折腾:
【已解决】PySpider运行批量下载时报错:HTTP 599 Operation timed out after milliseconds with out of bytes received
期间,PySpider可以正常高速下载资源了,直到界面中显示没有新增请求了。
但是后来从下载的数据中发现,部分url是缺失没有下载的。
比如:
"lessonPlanFirstPictureUrl": "https://img.xiaohuasheng.cn/20180906140226607_d0bbe84eda393a459c63d4587e73cba1.jpg",
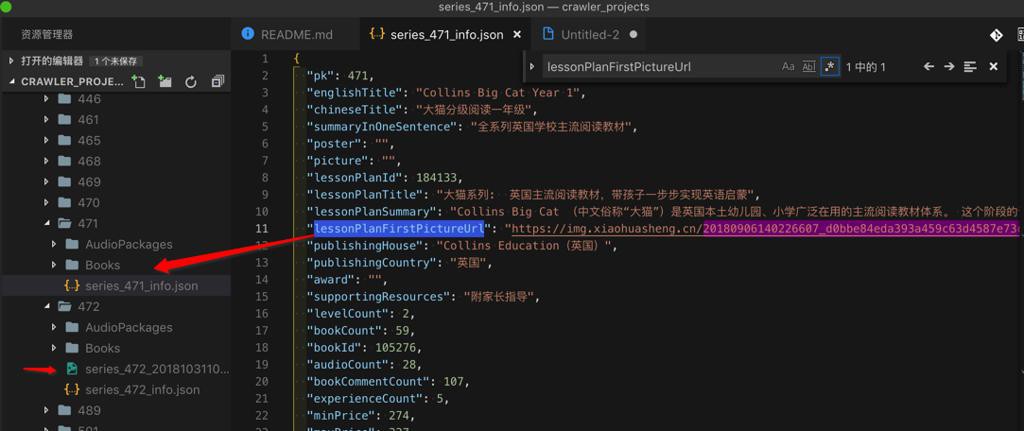
即,此处是有:
lessonPlanFirstPictureUrl
的图片的url的,但是却没有下载到图片。
所以需要想办法搞清楚,PySpider,到底是什么原因导致,虽然显示下载完成了,实际上缺失部分资源的url没有下载。
然后发现一个怪异事情:
此处Control+C去终止PySpider的运行后,重新运行后。
界面上把status状态改为别的,比如STOP后再改回RUNNING,结果竟然又开始新增了一些url请求,开始继续下载了一些内容
但是没一会,又停止,没有新增请求了:
但是郁闷的是,刚才缺少的图片,还是没有下载到。
所以还是之前的问题:
PySpider无法彻底完全下载,总是,不知何故,会缺失部分url没有下载
PySpider 无法完全下载 缺失url
PySpider 没有全部下载 缺失url
刚才是怀疑,难道上面图片url有多个,之前下载过,重复了,所以没有下载?
去搜了下,只有这一个:
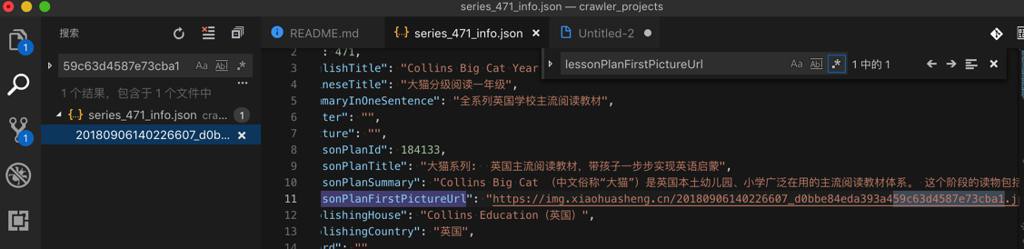
所以不是url重复的问题。
去看了看,除了刚才的471外,最后更新的几个series中,其他也还有没下载图片的:
比如446
后记发现:
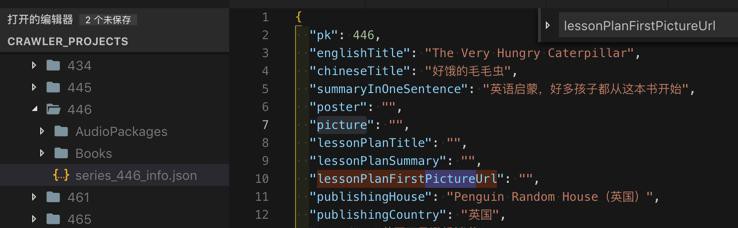
446本身就没图片地址,所以没有图片是正常的。
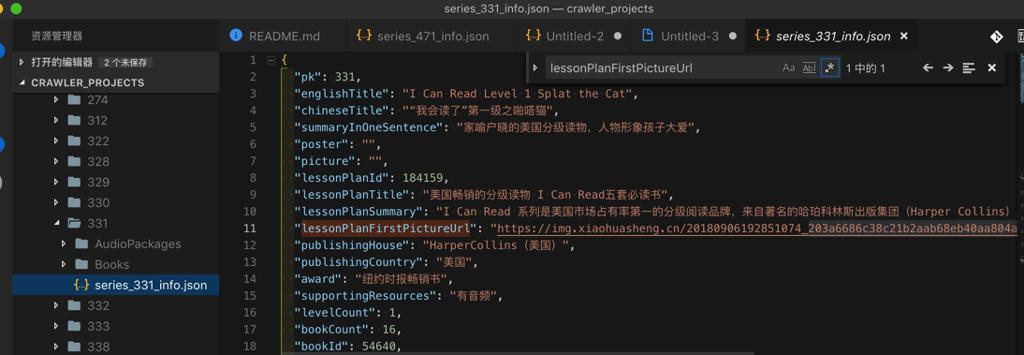
331是有图片url但是没下载到图片的:
-》而其他的系列,倒是大部分都有图片的:
去找找看,PySpider内部,是否还有pending的url?
去看看
- scheduler
- task
的db中是否还有残留的没发出的请求
参考自己的:
去mac中用DB Browser for SQLite
看看里面的数据
发现task.db
中,所有状态都是2,好像表示都下载完成了的:
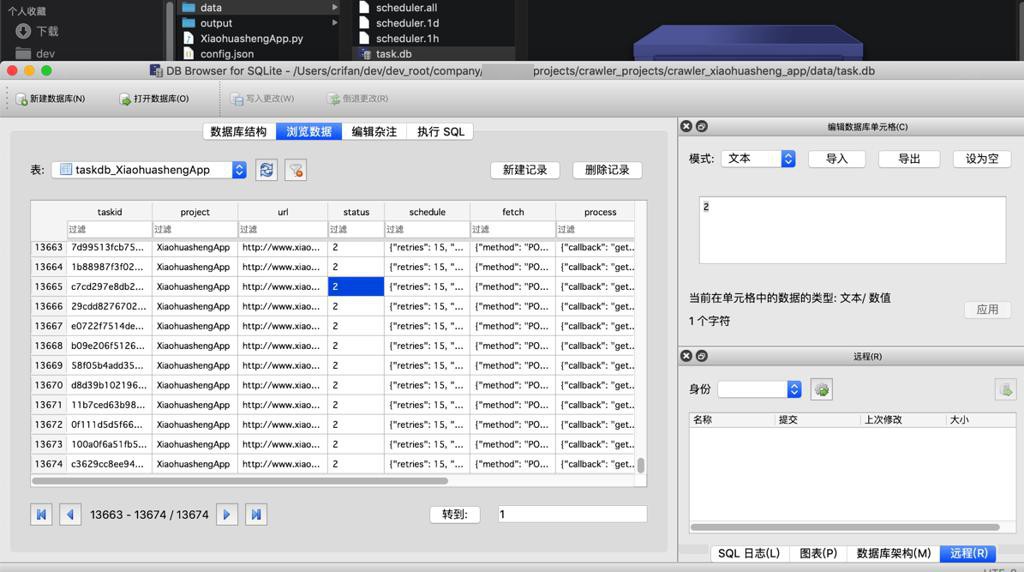
无意间还搜到,上面的却是图片的请求:
20180906140226607

继续研究,发现有fetch的值:
{
"save": {
"fileUrl": "https://img.xiaohuasheng.cn/20180906140226607_d0bbe84eda393a459c63d4587e73cba1.jpg",
"filename": "series_470_20180906140226607_d0bbe84eda393a459c63d4587e73cba1.jpg",
"saveFolder": "/Users/crifan/dev/dev_root/company/xxx/projects/crawler_projects/crawler_xiaohuasheng_app/output/series/470"
}
}突然发现,难道是:
图片文件名太长了?
或路径太长了?导致无法保存?
那去看看,另外几个 图片没有保存下来的文件名是不是也是一样长
以及 下载下来的图片中,是否有长文件名
发现是长文件名是可以正常保存的:
难道是:
PySpider运行期间,status的状态的改变(从RUNNING换成了STOP再换回RUNNING)导致了部分代码,比如此处的
self.downloadFile(imageFileInfo)
没有运行,导致部分图片没有被保存??
大概数了数90多series,估计只有不到10个是:
有图片url,但是没有下载到图片的
所以比例是不大的
具体原因,暂时未知,有空再深究。
考虑到,其他图片,好像都正常下载了:
所以个别图片没下载,暂时就忽略了。有空再说。
后来想到:
此处感觉是url请求下载图片没问题,但是回调函数中调用:
def saveDataToFile(fullFilename, binaryData):
"""save binary data info file"""
with open(fullFilename, 'wb') as fp:
fp.write(binaryData)
fp.close()
print("Complete save file %s" % fullFilename)
def downloadFileCallback(self, response):
fileInfo = response.save
print("fileInfo=%s" % fileInfo)
binData = response.content
fileFullPath = os.path.join(fileInfo["saveFolder"], fileInfo["filename"])
print("fileFullPath=%s" % fileFullPath)
saveDataToFile(fileFullPath, binData)
def downloadFile(self, fileInfo):
urlToDownload = fileInfo["fileUrl"]
print("urlToDownload=%s" % urlToDownload)
self.crawl(urlToDownload,
callback=self.downloadFileCallback,
save=fileInfo)去下载保存数据到文件,估计是saveDataToFile的问题。
-》所以后续可以去给saveDataToFile加上:
当保存异常时,log记录下来
-》后续看log,就知道哪些数据保存到file出错了。
-》或许上述几个丢失的图片,就是保存二进制数据到文件时出错而没有保存下来。
转载请注明:在路上 » 【未解决】PySpider看似下载完成但是部分图片资源没有下载