Python代码中,有dict,其中有个float值:
curSaleDict = {
"saleId": saleId,
"personalSaleMoney": personalSaleMoney,
"saleTime": saleTime,
}值:
Added: {'saleId': 'mo1212121212', 'personalSaleMoney': 8703.6162515, 'saleTime': Timestamp('2021-06-07 10:05:20')}其中代码判断逻辑是:
根据dict,直接去判断是否相等,决定是否已经在全局dict中了:
if curSaleDict in gLoadedSaleMoneyDict.values():
print("!!! Duplicated sale record: %s" % curSaleDict)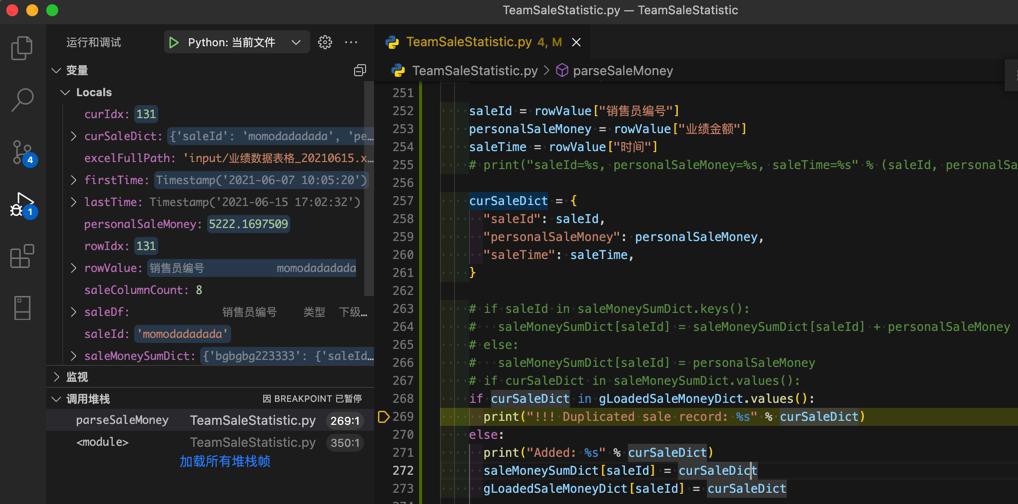
但是后来发现:
对于,肉眼看起来相同的值,却没有被判断出是相同。
目前怀疑是:float值 pandas解析期间,表面看起来一样,其实内部精度有时候不同,导致值不同。
去想办法验证此思路:暂时把float都改为int,看看是否是漏判,如果没漏判,说明就是float值导致的
好像不是float的原因:
对于:
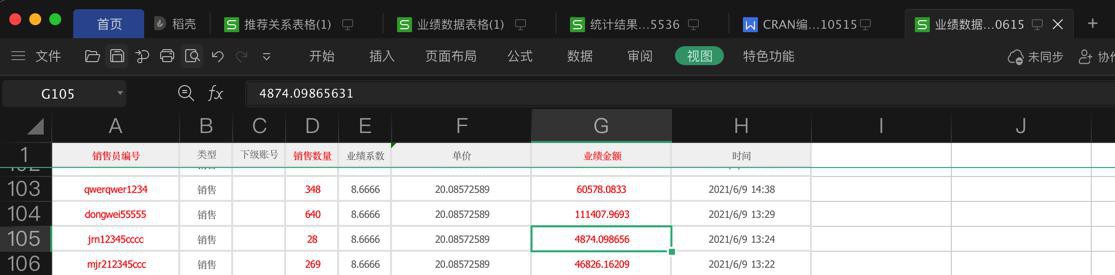
另外excel中已存在:
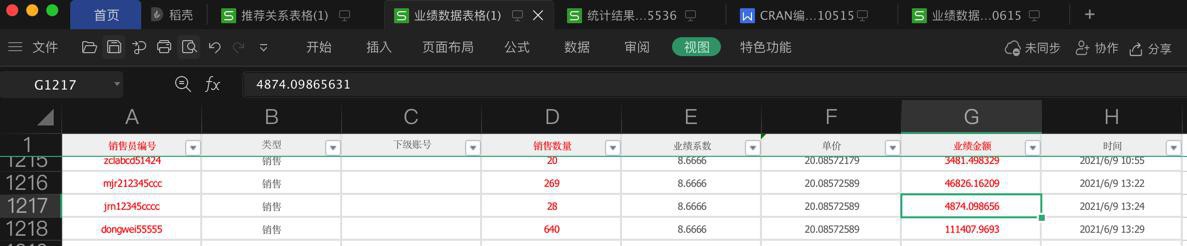
且此处只已改为int的:4874
Added: {'saleId': 'jrn12345cccc', 'personalSaleMoney': 4874, 'saleTime': Timestamp('2021-06-09 13:24:50')}结果还是:逻辑失效,而被加进来了。
而不是希望的:判断出重复,忽略掉
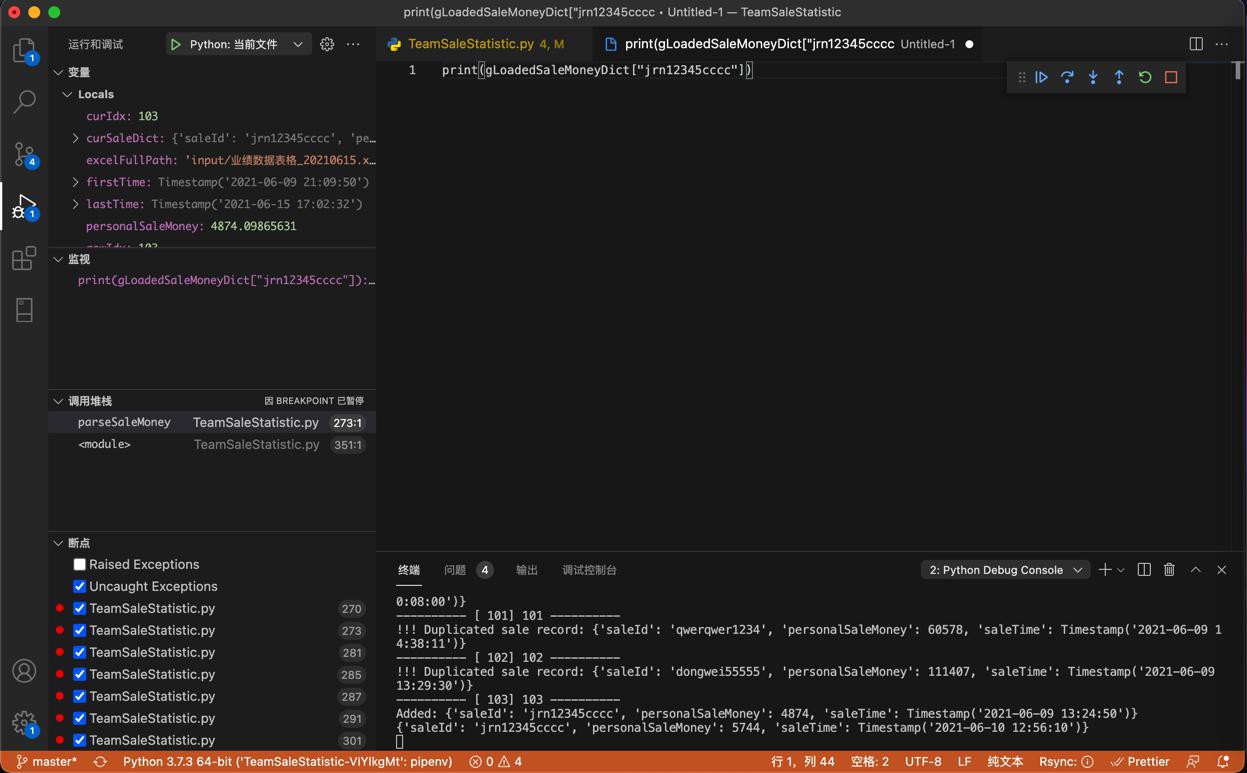
不过,通过调试打印后发现:
此处不是由于float,甚至也不是由于可能的Timestamp
而是:
本身同一个id中,之前有多个值:
对于:
---------- [ 103] 103 ----------
Added: {'saleId': 'jrn12345cccc', 'personalSaleMoney': 4874, 'saleTime': Timestamp('2021-06-09 13:24:50')}添加 监视 代码:
print(gLoadedSaleMoneyDict["jrn12345cccc"])
输出:
{'saleId': 'jrn12345cccc', 'personalSaleMoney': 5744, 'saleTime': Timestamp('2021-06-10 12:56:10')}-》很明显,是另外一个时间点的,另外的销售业绩。
-》说明之前是,同一个人,可能在不同时间点,有多个销售业绩的
-》说明自己之前代码逻辑,处理有误,去更新支持这个逻辑。
最后是,改为record的list,然后再判断是否在里面:
historySaleRecordDictList, historySaleTimeDict = loadSaleRecord(SaleHistoryFullPath)
def loadSaleRecord(excelFullPath):
if curSaleDict in gLoadedSaleRecordDictList:
print("!!! Duplicated sale record: %s" % curSaleDict)
else:
print("Added: %s" % curSaleDict)
# saleRecordDictList[saleId] = curSaleDict
# gLoadedSaleRecordDictList[saleId] = curSaleDict
saleRecordDictList.append(curSaleDict)
gLoadedSaleRecordDictList.append(curSaleDict)
。。。即可正常判断 dict是否在 dict的list 中了。
转载请注明:在路上 » 【无需解决】Python中判断dict是否存在的逻辑失效