折腾:
【未解决】破解安卓应用少儿xxx的源码以便于找到sign签名和auth_token的算法计算逻辑
期间,大概搞懂了sign的计算逻辑,以及有调试抓包出来的具体的值。
现在就去想办法尝试用python实现具体的计算逻辑。
api请求的值:
https://childapi30.xxx.com/square/courseNature?sign=05fd469214bb41be9c364e3d1630368c×tamp=1568620889&uid=37285135&auth_token=MTU2OTkxNjU3ObCtxKuCe7rcr92Mcg sign 05fd469214bb41be9c364e3d1630368c timestamp 1568620889 uid 37285135 auth_token MTU2OTkxNjU3ObCtxKuCe7rcr92Mcg
希望用Python从
- timestamp 1568620889
- uid 37285135
- auth_token MTU2OTkxNjU3ObCtxKuCe7rcr92Mcg
计算出:
sign 05fd469214bb41be9c364e3d1630368c
其中反编译出的java相关代码是:
sources/com/fz/lib/net/FZNetApiManager.java
private void a(Map<String, String> map) {
StringBuilder sb = new StringBuilder();
if (map != null) {
long currentTimeMillis = (System.currentTimeMillis() / 1000) + this.a.a.a();
StringBuilder sb2 = new StringBuilder();
sb2.append(currentTimeMillis);
sb2.append("");
map.put("timestamp", sb2.toString());
HashMap hashMap = new HashMap(map);
hashMap.put("security_key", this.a.a.b());
ArrayList arrayList = new ArrayList(hashMap.entrySet());
Collections.sort(arrayList, new Comparator<Entry<String, String>>() {
/* renamed from: a */
public int compare(Entry<String, String> entry, Entry<String, String> entry2) {
return ((String) entry.getKey()).compareTo((String) entry2.getKey());
}
});
Iterator it = arrayList.iterator();
while (it.hasNext()) {
Entry entry = (Entry) it.next();
sb.append((String) entry.getKey());
sb.append((String) entry.getValue());
}
map.put("sign", FZNetUtils.a(sb.toString()));
}
}对应的:
(1)this.a.a.b()
此处目前判断是
sources/com/fz/childdubbing/provider/AppNetProvider.java
public <T> FZINetConfig<T> createNetConfig(final Class<T> cls, final String str) {
return new FZINetConfig<T>() {
...
public String b() {
return "qpy68c681cbdcd102363";
}中的b()的:
“qpy68c681cbdcd102363”
(2)FZNetUtils的代码
sources/com/fz/lib/net/utils/FZNetUtils.java
public class FZNetUtils {
public static String a(String str) {
if (TextUtils.isEmpty(str)) {
return "";
}
try {
byte[] digest = MessageDigest.getInstance("MD5").digest(str.getBytes("UTF-8"));
StringBuilder sb = new StringBuilder(digest.length * 2);
for (byte b : digest) {
byte b2 = b & 255;
if (b2 < 16) {
sb.append("0");
}
sb.append(Integer.toHexString(b2));
}
return sb.toString();
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("Huh, MD5 should be supported?", e);
} catch (UnsupportedEncodingException e2) {
throw new RuntimeException("Huh, UTF-8 should be supported?", e2);
}
}
}现在需要:
想办法看懂前面的a()的代码
以及再去看懂并实现FZNetUtils的a()的,计算MD5的digest的逻辑
另外,无意间通过搜:
FZNetUtils
FZ NetUtils xxx
发现:
之前以为的:FZ=封装的拼音
实际上是:FZ=菲助的拼音 -》 公司全名是:杭州菲助科技有限公司 -》xxx 英语xxx 是该公司开发的
然后去写Python代码
去参考自己之前的:
【已解决】Python中计算字符串的md5值
【已解决】Python实现小花生中addSignature的md5加密生成签名的逻辑
【已解决】小花生中如何得到getToken的计算逻辑以便得到正确的md5值可以正常请求接口
去计算md5值试试
但是先要搞懂输入的值
根据:
Iterator it = arrayList.iterator();
while (it.hasNext()) {
Entry entry = (Entry) it.next();
sb.append((String) entry.getKey());
sb.append((String) entry.getValue());
}
map.put("sign", FZNetUtils.a(sb.toString()));其中arrayList的逻辑
ArrayList arrayList = new ArrayList(hashMap.entrySet());
Collections.sort(arrayList, new Comparator<Entry<String, String>>() {
/* renamed from: a */
public int compare(Entry<String, String> entry, Entry<String, String> entry2) {
return ((String) entry.getKey()).compareTo((String) entry2.getKey());
}
});是去sort排序,感觉是根据key的字母大小去排序的
而hashMap是:
HashMap hashMap = new HashMap(map);
hashMap.put("security_key", this.a.a.b());是原先map中额外加了
“security_key”: “qpy68c681cbdcd102363”
而map本身是:
long currentTimeMillis = (System.currentTimeMillis() / 1000) + this.a.a.a();
StringBuilder sb2 = new StringBuilder();
sb2.append(currentTimeMillis);
sb2.append("");
map.put("timestamp", sb2.toString());即:
传入的map中,加了:
“timestamp”: “1568620889”
其中:1568620889是此处的调试抓包得到的值,先用此值去调试python的md5值的计算
但是传入的map中,是否有其他参数,还要去确认
去搜索FZNetApiManager看看哪些地方调用到了
是否是传入了额外的
之前看到的:
Interceptor
的
FZNetApiManager.this.a.a.getParams()
的带auth_token和uid的hash的map
即:auth_token和uid
不确定加了还是没加
通过:
class FZParamsInterceptor implements Interceptor {
public FZParamsInterceptor() {
}
public Response intercept(Chain chain) throws IOException {
return FZNetApiManager.this.a(chain, FZNetApiManager.this.a.a.getParams());
}
}中的
return FZNetApiManager.this.a(chain, FZNetApiManager.this.a.a.getParams());
感觉是:
加了,调用
FZNetApiManager.this.a.a.getParams()
获取到auth_token和uid的hashMap了
然后再去调用上面的a(),去计算出sign,加到原先的header中了
所以是:
对于header参数=map
- 先去加了(相对固定的)auth_token和(固定的)uid
- 再去加了timestamp
- 最后加了sign值
- 而中间计算sign时:
- 基于(已有auth_token和uid,以及timestamp的)map
- 再去基于key的字母去排序
- 再去生成 每个key+每个value 的 最终的字符串
- 最后再去根据字符串去计算md5的digest
至此,可以去尝试写python代码了。
所以此处就是:
要计算sign的字符串是:
- 排序后
- auth_token MTU2OTkxNjU3ObCtxKuCe7rcr92Mcg
- uid 37285135
- timestamp 1568620889
- key+value合并成字符串
- auth_tokenMTU2OTkxNjU3ObCtxKuCe7rcr92Mcguid37285135timestamp1568620889
- 去计算MD5的digest值
用python实现后续的逻辑:
byte[] digest = MessageDigest.getInstance("MD5").digest(str.getBytes("UTF-8"));
StringBuilder sb = new StringBuilder(digest.length * 2);
for (byte b : digest) {
byte b2 = b & 255;
if (b2 < 16) {
sb.append("0");
}
sb.append(Integer.toHexString(b2));
}
return sb.toString();得到最终的32位的sign值
-》希望是前面抓包出来的:05fd469214bb41be9c364e3d1630368c
-》说明java的
MessageDigest.getInstance(“MD5”).digest(str.getBytes(“UTF-8”));
得到的是16位的值
结果:
- 字符串 auth_tokenMTU2OTkxNjU3ObCtxKuCe7rcr92Mcguid37285135timestamp1568620889
- 16位 小写 3137e04e92d676c0
- 16位 大写 3137E04E92D676C0
- 32位 小写 d8ac25e23137e04e92d676c03b773ec6
- 32位 大写 D8AC25E23137E04E92D676C03B773EC6
去看看java的Integer.toHexString
要去找python的实现
python java Integer.toHexString
突然发现,难道前面的md5加密出来,不是16位?
java MessageDigest MD5 digest
java MessageDigest.getInstance(“MD5”).digest
好像就是parseStrToMd5L32=32位小写MD5
所以此处就是:
想办法把java的:
byte[] digest = MessageDigest.getInstance("MD5").digest(str.getBytes("UTF-8"));
StringBuilder sb = new StringBuilder(digest.length * 2);
for (byte b : digest) {
byte b2 = b & 255;
if (b2 < 16) {
sb.append("0");
}
sb.append(Integer.toHexString(b2));
}
return sb.toString();换成Python
根据:
好像就是parseStrToMd5L32=32位小写MD5
所以好像就是:
直接换成python的md5的digest就可以了?
去试试
不过至少是在线网站中
输入
auth_tokenMTU2OTkxNjU3ObCtxKuCe7rcr92Mcguid37285135timestamp1568620889
输出的结果32位的:
d8ac25e23137e04e92d676c03b773ec6
不是我们要的
我们要的是
05fd469214bb41be9c364e3d1630368c
发现搞错sort排序了,应该是:
要计算sign的字符串是:
- 排序后
- auth_token MTU2OTkxNjU3ObCtxKuCe7rcr92Mcg
- timestamp 1568620889
- uid 37285135
- key+value合并成字符串
- auth_tokenMTU2OTkxNjU3ObCtxKuCe7rcr92Mcgtimestamp1568620889uid37285135
- 去计算MD5的digest值
看看
auth_tokenMTU2OTkxNjU3ObCtxKuCe7rcr92Mcgtimestamp1568620889uid37285135
在线计算结果是
- 字符串 auth_tokenMTU2OTkxNjU3ObCtxKuCe7rcr92Mcgtimestamp1568620889uid37285135
- 16位 小写 aabe0c4661ea4ebc
- 16位 大写 AABE0C4661EA4EBC
- 32位 小写 4c8be35eaabe0c4661ea4ebc10613951
- 32位 大写 4C8BE35EAABE0C4661EA4EBC10613951
那么去试试
- 参数:
- timestamp 1568620889
- 的字符串
- timestamp1568620889
的在线md5的结果
- 字符串 timestamp1568620889
- 16位 小写 a12c0071b4d31c5c
- 16位 大写 A12C0071B4D31C5C
- 32位 小写 12865460a12c0071b4d31c5c17cb3e7a
- 32位 大写 12865460A12C0071B4D31C5C17CB3E7A
也不是
晕死了,忘了加上security_key了
去重新计算
- 排序后
- auth_token MTU2OTkxNjU3ObCtxKuCe7rcr92Mcg
- security_key qpy68c681cbdcd102363
- timestamp 1568620889
- uid 37285135
- key+value合并成字符串
- auth_tokenMTU2OTkxNjU3ObCtxKuCe7rcr92Mcgsecurity_keyqpy68c681cbdcd102363timestamp1568620889uid37285135
- 去计算MD5的digest值
在线计算,果然是:
- 字符串 auth_tokenMTU2OTkxNjU3ObCtxKuCe7rcr92Mcgsecurity_keyqpy68c681cbdcd102363timestamp1568620889uid37285135
- 16位 小写 14bb41be9c364e3d
- 16位 大写 14BB41BE9C364E3D
- 32位 小写 05fd469214bb41be9c364e3d1630368c
- 32位 大写 05FD469214BB41BE9C364E3D1630368C
是我们要的
05fd469214bb41be9c364e3d1630368c
然后去写代码,实现上述完整的参数计算出sign的过程
期间遇到:
【已解决】Python中根据key去对字典排序
计算sign值的核心代码如下:
def generateParaSign():
curTimestamp = getCurTimestamp() # 1568769723
# for debug
curTimestamp = 1568620889
originHeadersDict = {
"uid": "37285135",
"security_key": "qpy68c681cbdcd102363",
"timestamp": curTimestamp,
"auth_token": "MTU2OTkxNjU3ObCtxKuCe7rcr92Mcg",
}
print("originHeadersDict=%s" % originHeadersDict)
sortedHeadersDict = sortDictByKey(originHeadersDict)
print("sortedHeadersDict=%s" % sortedHeadersDict)
strToMd5 = ""
for eachKey, eachValue in sortedHeadersDict.items():
keyValueStr = "%s%s" % (eachKey, eachValue)
strToMd5 += keyValueStr
signMd5 = generateMd5(strToMd5)
print("signMd5=%s" % signMd5)调试输出:
originHeadersDict={'uid': '37285135', 'security_key': 'qpy68c681cbdcd102363', 'timestamp': 1568620889, 'auth_token': 'MTU2OTkxNjU3ObCtxKuCe7rcr92Mcg'}
sortedHeadersDict=OrderedDict([('auth_token', 'MTU2OTkxNjU3ObCtxKuCe7rcr92Mcg'), ('security_key', 'qpy68c681cbdcd102363'), ('timestamp', 1568620889), ('uid', '37285135')])
signMd5=05fd469214bb41be9c364e3d1630368c符合我们要的结果。
用在线计算出的最新的时间戳
1568777389
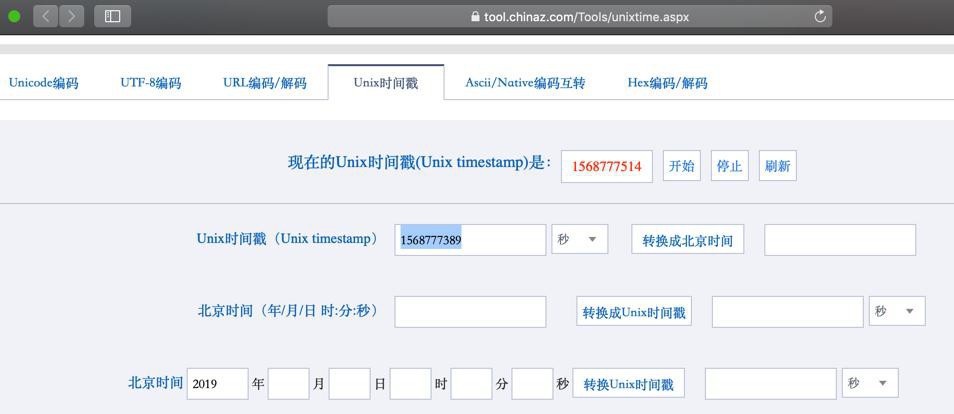
然后用代码去计算出sign值:9d9ff4ace8ca3b6e3a5b8ff648f1b9f8
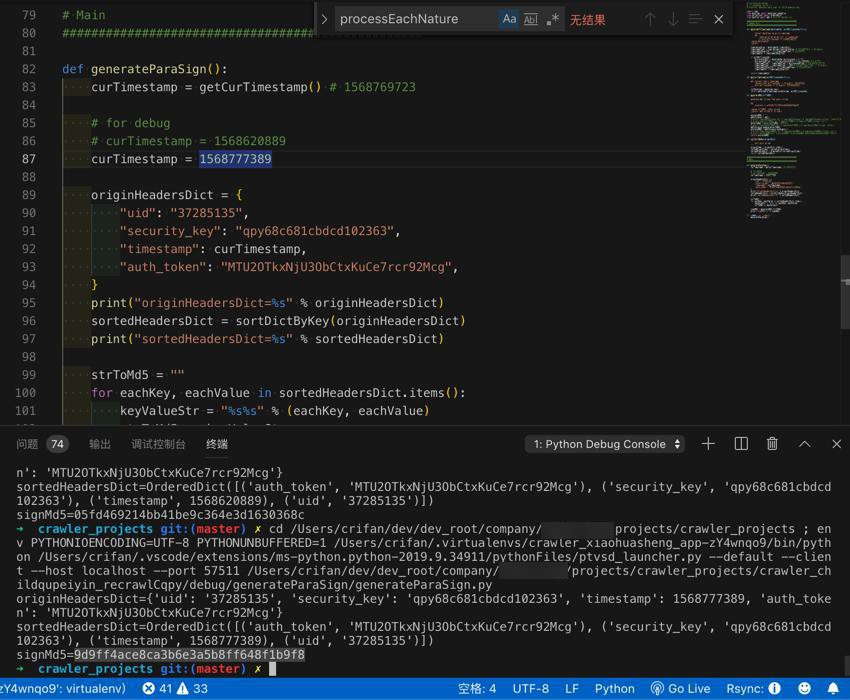
再去用postman测试sign值 是否有效,发现是有效的,可以获取api的数据的:
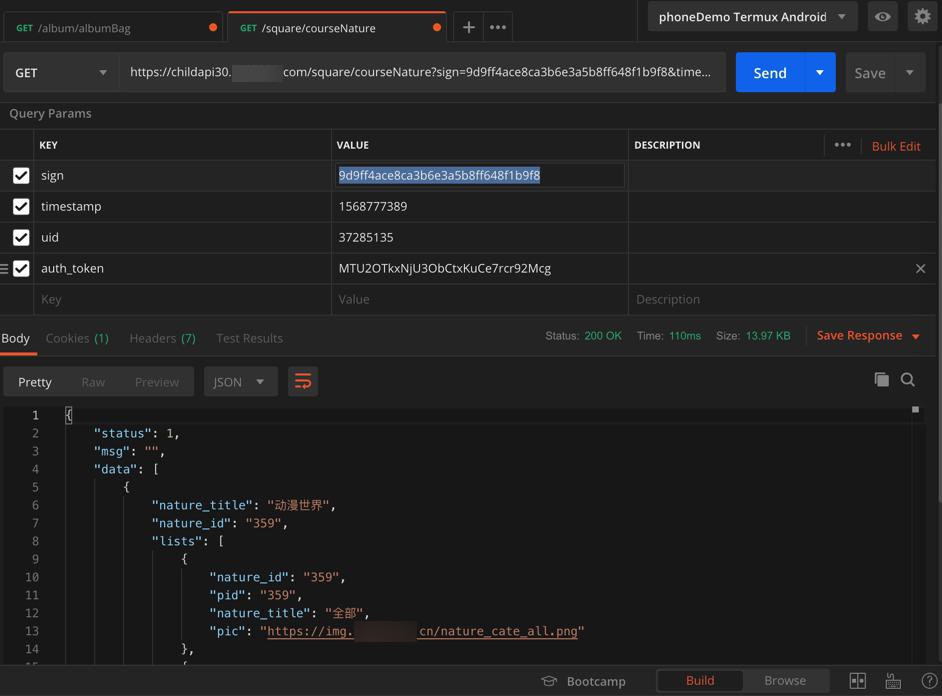
那就可以继续写代码,获取其他api数据了。
【总结】
最终,计算少儿xxx的api的参数的sign值的python代码如下:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Function: Generate para sign for child xxx api
import time
from datetime import datetime,timedelta
from collections import OrderedDict
from hashlib import md5 # only for python 3.x
##################################################
# Common Util
##################################################
def datetimeToTimestamp(datetimeVal, withMilliseconds=False) :
"""
convert datetime value to timestamp
eg:
"2006-06-01 00:00:00.123" -> 1149091200
if with milliseconds -> 1149091200123
:param datetimeVal:
:return:
"""
timetupleValue = datetimeVal.timetuple()
timestampFloat = time.mktime(timetupleValue) # 1531468736.0 -> 10 digits
timestamp10DigitInt = int(timestampFloat) # 1531468736
timestampInt = timestamp10DigitInt
if withMilliseconds:
microsecondInt = datetimeVal.microsecond # 817762
microsecondFloat = float(microsecondInt)/float(1000000) # 0.817762
timestampFloat = timestampFloat + microsecondFloat # 1531468736.817762
timestampFloat = timestampFloat * 1000 # 1531468736817.7621 -> 13 digits
timestamp13DigitInt = int(timestampFloat) # 1531468736817
timestampInt = timestamp13DigitInt
return timestampInt
def getCurTimestamp(withMilliseconds=False):
"""
get current time's timestamp
(default)not milliseconds -> 10 digits: 1351670162
with milliseconds -> 13 digits: 1531464292921
"""
curDatetime = datetime.now()
return datetimeToTimestamp(curDatetime, withMilliseconds)
def generateMd5(strToMd5) :
"""
generate md5 string from input string
eg:
xxxxxxxx -> af0230c7fcc75b34cbb268b9bf64da79
:param strToMd5: input string
:return: md5 string of 32 chars
"""
encrptedMd5 = ""
md5Instance = md5()
# print("type(md5Instance)=%s" % type(md5Instance)) # type(md5Instance)=<class '_hashlib.HASH'>
# print("type(strToMd5)=%s" % type(strToMd5)) # type(strToMd5)=<class 'str'>
bytesToMd5 = bytes(strToMd5, "UTF-8")
# print("type(bytesToMd5)=%s" % type(bytesToMd5)) # type(bytesToMd5)=<class 'bytes'>
md5Instance.update(bytesToMd5)
encrptedMd5 = md5Instance.hexdigest()
# print("type(encrptedMd5)=%s" % type(encrptedMd5)) # type(encrptedMd5)=<class 'str'>
# print("encrptedMd5=%s" % encrptedMd5) # encrptedMd5=3a821616bec2e86e3e232d0c7f392cf5
return encrptedMd5
def sortDictByKey(originDict):
"""
Sort dict by key
"""
originItems = originDict.items()
sortedOriginItems = sorted(originItems)
sortedOrderedDict = OrderedDict(sortedOriginItems)
return sortedOrderedDict
##################################################
# Main
##################################################
def generateParaSign():
curTimestamp = getCurTimestamp() # 1568769723
# for debug
# curTimestamp = 1568620889
curTimestamp = 1568777389
originHeadersDict = {
"uid": "37285135",
"security_key": "qpy68c681cbdcd102363",
"timestamp": curTimestamp,
"auth_token": "MTU2OTkxNjU3ObCtxKuCe7rcr92Mcg",
}
print("originHeadersDict=%s" % originHeadersDict)
sortedHeadersDict = sortDictByKey(originHeadersDict)
print("sortedHeadersDict=%s" % sortedHeadersDict)
strToMd5 = ""
for eachKey, eachValue in sortedHeadersDict.items():
keyValueStr = "%s%s" % (eachKey, eachValue)
strToMd5 += keyValueStr
signMd5 = generateMd5(strToMd5)
print("signMd5=%s" % signMd5)
# signMd5=9d9ff4ace8ca3b6e3a5b8ff648f1b9f8
if __name__ == "__main__":
generateParaSign()供参考。