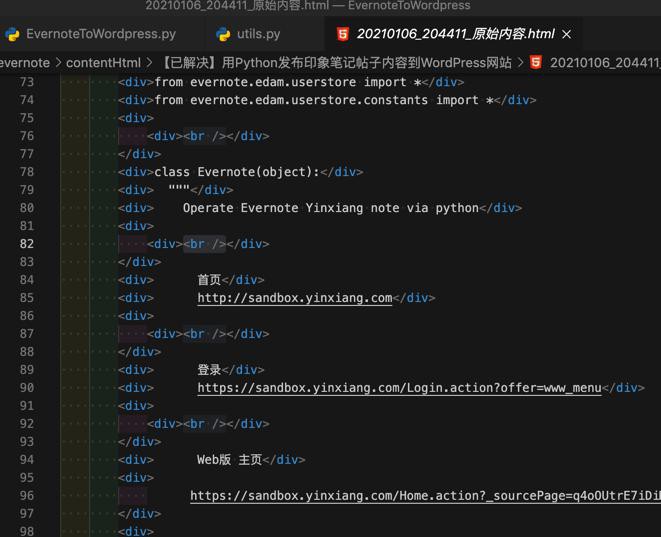
此次是印象笔记的笔记中的html是特殊的:
<div> <div><br /></div> </div>
用来表示空行的。
所以,需要此处特殊处理才可以。
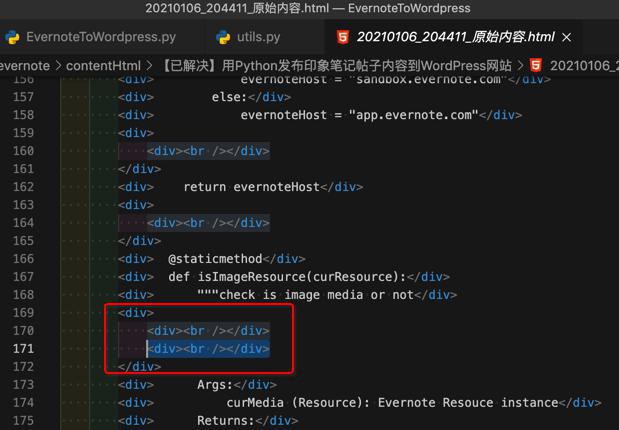
以及用:
<div> <div><br /></div> <div><br /></div> </div>
表示2行。
所以要去写代码处理掉。
后来继续调试,至少好消息是:
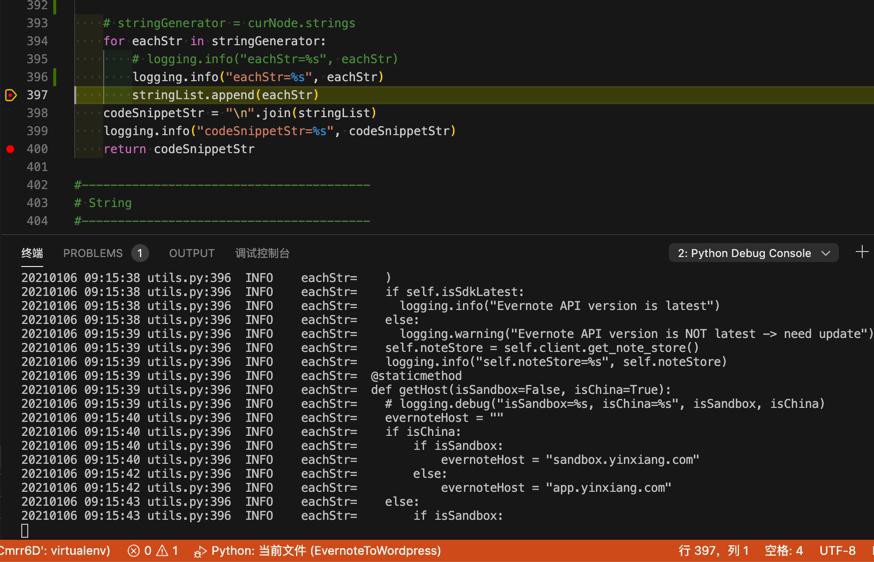
后续内部的空格是可以保留的。
用代码:
# convert
to newline
eachCodeblockNode = convertDivBrToNewline(eachCodeblockNode)
def convertDivBrToNewline(enCodeblockSoup):
"""Convert
<div>
<div><br /></div>
</div>
<div>
<div><br /></div>
<div><br /></div>
</div>
to:
<div>\n</div>
<div>\n\n</div>
Args:
enCodeblockSoup (Soup): soup of evernote post en-codeblock
Returns:
processed soup
Raises:
"""
allBrSoupList = enCodeblockSoup.find_all("br")
for eachBrSoup in allBrSoupList:
isExpectedBr = False
curBrParent = eachBrSoup.parent
if curBrParent:
curBrParentName = curBrParent.name
isParentDiv = curBrParentName == "div"
if isParentDiv:
curBrParentParent = curBrParent.parent
if curBrParentParent:
curBrParentParentName = curBrParentParent.name
if curBrParentParentName == "div":
isExpectedBr = True
if isExpectedBr:
newlineStr = "\n"
curBrParentParent.div.replace_with(newlineStr)
# for debug
afterConvertCodeStr = utils.getAllContents(enCodeblockSoup)
logging.info("codeStr=%s", afterConvertCodeStr)
return enCodeblockSoup去调试。
调试发现,此处:
curBrParentParent.div.replace_with(newlineStr)
好像不对:万一div下面有2个:
<div><br/></div> <div><br/></div>
那:
curBrParentParent.div
好像就没法指定是哪个了。
好像参考
可以去:
insert_after() 一个 换行符
然后再销毁
或许就可以了?
不过此处暂时基本上实现了要的效果:
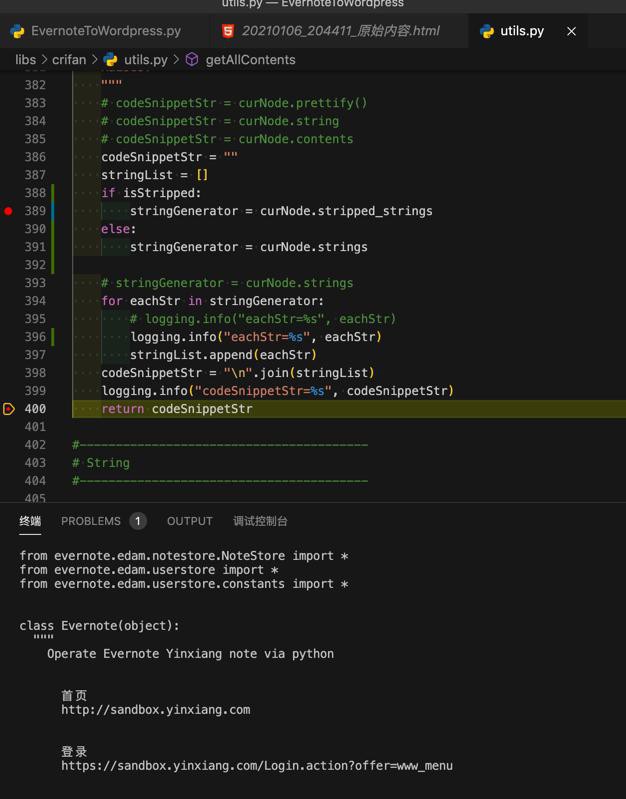
但是每次都是:单个空行,变成多个空行了。
还是去换成上面的先insert再销毁,看看效果
newlineStr = "\n"
# newlineStr = enCodeblockSoup.new_string("\n")
# curBrParentParent.div.replace_with(newlineStr)
curBrParent.insert_after(newlineStr)
curBrParent.decompose()结果:
insert_after后,可以新增一个 \n
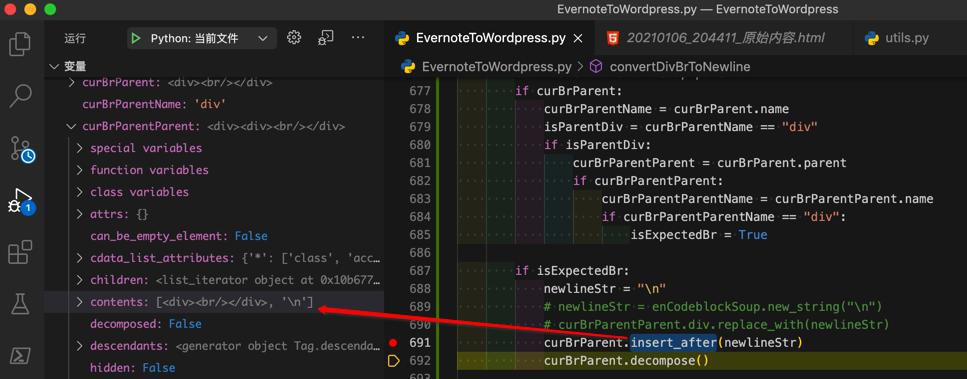
然后decompose后,curBrParentParent的确只剩一个,刚加上的:\n 了:
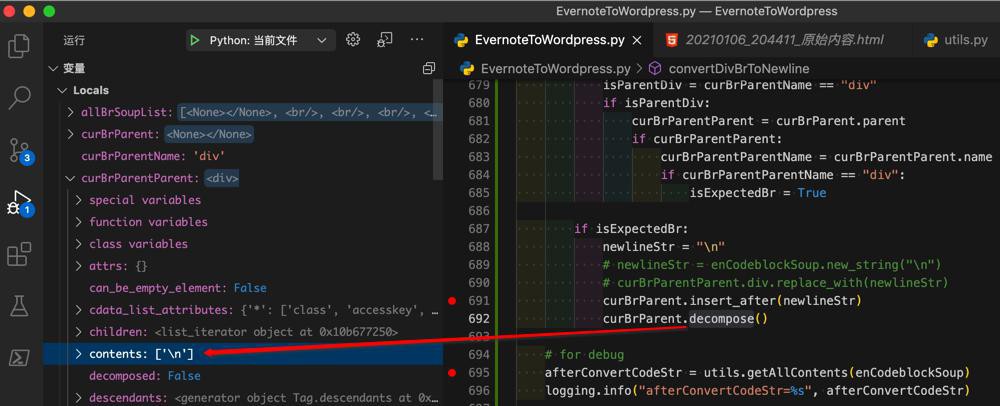
最后的字符串,貌似也是符合预期的:
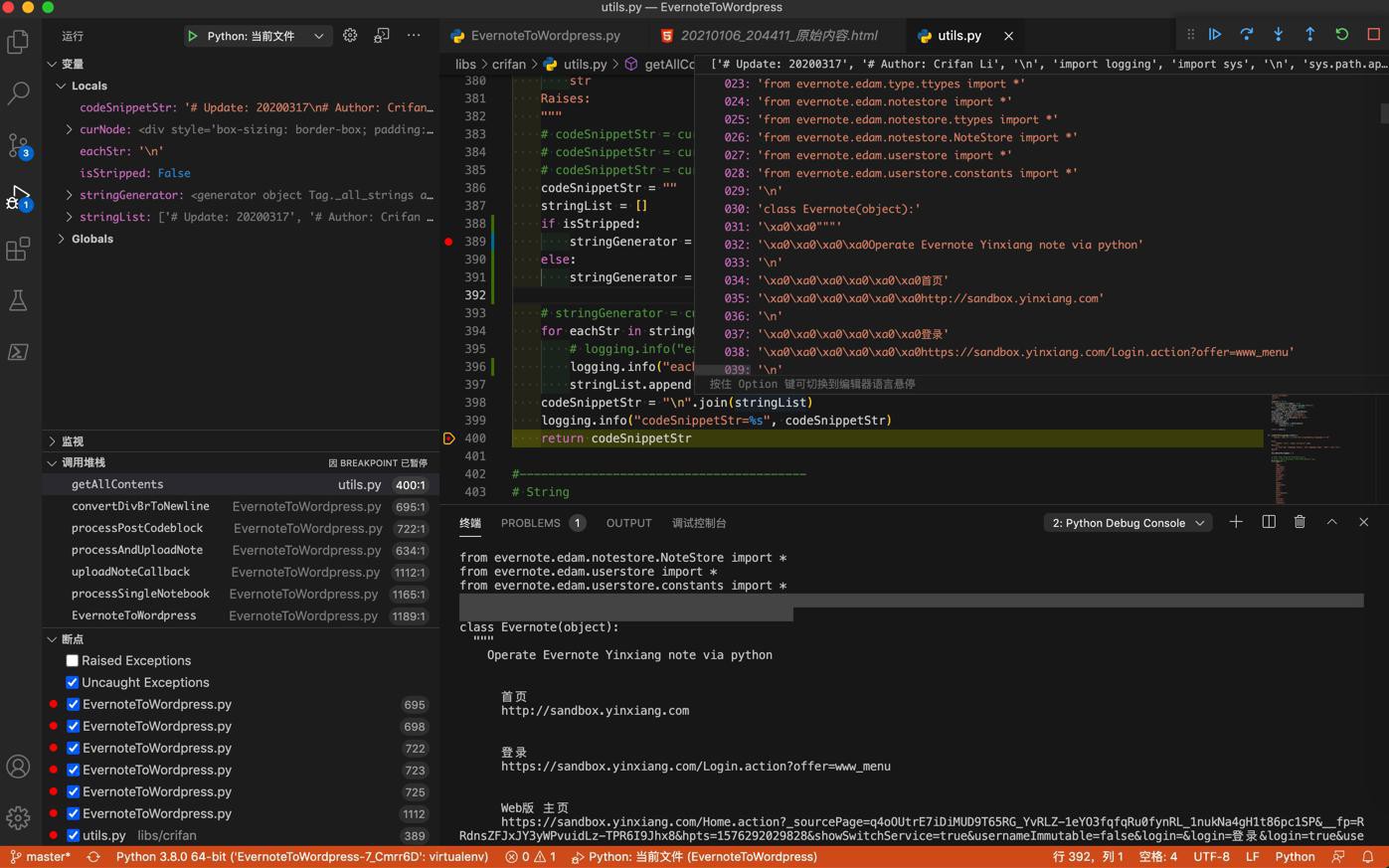
只不过输出print好像是2个空行
继续试试
结果发现:
输出到log日志中的,的确是2个空行:
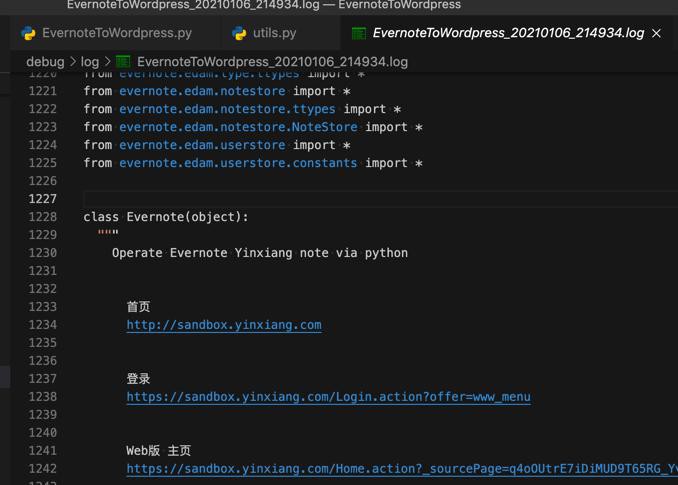
突然明白了:
此处无需加上换行:\n
只是加上 空行:””
if isExpectedBr:
# newlineStr = "\n"
# newlineStr = enCodeblockSoup.new_string("\n")
# curBrParentParent.div.replace_with(newlineStr)
# curBrParent.insert_after(newlineStr)
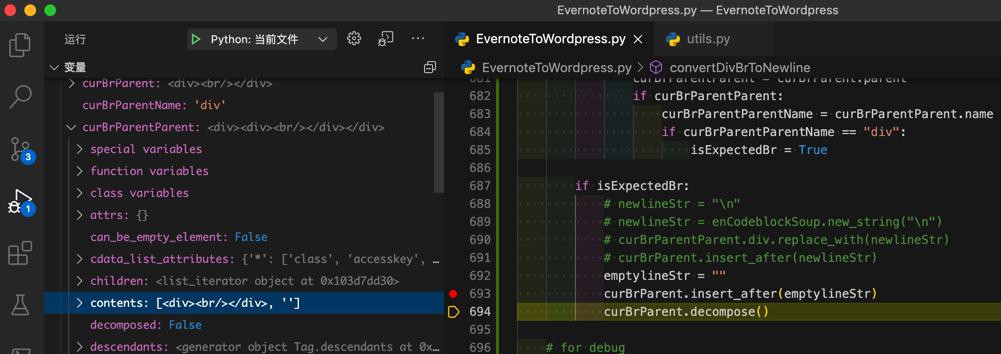
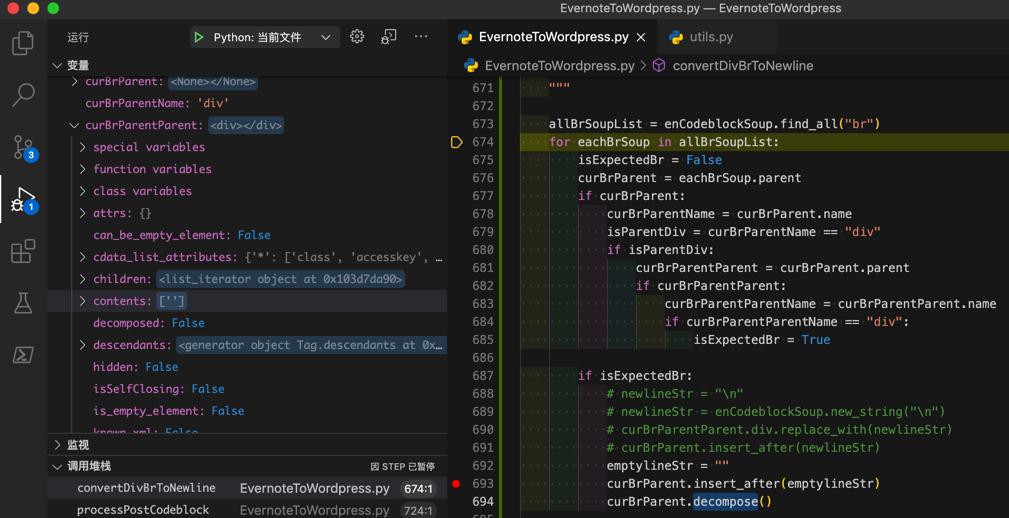
emptylineStr = ""
curBrParent.insert_after(emptylineStr)
curBrParent.decompose()估计就可以了。
去调试看看
输出整个字符串:
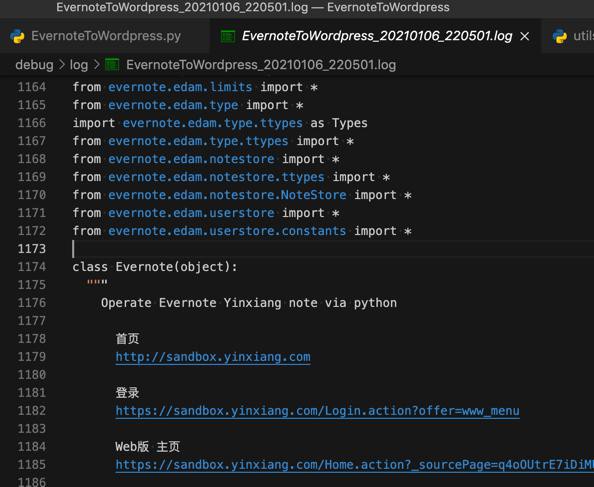
就正常了。
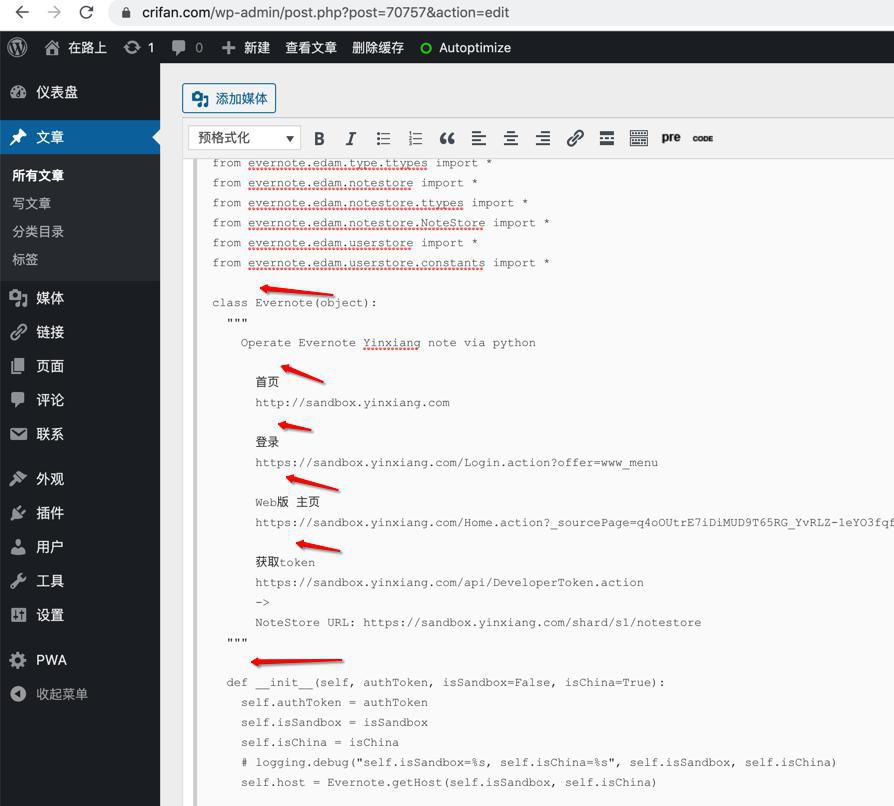
继续发布到WordPress中,后台编辑就正常有缩进和空行了:
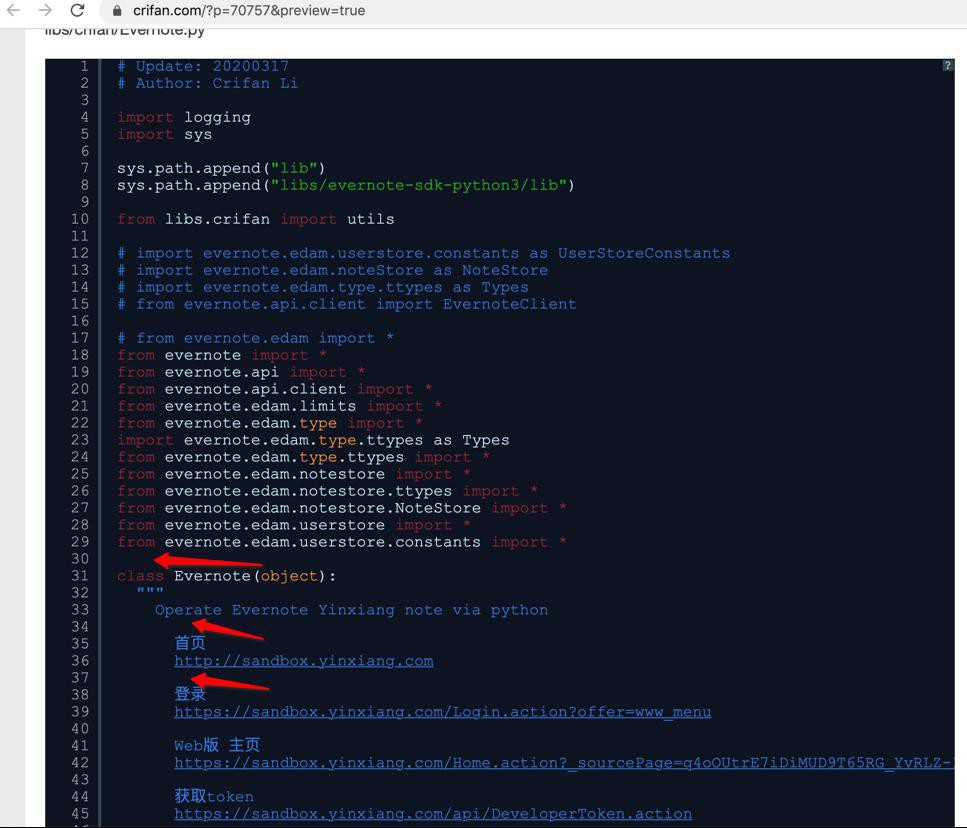
预览后,也是正常有缩进和空行的:
【总结】
此处最终的改动是:
def convertDivBrToNewline(enCodeblockSoup):
"""Convert
<div>
<div><br /></div>
</div>
<div>
<div><br /></div>
<div><br /></div>
</div>
to:
<div>
</div>
<div>
</div>
Args:
enCodeblockSoup (Soup): soup of evernote post en-codeblock
Returns:
processed soup
Raises:
"""
allBrSoupList = enCodeblockSoup.find_all("br")
for eachBrSoup in allBrSoupList:
isExpectedBr = False
curBrParent = eachBrSoup.parent
if curBrParent:
curBrParentName = curBrParent.name
isParentDiv = curBrParentName == "div"
if isParentDiv:
curBrParentParent = curBrParent.parent
if curBrParentParent:
curBrParentParentName = curBrParentParent.name
if curBrParentParentName == "div":
isExpectedBr = True
if isExpectedBr:
# newlineStr = "\n"
# newlineStr = enCodeblockSoup.new_string("\n")
# curBrParentParent.div.replace_with(newlineStr)
# curBrParent.insert_after(newlineStr)
emptylineStr = ""
curBrParent.insert_after(emptylineStr)
curBrParent.decompose()
# # for debug
# afterConvertCodeStr = utils.getAllContents(enCodeblockSoup)
# logging.info("afterConvertCodeStr=%s", afterConvertCodeStr)
return enCodeblockSoup
def processPostCodeblock(soup):
...
# convert
to newline
eachCodeblockNode = convertDivBrToNewline(eachCodeblockNode)
codeStr = utils.getAllContents(eachCodeblockNode)即可实现:
保留印象笔记的note的en-codeblock中的div中:
- br = 空行
- 空格 = 代码中的缩进
了。
相关函数:
libs/crifan/utils.py
def getAllContents(curNode, isStripped=False):
"""Get all contents of current and children nodes
Args:
curNode (soup node): current Beautifulsoup node
isStripped (bool): return stripped string or not
Returns:
str
Raises:
"""
# codeSnippetStr = curNode.prettify()
# codeSnippetStr = curNode.string
# codeSnippetStr = curNode.contents
codeSnippetStr = ""
stringList = []
if isStripped:
stringGenerator = curNode.stripped_strings
else:
stringGenerator = curNode.strings
# stringGenerator = curNode.strings
for eachStr in stringGenerator:
# logging.debug("eachStr=%s", eachStr)
stringList.append(eachStr)
codeSnippetStr = "\n".join(stringList)
logging.debug("codeSnippetStr=%s", codeSnippetStr)
return codeSnippetStr最新代码详见: