折腾:
【未解决】Python的BeautifulSoup去实现提取带tag的HTML网页主体内容
期间,用BeautifulSoup去导出html网页内容到本地,主体内容没问题。
但是图片无法显示:
只可惜图片无法显示。
去看看为何图片没显示:
原来是:
图片
//www3.autoimg.cn/newsdfs/g25/M0A/1F/09/744x0_0_autohomecar__ChsEmF8TAFyAD0ZtAAqx8wGiNYQ437.jpg
被加上上了前缀:file:
变成了:
file://www3.autoimg.cn/newsdfs/g25/M0A/1F/09/744x0_0_autohomecar__ChsEmF8TAFyAD0ZtAAqx8wGiNYQ437.jpg
而不是原先希望的:
的https:的前缀:
https://www3.autoimg.cn/newsdfs/g25/M0A/1F/09/744x0_0_autohomecar__ChsEmF8TAFyAD0ZtAAqx8wGiNYQ437.jpg
所以,此处去找找,如何保留图片前缀
beautifulsoup image prefix http: file:
beautifulsoup image prefix http not file
突然感觉:此处好像问题不算是bs的问题
算是源码本身的问题。
去换个别的网页试试
-》
去试试,结果问题依旧:
图片前缀也是file:
导致无法显示
那去试试,转换成html之前,用bs把所有图片,如果前缀是//,那就都换成:https: ?
但是此处发现实际图片前缀是http:
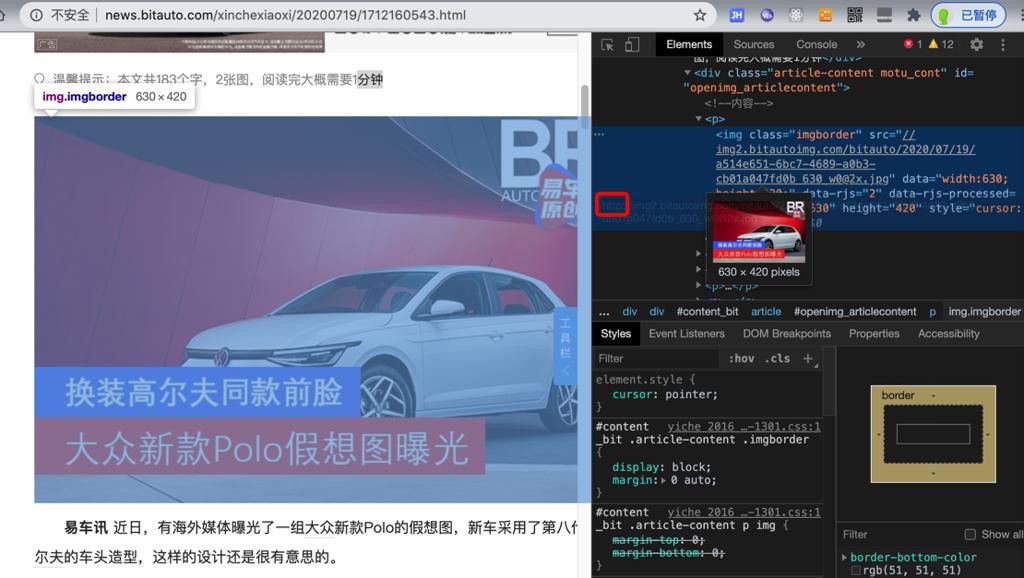
所以要搞清楚加http还是https
根据代码发现了:
# 【图】超级播报:特斯拉市值背后的技术趋势_汽车之家 # postUrl = "https://www.autohome.com.cn/news/202007/1014507.html?pvareaid=3311314" # 【图文】大众新款Polo假想图曝光 换装高尔夫同款前脸_新闻中心_易车 postUrl = "http://news.bitauto.com/xinchexiaoxi/20200719/1712160543.html"
直接根据输入的url的前缀决定是否https还是http即可。
去加上代码试试
对于:
<img class="imgborder" src="//img2.bitautoimg.com/bitauto/2020/07/19/a514e651-6bc7-4689-a0b3-cb01a047fd0b_630_w0@2x.jpg" data="width:630;height:420;" data-rjs="2" data-rjs-processed="true" width="630" height="420" style="cursor: pointer;">
需要去:
找到img,其src是//开头的
然后就加上 当前url的http后https 和冒号
【总结】
用代码:
# repace image src // to http:// or https://
# <img class="imgborder" src="//img2.bitautoimg.com/bitauto/2020/07/19/a514e651-6bc7-4689-a0b3-cb01a047fd0b_630_w0@2x.jpg" data="width:630;height:420;" data-rjs="2" data-rjs-processed="true" width="630" height="420" style="cursor: pointer;">
doubleSlashP = re.compile("^//")
imageSoupList = soup.find_all("img", attrs={"src": doubleSlashP})
for eachImageSoup in imageSoupList:
curSrc = eachImageSoup.attrs["src"]
fullSrc = ImageSrcPrefix + curSrc
eachImageSoup.attrs["src"] = fullSrc即可输出:
<img alt="" class="s" height="26" src="http://image.bitautoimg.com/appimage/cheyou/h/20191126/w242_h31_0f0af8224e2d402c967c4588f1033f71.png" width="195"/>
效果:
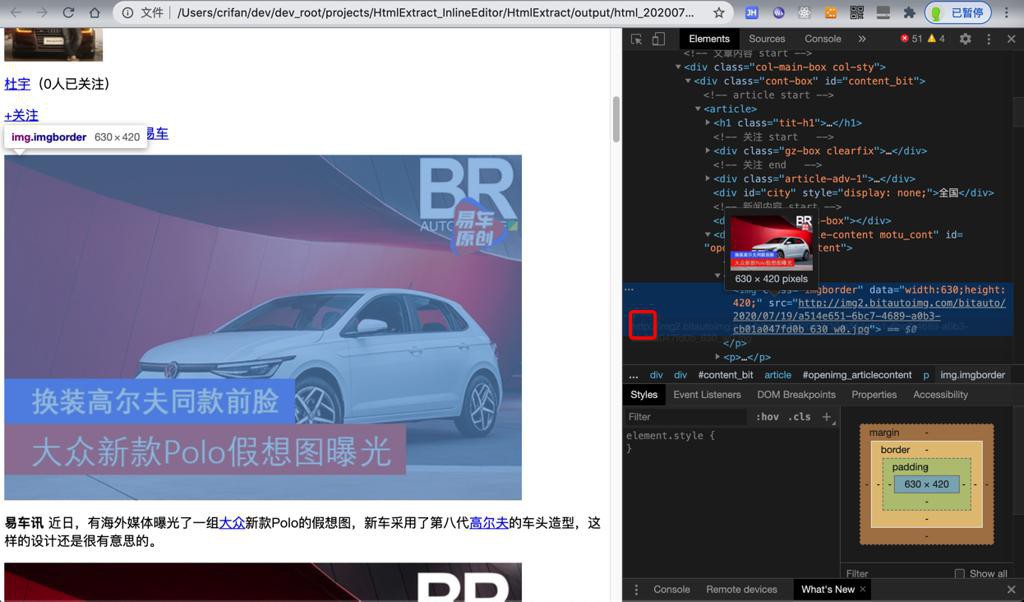
是http:开头的,图片可以显示了。
转载请注明:在路上 » 【已解决】BeautifulSoup导出的网页内容中图片无法显示原因是把前缀https:变成file:了