之前:
【未解决】重新爬取少儿xxx数据并记录部分的分类层级和是否是动画片
发现
api都变了
内部course的id都变了
所以打算重新爬取所有的视频
后记:
后续需求更新为:
- 1.先爬动画片
- 2.再爬4个子分类= 之前共5 – 动画片的1
- 3.再爬其余分类的:遇到之前下载过的 就忽略
- 到时候得看一下时间,如果1和2都需要很久,而且1+2数量都很多,3就不用爬了
其中:
- 2和3 都加上额外标签 表示所属分类
目前的要求是:
(1)所有视频中 优先爬取 动画片=动漫世界
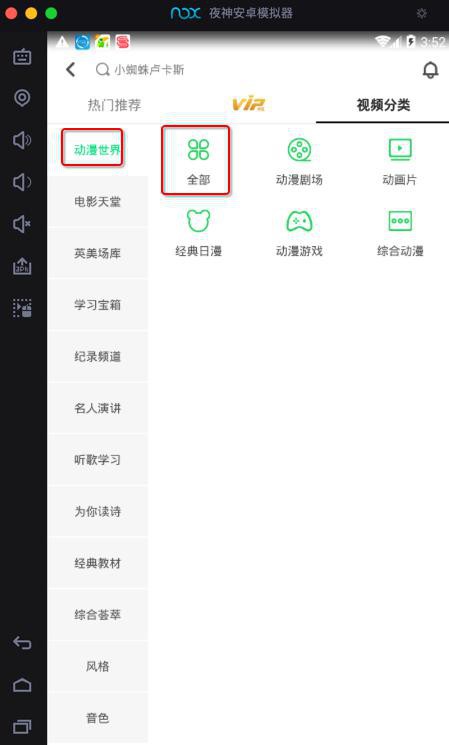
(2)先爬取course,再爬取user的show
- 代码先写爬取course的:下载course内容(json存到mongodb,video,subtitle,cover存到oss)
- 再去更新添加爬取相关的show的(但不下载course了,只下载show)
- 从相关的show的user入手,找其他的show下载
(3)保存数据
- 保存json到mongodb
- 保存位置:
- course -》 media.cqpycourse = child xxx course
- 加额外字段:isCartoon
- 动漫世界:true
- 其他:false
- user的show -》 media.cqpyshow = child xxx show
- 保存其他内容到oss
- 视频video:animation.standar
- 先去水印,再上传oss
- cover封面图片:animation.ccover
- srt字幕:animation.csubtitle
然后去分析api接口
从这里入口
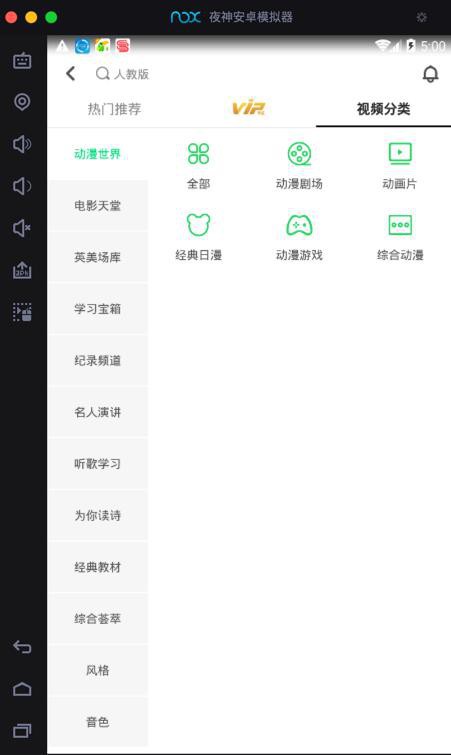
然后先去搞到获取全部视频分类的api
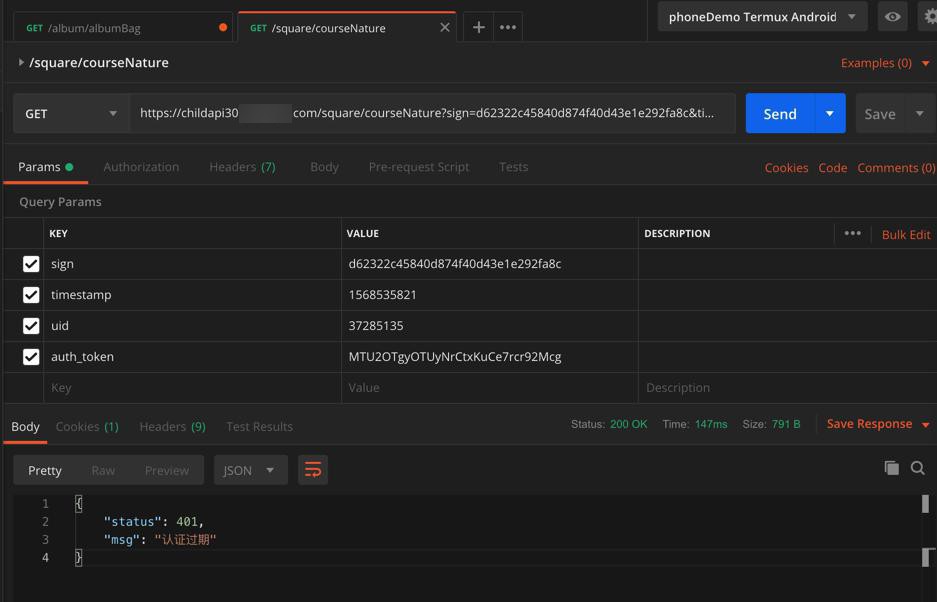
https://childapi30.xxx.com/square/courseNature?sign=d62322c45840d874f40d43e1e292fa8c×tamp=1568535821&uid=37285135&auth_token=MTU2OTgyOTUyNrCtxKuCe7rcr92Mcg
结果过了再去试试,就过期了:
{
"status": 401,
"msg": "认证过期"
}
后来发现,至少是缺了必要的headers,去加上
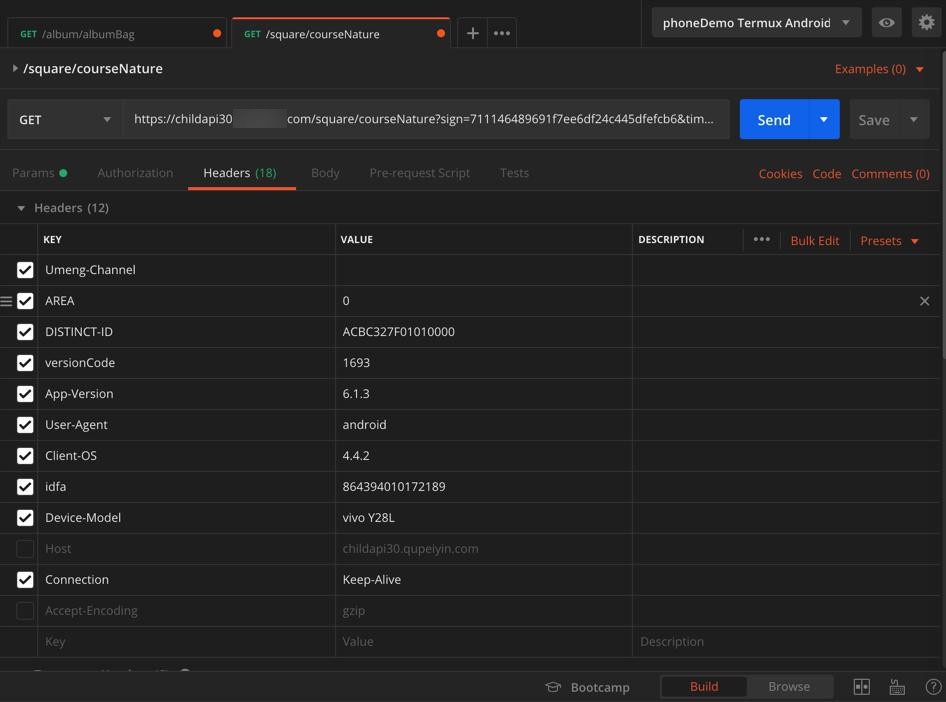
再去刷新一下,用新的值:
https://childapi30.xxx.com/square/courseNature?sign=711146489691f7ee6df24c445dfefcb6×tamp=1568538032&uid=37285135&auth_token=MTU2OTgyOTUyNrCtxKuCe7rcr92Mcg
才可以:
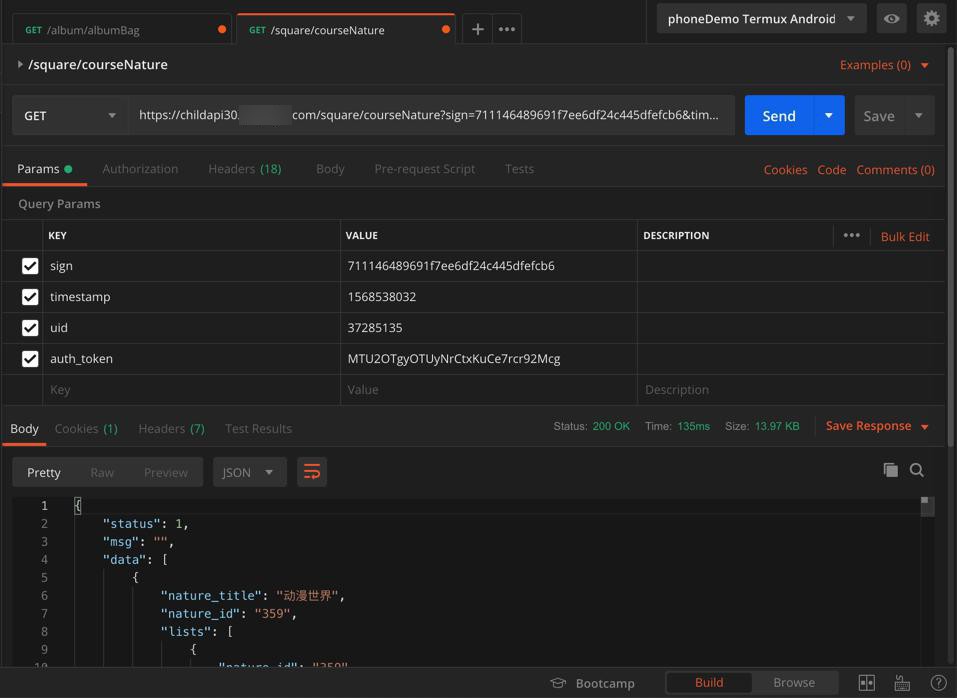
如果少了
sign和auth_token
就会报错:
认证参数错误
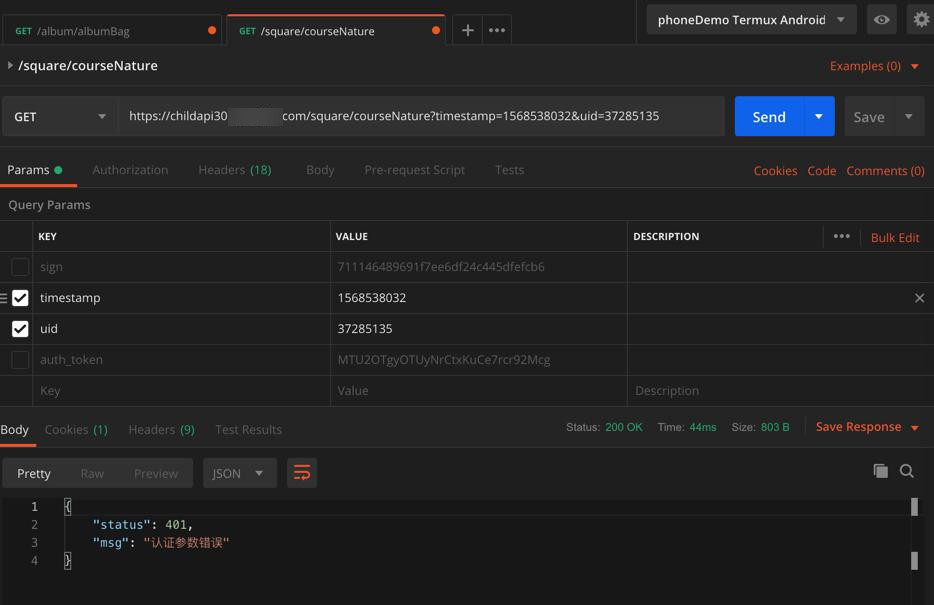
看来还是要去解决:
想办法搞清楚,调用接口所需要的sign和auth_token的计算逻辑。
又回到了:
【已解决】破解安卓应用少儿xxx的源码以便于找到sign签名和auth_token的算法计算逻辑
接着继续写余下代码。
结果:
【已解决】搞懂少儿xxx中getCourseList中sign值的计算规则
继续调试和写代码获取数据。
获取单个course的详情
https://childapi30.xxx.com/course/detail?sign=c56101e4d37d85e1f39ae578e41ad675×tamp=1568799464&uid=37285135&auth_token=MTU2OTkxNjU3ObCtxKuCe7rcr92Mcg&course_id=273037 sign c56101e4d37d85e1f39ae578e41ad675 timestamp 1568799464 uid 37285135 auth_token MTU2OTkxNjU3ObCtxKuCe7rcr92Mcg course_id 273037
然后代码写好了,本地也调试OK了。
再去部署到dev01服务器中。
结果先要去修复dev01中pyspider的环境:
[root@xxx-dev-01 ~]# supervisorctl start pyspider pyspider: ERROR (abnormal termination) [root@xxx-dev-01 ~]# supervisorctl start pyspider pyspider: ERROR (already started) [root@xxx-dev-01 ~]# supervisorctl status pyspider pyspider FATAL Exited too quickly (process log may have details)
发现配置都对:
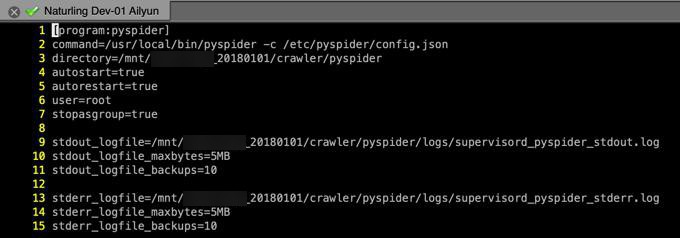
但还是运行
supervisorctl start pyspider
报错:
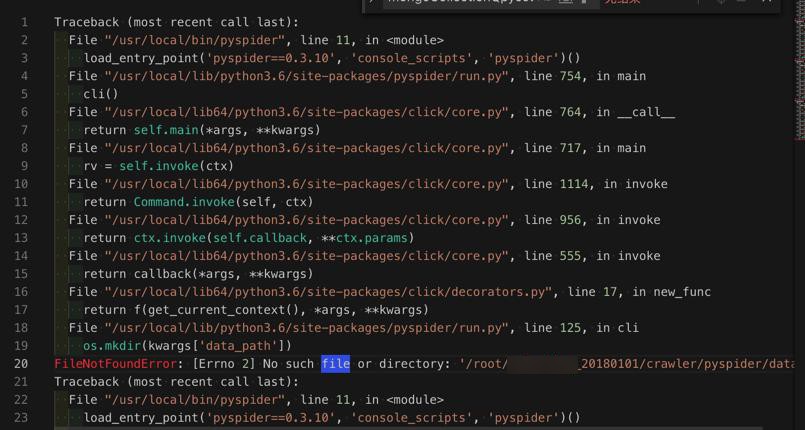
很明显是路径不对
但是此处:
pyspider中的代码的路径要更新
但是此处还没进入爬虫呢。
感觉好像是:
/etc/pyspider/config.json
中的路径?
去看看
果然是,去更新路径root为mnt
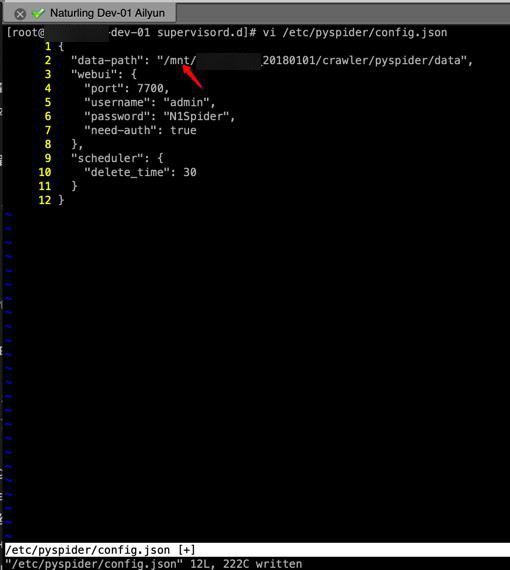
[root@xxx-dev-01 supervisord.d]# supervisorctl start pyspider pyspider: started [root@xxx-dev-01 supervisord.d]# supervisorctl status pyspider pyspider RUNNING pid 11625, uptime 0:00:06 [root@xxx-dev-01 supervisord.d]# supervisorctl status pyspider pyspider RUNNING pid 11625, uptime 0:00:08
正常了。
可以访问了
去拷贝代码进去,点击Run运行爬虫
结果等了半天,竟然没有status更新:

去看看log什么情况
看到了:
Error: Could not create web server listening on port 25555
所以去杀掉,重启pyspider
然后可以运行了。

去看看下载的目录和数据:
[root@xxx-dev-01 course]# pwd /mnt/xxx_20180101/crawler/crawled_data/xxx_recrawlCqpy/course [root@xxx-dev-01 course]# ll total 308 drwxr-xr-x 2 root root 4096 Sep 19 11:27 118844 drwxr-xr-x 2 root root 4096 Sep 19 11:28 119138 ...
是有下载到数据的。
然后就等继续下载,知道下载完成了。
[root@xxx-dev-01 xxx_recrawlCqpy]# pwd /mnt/xxx_20180101/crawler/crawled_data/xxx_recrawlCqpy [root@xxx-dev-01 xxx_recrawlCqpy]# du -sh . 79M .
目前下了79M数据了。
【规避解决】PySpider中批量爬取少儿xxx一段时间后出现401认证过期问题
此刻已下载:

[root@xxx-dev-01 ~]# cd /mnt/xxx_20180101/crawler/crawled_data/xxx_recrawlCqpy [root@xxx-dev-01 xxx_recrawlCqpy]# ll total 36 drwxr-xr-x 1512 root root 36864 Sep 19 14:26 course [root@xxx-dev-01 xxx_recrawlCqpy]# du -sh . 1.4G .
1.4G了。
运行了几个小时之后,貌似很顺利的可以下载了

只不过发现是:
active tasks中,有些error的:
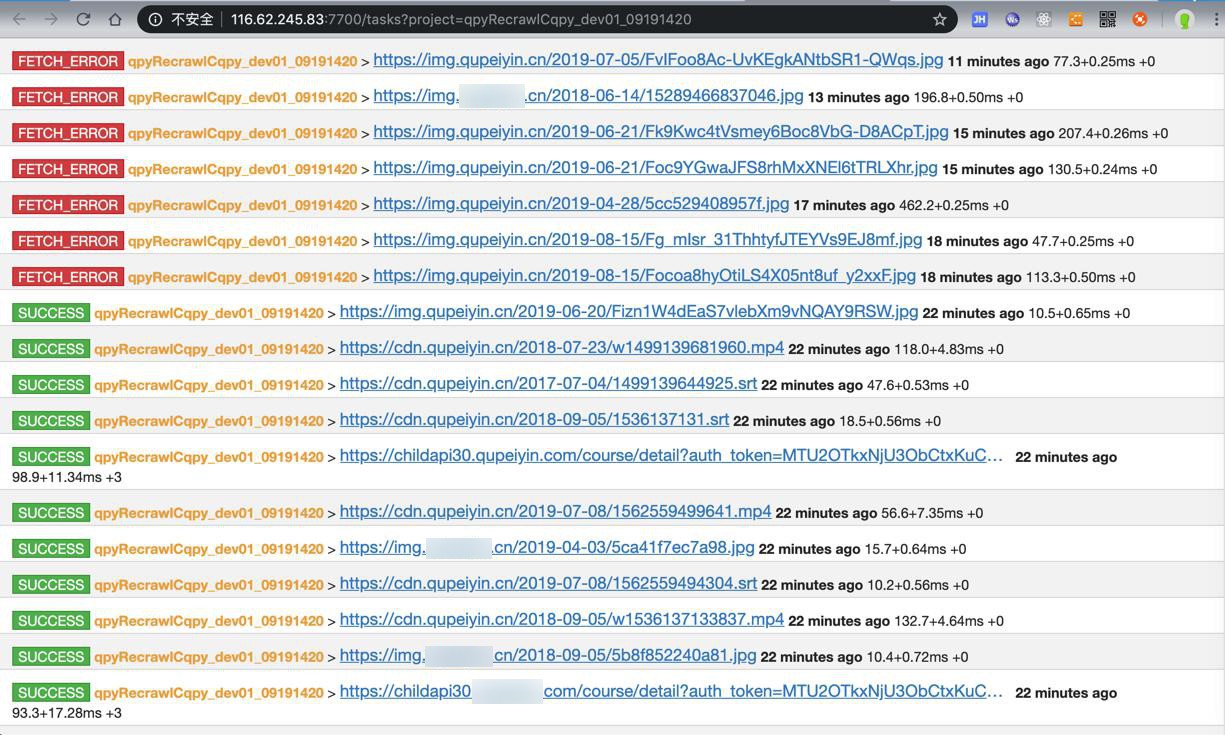
对于其中的部分图片
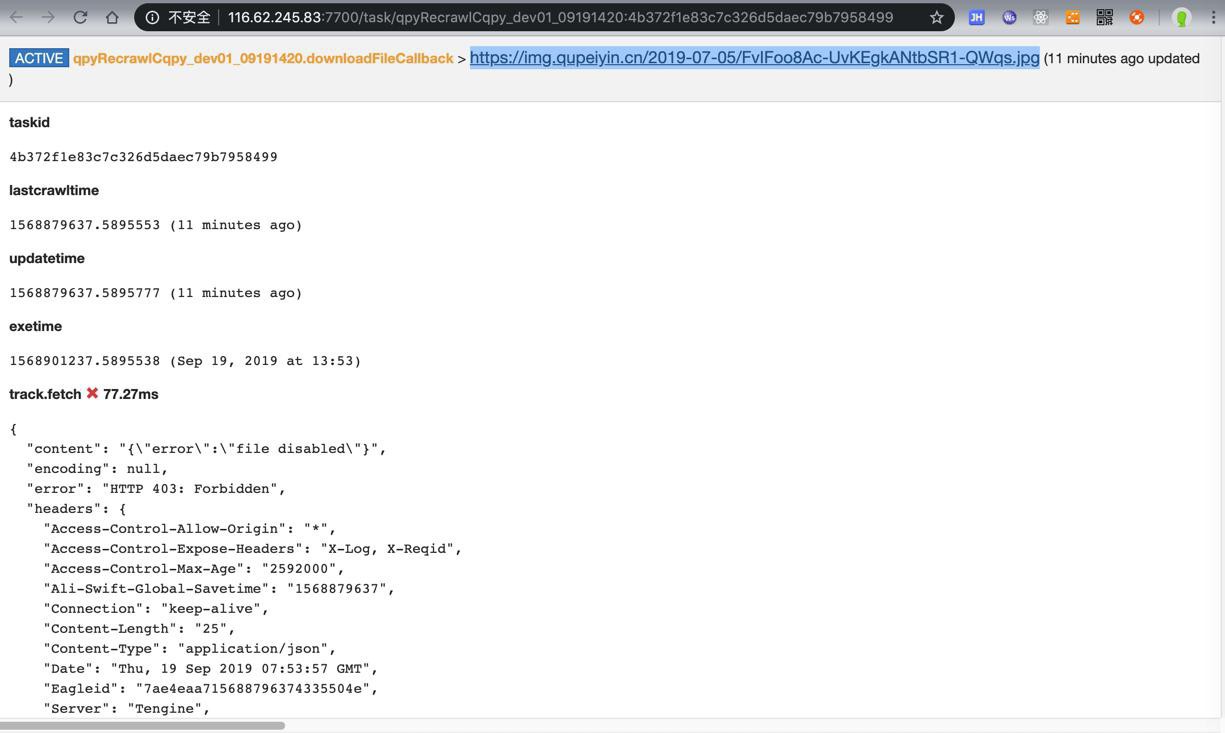
试了试,果然是本身有问题:
https://img.xxx.cn/2019-07-05/FvIFoo8Ac-UvKEgkANtbSR1-QWqs.jpg
{
"error": "file disabled"
}
之外,还有:
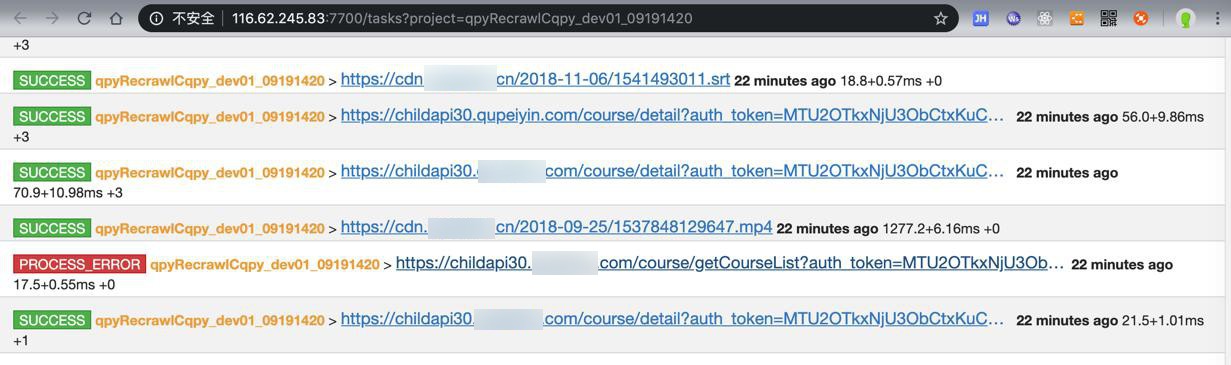
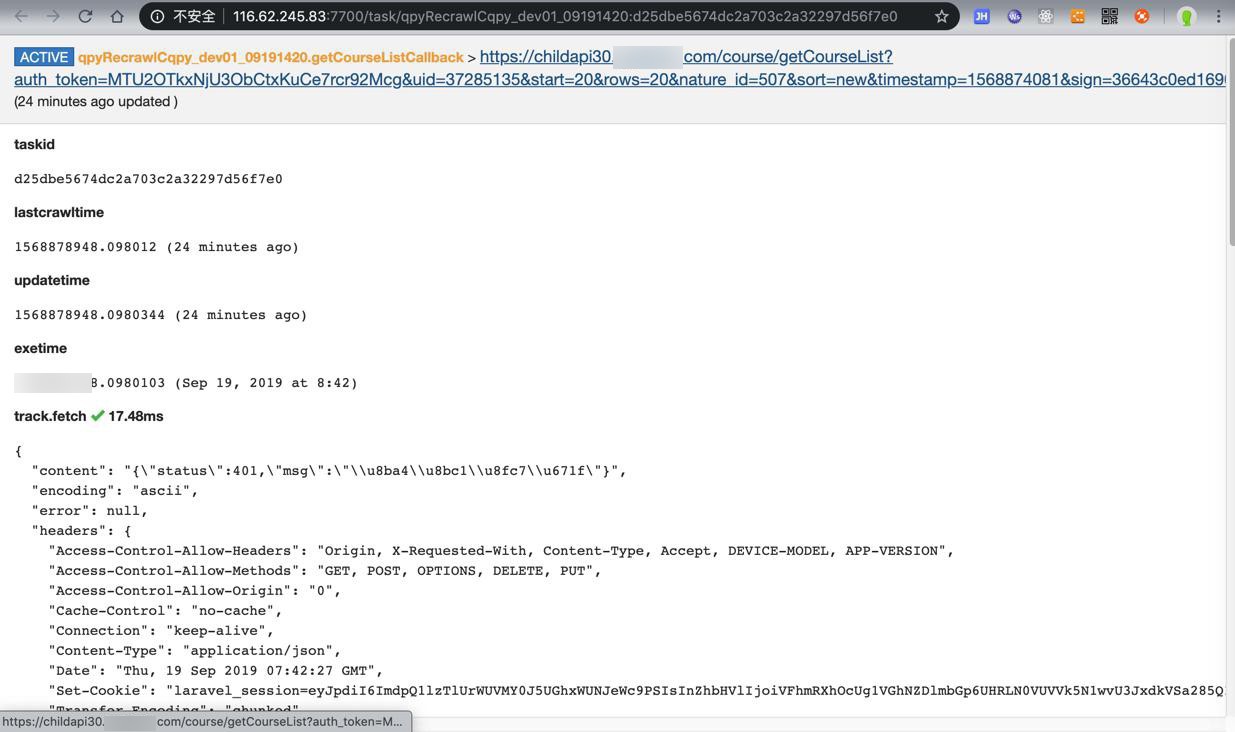
发现是:
https://childapi30.xxx.com/course/getCourseList?auth_token=MTU2OTkxNjU3ObCtxKuCe7rcr92Mcg&uid=37285135&start=20&rows=20&nature_id=507&sort=new×tamp=1568874081&sign=36643c0ed1690b76e6587989fbba0fc4
(24 minutes ago updated )
"content": "{\"status\":401,\"msg\":\"\\u8ba4\\u8bc1\\u8fc7\\u671f\"}",
fetch
{
"save": {
"curPageDict": {
"auth_token": "MTU2OTkxNjU3ObCtxKuCe7rcr92Mcg",
"nature_id": "507",
"rows": 20,
"sign": "36643c0ed1690b76e6587989fbba0fc4",
"sort": "new",
"start": 20,
"timestamp": 1568874081,
"uid": "37285135"
},
"natureLevelDict": {
"level1": {
"nature_id": "359",
"nature_title": "动漫世界"
},
"level2": {
"nature_id": "507",
"nature_title": "综合动漫",
"pic": "https://img.xxx.cn/2017-07-10/59635eea1cdcd.png",
"pid": "359"
}
}
},
"validate_cert": false
}
process
{
"callback": "getCourseListCallback"
}即:
nature id是507
是其中一个二级分类
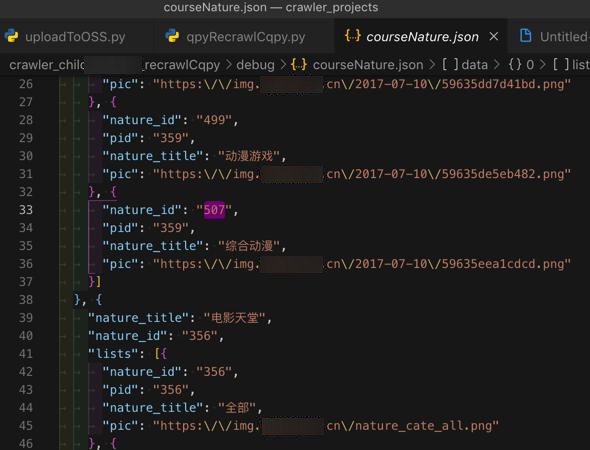
的
“start”: 20,
第二页就报错了:
-》那说明此分类后面,还有很多数据没有爬取到
-》所以,再去单独调整代码,去重新爬取这个子分类
再去更新代码:
# 优先爬取:动画片=动漫世界
NATURE_ID_CARTOON = "359"
HighPriorityVideoTypeIdList = [NATURE_ID_CARTOON]
# 部分二级爬取失败: "507"="综合动漫
NATURE_ID_CARTOON_COMPOSITE_CARTOON = "507"
FailedVideoTypeIdCartoonLevel2List = [NATURE_ID_CARTOON_COMPOSITE_CARTOON]
if curNatureId == parentNatureId:
print("Omit to process level2 for is parent nature")
pass
else:
# self.processNatureLevel2(parentLevelDict, eachLevel2Nature)
# special for second crawl for only some level 2 failed
# TODO: when complete, need comment out
if curNatureId in FailedVideoTypeIdCartoonLevel2List:
self.processNatureLevel2(parentLevelDict, eachLevel2Nature)
else:
print("Omit to process level2 for not failed = crawled before")然后重新部署,可以正常继续爬取缺失的二级507了:

目前

已下载共 5700多了:
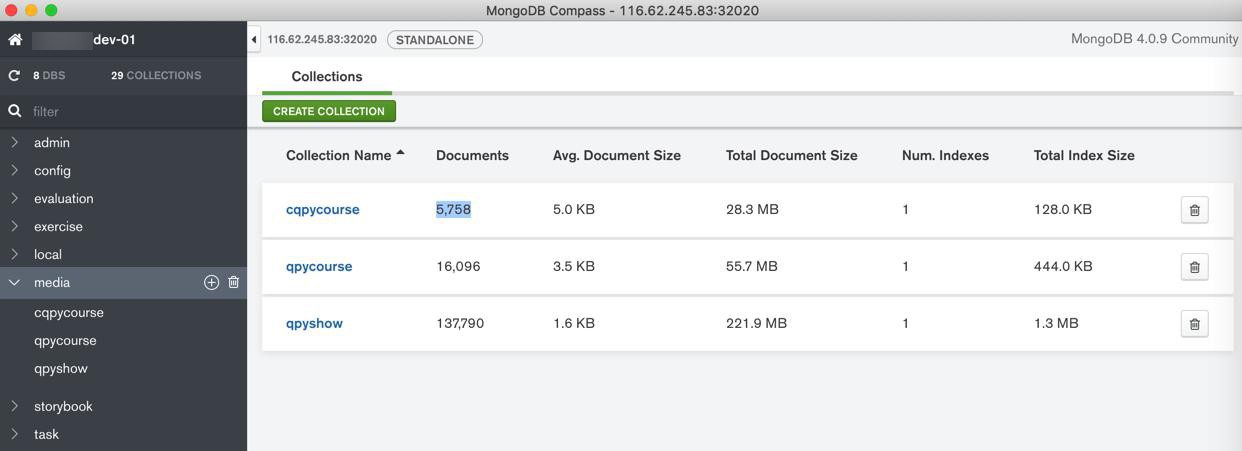
共17G:
# cd /mnt/xxx_20180101/crawler/crawled_data/xxx_recrawlCqpy [root@xxx-dev-01 xxx_recrawlCqpy]# du -sh . 17G .
最后是:

[root@xxx-dev-01 ~]# cd /mnt/xxx_20180101/crawler/crawled_data/xxx_recrawlCqpy [root@xxx-dev-01 xxx_recrawlCqpy]# ll total 188 drwxr-xr-x 8497 root root 188416 Sep 19 18:11 course [root@xxx-dev-01 xxx_recrawlCqpy]# du -sh . 31G .
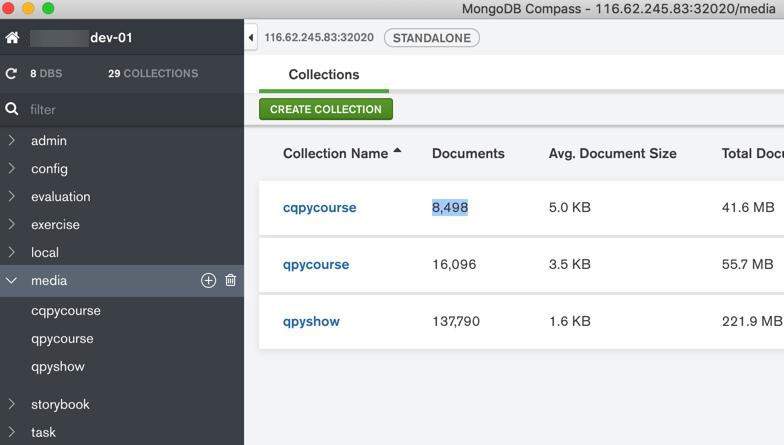
目前共:
- 总个数:8500个
- 总大小:31G
对于动画片,后续就剩上传到OSS了:
【已解决】上传少儿xxxcourse的数据到OSS
接着:
【已解决】重爬少儿xxx的学习宝箱和其他分类的course视频
转载请注明:在路上 » 【未解决】重爬少儿趣配音的所有视频