折腾:
【未解决】Python处理发布印象笔记帖子到WordPress后的部分细节优化
期间,之前已实现印象笔记Evernote的note笔记的图片资源resource,缩小处理后,上传到WordPress的media:
【已解决】Python中更新印象笔记中帖子中附件图片的数据
后,回来更新Evernote的note的resources的list
但是前后调试了几次,发现都是有些bug:
更新后,note的resources和实际已处理的image的个数不匹配
导致更新后,resources中还残留没处理的图片资源,但是content的html中已经没了en-media了。
所以,此处再去继续修复逻辑。
最后采用的是:
给noteDetail.resources拷贝了一份latestResList,然后作为参数
logging.info("Uploading resource and sync url")
if noteDetail.resources:
# later process should use copied resources list, otherwise internal will alter resources list, case unexpected resources list changed
originResList = copy.deepcopy(noteDetail.resources)
latestResList = copy.deepcopy(noteDetail.resources)
totalResNum = len(originResList)
logging.info("Total resources: %d", totalResNum)
for curResIdx, eachResource in enumerate(originResList):
curResNum = curResIdx + 1
logging.info("%s resource %d/%d %s", "-"*20, curResNum, totalResNum, "-"*20)
uploadedImgUrl = gEnToWp.uploadNoteImageToWordpress(noteDetail, eachResource, latestResList)
# 'https://www.crifan.com/files/pic/uploads/2020/11/acd6a38382b0475db72764187cac7ae0.jpg'
logging.info("uploaded resource %s to wordpress and has sync url %s", eachResource.guid, uploadedImgUrl)
# if uploadedImgUrl:
# latestResList.remove(eachResource)
# Error: 发生异常: ValueError list.remove(x): x not in list
# for inside uploadNoteImageToWordpress have removed传入uploadNoteImageToWordpress
def uploadNoteImageToWordpress(self, curNoteDetail, curResource, curResList=None):
"""Upload note single imges to wordpress, and sync to note (replace en-media to img)
Args:
curNote (Note): evernote Note
curResource (Resource): evernote Note Resource
curResList (list): evernote Note Resource list
Returns:
upload image url(str)
Raises:
"""
if not curResList:
curResList = curNoteDetail.resources
uploadedImgUrl = ""
isImg = self.evernote.isImageResource(curResource)
if not isImg:
logging.warning("Not upload resource %s to wordpress for Not Image", curResource)
return uploadedImgUrl
isUploadOk, respInfo = self.uploadImageToWordpress(curResource)
if isUploadOk:
# {'id': 70491, 'url': 'https://www.crifan.com/files/pic/uploads/2020/11/c8b16cafe6484131943d80267d390485.jpg', 'slug': 'c8b16cafe6484131943d80267d390485', 'link': 'https://www.crifan.com/c8b16cafe6484131943d80267d390485/', 'title': 'c8b16cafe6484131943d80267d390485'}
uploadedImgUrl = respInfo["url"]
logging.info("uploaded url %s", uploadedImgUrl)
# "https://www.crifan.com/files/pic/uploads/2020/03/f6956c30ef0b475fa2b99c2f49622e35.png"
# relace en-media to img
respNote = self.syncNoteImage(curNoteDetail, curResource, uploadedImgUrl, curResList)
# logging.info("Complete sync image %s to note %s", uploadedImgUrl, respNote.title)
else:
logging.warning("Failed to upload image resource %s to wordpress", curResource)
return uploadedImgUrl再传入:syncNoteImage
def syncNoteImage(self, curNoteDetail, curResource, uploadedImgUrl, curResList=None):
"""Sync uploaded image url into Evernote Note content, replace en-media to img
Args:
curNoteDetail (Note): evernote Note
curResource (Resource): evernote Note Resource
uploadedImgUrl (str): uploaded imge url, previously is Evernote Resource
curResList (list): evernote Note Resource list
Returns:
updated note detail
Raises:
"""
if not curResList:
curResList = curNoteDetail.resources
# curContent = curNoteDetail.content
# logging.debug("curContent=%s", curContent)
# soup = BeautifulSoup(curContent, 'html.parser')
soup = crifanEvernote.noteContentToSoup(curNoteDetail)
"""
<en-media hash="7c54d8d29cccfcfe2b48dd9f952b715b" type="image/png" />
"""
# imgeTypeP = re.compile("image/\w+")
# mediaNodeList = soup.find_all("en-media", attrs={"type": imgeTypeP})
# mediaNodeList = soup.find("en-media", attrs={"hash": })
curEnMediaSoup = crifanEvernote.findResourceSoup(soup, curResource)
logging.debug("curEnMediaSoup=%s", curEnMediaSoup)
# curEnMediaSoup=<en-media hash="0bbf1712d4e9afe725dd51e701c7fae6" style="width: 788px; height: auto;" type="image/jpeg"></en-media>
if curEnMediaSoup:
curImgSoup = curEnMediaSoup
curImgSoup.name = "img"
curImgSoup.attrs = {"src": uploadedImgUrl}
logging.debug("curImgSoup=%s", curImgSoup)
# curImgSoup=<img src="https://www.crifan.com/files/pic/uploads/2020/11/c8b16cafe6484131943d80267d390485.jpg"></img>
# new content string
updatedContent = crifanEvernote.soupToNoteContent(soup)
logging.debug("updatedContent=%s", updatedContent)
curNoteDetail.content = updatedContent
else:
logging.warning("Not found en-media node for guid=%s, mime=%s, fileName=%s", curResource.guid, curResource.mime, curResource.attributes.fileName)
# here even not found, still consider as processed, later will remove it
# remove resource from resource list
# oldResList = curNoteDetail.resources
# Note: avoid side-effect: alter pass in curNoteDetail object's resources list
# which will cause caller curNoteDetail.resources loop terminated earlier than expected !
# oldResList = copy.deepcopy(curNoteDetail.resources)
# oldResList.remove(curResource) # workable
# newResList = oldResList
# Note 20201206: has update above loop, so should directly update curNoteDetail.resources
# curNoteDetail.resources.remove(curResource)
# newResList = curNoteDetail.resources
curResList.remove(curResource)
newResList = curResList
syncParamDict = {
# mandatory
"noteGuid": curNoteDetail.guid,
"noteTitle": curNoteDetail.title,
# optional
"newContent": curNoteDetail.content,
"newResList": newResList,
}
respNote = self.evernote.syncNote(**syncParamDict)
logging.info("Complete sync image %s to evernote note %s", uploadedImgUrl, curNoteDetail.title)
return respNote如此,内部处理时,只依赖于传入的resource的list去最终remove已处理的
这样就不会影响,和受原有的,当前的note的resources了
最终,实现了:
确保每次上传了一个图片resource后,把当前的resources的list中删除掉
以及再去用最新的resources,(调用evernote.syncNote)及时更新note,确保同步。
附录,相关被调用到的函数:
libs/crifan/crifanEvernote.py
@staticmethod
def findResourceSoup(soup, curResource):
"""find related BeautifulSoup soup from Evernote Resource
Args:
soup (Soup): BeautifulSoup soup
curResource (Resource): Evernote Resource
Returns:
soup node
Raises:
"""
curMime = curResource.mime # 'image/png'
logging.debug("curMime=%s", curMime)
# # method 1: calc again
# curResBytes = curResource.data.body
# curHashStr1 = utils.calcMd5(curResBytes) # 'dc355da030cafe976d816e99a32b6f51'
# method 2: convert from body hash bytes
curHashStr = utils.bytesToStr(curResource.data.bodyHash)
logging.debug("curHashStr=%s", curHashStr)
# b'\xae\xe1G\xdb\xcdh\x16\xca+@IF"\xff\xfa\xa3' -> 'aee147dbcd6816ca2b40494622fffaa3'
# imgeTypeP = re.compile("image/\w+")
curResSoup = soup.find("en-media", attrs={"type": curMime, "hash": curHashStr})
logging.debug("curResSoup=%s", curResSoup)
# <en-media hash="aee147dbcd6816ca2b40494622fffaa3" type="image/png" width="370"></en-media>
return curResSoup注:当之前调试期间出现不匹配时,此处curResSoup就可能未空
而正常情况下,肯定不为空的,是有值的。
libs/crifan/utils.py
def bytesToStr(inputBytes, encoding="UTF-8"): """convert binary bytes into str hexadecimal representation Args: inputBytes (bytes): bytes Returns: str Examples: input: b'\xdc5]\xa00\xca\xfe\x97m\x81n\x99\xa3+oQ' return: 'dc355da030cafe976d816e99a32b6f51' Raises: """ inputHex = binascii.hexlify(inputBytes) # b'dc355da030cafe976d816e99a32b6f51' inputStr = inputHex.decode(encoding) # 'dc355da030cafe976d816e99a32b6f51' return inputStr
另外更新到最后的
libs/crifan/crifanEvernote.py
@staticmethod
def soupToNoteContent(soup):
"""Convert BeautifulSoup Soup to Evernote Note content
Args:
soup (Soup): BeautifulSoup Soup
Returns:
Evernote Note content html(str)
Raises:
"""
# for debug
# if soup.name != "html":
if soup.name != "[document]":
logging.info("soup.name=%s", soup.name)
# soup.name = "en-note" # not work
noteContentHtml = utils.soupToHtml(soup, isFormat=False)
# Note: here not use formated html, to avoid
# speical case:
# some special part title is url, then format will split part url and title
# so here not use format
# convert <html>...</html> back to <en-note>...</en-note>
noteContentHtml = re.sub('<html>(?P<contentBody>.+)</html>', "<en-note>\g<contentBody></en-note>", noteContentHtml, flags=re.S)
noteContentHtml = crifanEvernote.convertToClosedEnMediaTag(noteContentHtml)
# add first line
# <!DOCTYPE en-note SYSTEM "http://xml.evernote.com/pub/enml2.dtd">
noteContentHtml = '<!DOCTYPE en-note SYSTEM "http://xml.evernote.com/pub/enml2.dtd">\n' + noteContentHtml
return noteContentHtmllibs/crifan/utils.py
def soupToHtml(soup, isFormat=True): """Convert soup to html string Args: soup (Soup): BeautifulSoup soup isFormat (bool): use prettify to format html Returns: html (str) Raises: """ if isFormat: curHtml = soup.prettify() else: curHtml = str(soup) return curHtml
libs/crifan/crifanEvernote.py
@staticmethod
def convertToClosedEnMediaTag(noteHtml):
"""Process note content html, for special </en-media> will cause error, so need convert:
<en-media hash="7c54d8d29cccfcfe2b48dd9f952b715b" type="image/png"></en-media>
to closed en-media tag:
<en-media hash="7c54d8d29cccfcfe2b48dd9f952b715b" type="image/png" />
Args:
noteHtml (str): Note content html
Returns:
note content html with closed en-media tag (str)
Raises:
"""
noteHtml = re.sub("(?P<enMedia><en-media\s+[^<>]+)>\s*</en-media>", "\g<enMedia> />", noteHtml, flags=re.S)
return noteHtmllibs/crifan/crifanEvernote.py
@staticmethod
def noteContentToSoup(curNote):
"""Convert Evernote Note content to BeautifulSoup Soup
Args:
curNote (Note): Evernote Note
Returns:
Soup
Raises:
"""
noteHtml = crifanEvernote.getNoteContentHtml(curNote)
soup = utils.htmlToSoup(noteHtml)
# Note: now top node is <html>, not <en-note>
# but top node name is '[document]' not 'html'
# for debug
# if soup.name != "html":
if soup.name != "[document]":
logging.info("soup.name=%s", soup.name)
return soup以及最新的:
@staticmethod
def getNoteContentHtml(curNote, retailTopHtml=True):
"""Get evernote Note content html
Args:
curNote (Note): evernote Note
retailTopHtml (bookl): Ture to <html>xxx<html>, False to xxx
Returns:
html (str)
Raises:
"""
noteHtml = curNote.content
# Special:
# '<?xml version="1.0" encoding="UTF-8" standalone="no"?>\n<!DOCTYPE en-note SYSTEM "http://xml.evernote.com/pub/enml2.dtd">\n<en-note>
# -> remove: <?xml version="1.0" encoding="UTF-8" standalone="no"?>
noteHtml = re.sub('<\?xml version="1.0" encoding="UTF-8" standalone="no"\?>\s*', "", noteHtml)
# remove fisrt line
# <!DOCTYPE en-note SYSTEM "http://xml.evernote.com/pub/enml2.dtd">
# '<!DOCTYPE en-note SYSTEM "http://xml.evernote.com/pub/enml2.dtd">\n
noteHtml = re.sub('<!DOCTYPE en-note SYSTEM "http://xml\.evernote\.com/pub/enml2\.dtd">\s*', "", noteHtml)
if retailTopHtml:
# convert <en-note>...</en-note> to <html>...</html>
replacedP = "<html>\g<contentBody></html>"
else:
# convert <en-note>...</en-note> to ...
replacedP = "\g<contentBody>"
noteHtml = re.sub('<en-note>(?P<contentBody>.+)</en-note>', replacedP, noteHtml, flags=re.S)
noteHtml = noteHtml.strip()
return noteHtml上传image图片的resource:
libs/crifan/crifanEvernoteToWordpress.py
def uploadImageToWordpress(self, imgResource):
"""Upload image resource to wordpress
Args:
imgResource (Resouce): evernote image Resouce
Returns:
(bool, dict)
Raises:
"""
imgData = imgResource.data
imgBytes = imgData.body
imgDataSize = imgData.size
# guid:'f6956c30-ef0b-475f-a2b9-9c2f49622e35'
imgGuid = imgResource.guid
logging.debug("imgGuid=%s, imgDataSize=%s", imgGuid, imgDataSize)
curImg = utils.bytesToImage(imgBytes)
logging.debug("curImg=%s", curImg)
# # for debug
# curImg.show()
imgFormat = curImg.format # 'PNG'
imgSuffix = utils.ImageFormatToSuffix[imgFormat] # 'png'
imgMime = utils.ImageSuffixToMime[imgSuffix] # 'image/png'
# curDatetimeStr = utils.getCurDatetimeStr() # '20200307_173141'
processedGuid = imgGuid.replace("-", "") # 'f6956c30ef0b475fa2b99c2f49622e35'
# imgeFilename = "%s.%s" % (curDatetimeStr, imgSuffix) # '20200307_173141.png'
imgeFilename = "%s.%s" % (processedGuid, imgSuffix) # 'f6956c30ef0b475fa2b99c2f49622e35.png'
isUploadImgOk, respInfo = self.wordpress.createMedia(imgMime, imgeFilename, imgBytes)
logging.info("%s to upload resource %s to wordpress", isUploadImgOk, imgGuid)
return isUploadImgOk, respInfolibs/crifan/crifanWordpress.py
class crifanWordpress(object):
def __init__(self, host, jwtToken, requestsProxies=None):
。。。
self.apiMedia = self.host + "/wp-json/wp/v2/media" # 'https://www.crifan.com/wp-json/wp/v2/media'
def createMedia(self, contentType, filename, mediaBytes):
"""Create wordpress media (image)
by call REST api: POST /wp-json/wp/v2/media
Args:
contentType (str): content type
filename (str): attachment file name
mediaBytes (bytes): media binary bytes
Returns:
(bool, dict)
True, uploaded media info
False, error detail
Raises:
"""
curHeaders = {
"Authorization": self.authorization,
"Content-Type": contentType,
"Accept": "application/json",
'Content-Disposition': 'attachment; filename=%s' % filename,
}
logging.debug("curHeaders=%s", curHeaders)
# curHeaders={'Authorization': 'Bearer eyJ0xxxyyy.zzzB4', 'Content-Type': 'image/png', 'Content-Disposition': 'attachment; filename=f6956c30ef0b475fa2b99c2f49622e35.png'}
createMediaUrl = self.apiMedia
resp = requests.post(
createMediaUrl,
proxies=self.requestsProxies,
headers=curHeaders,
data=mediaBytes,
)
logging.debug("resp=%s", resp)
isUploadOk, respInfo = crifanWordpress.processCommonResponse(resp)
return isUploadOk, respInfo相关完整的,最新的代码,详见:
- crifanWordpress.py
- crifanEvernote.py
- crifanEvernoteToWordpress.py
【后记】
对于:
更新完毕所有图片后,resources是空列表,也已经更新到note了
但是后续get detail,仍然还有一个resource:
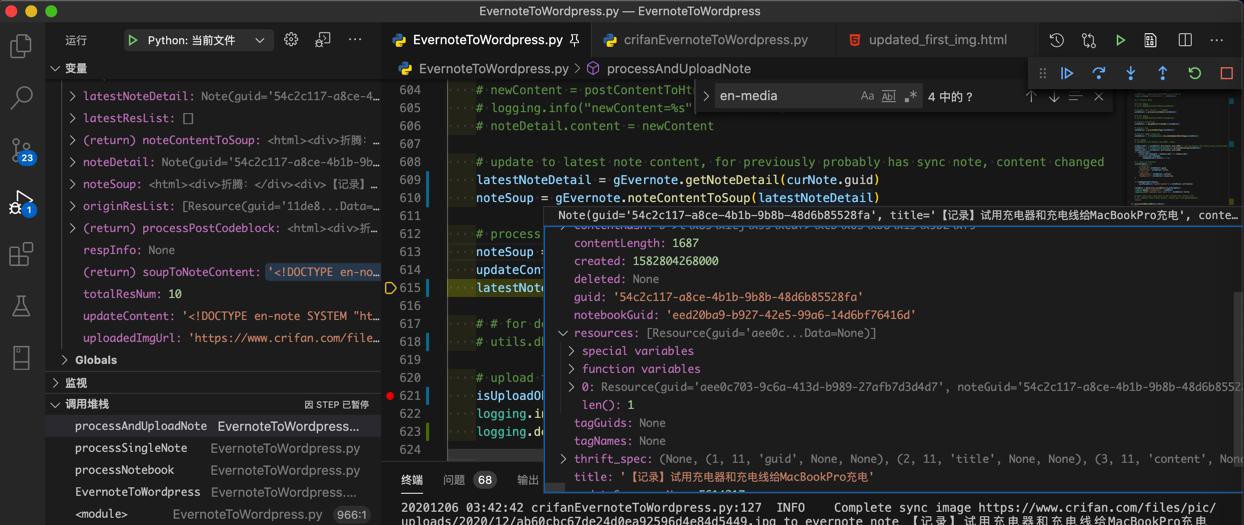
之前以为是自己代码bug呢。
结果再次调试发现,其实就是印象笔记的问题:
即使代码此处更新,resources是空,但是sync后,再去获取,仍然还残留一个image的resource,具体原因,不知道。
对了,再去调试看看,看看具体是哪个图片的resource被残留了。
从guid看看,或许可以找到?又或许是无故多出的?