折腾:
【未解决】用Python爬虫框架PySpider实现爬虫爬取百度热榜内容列表
期间,先去返回热榜结果列表
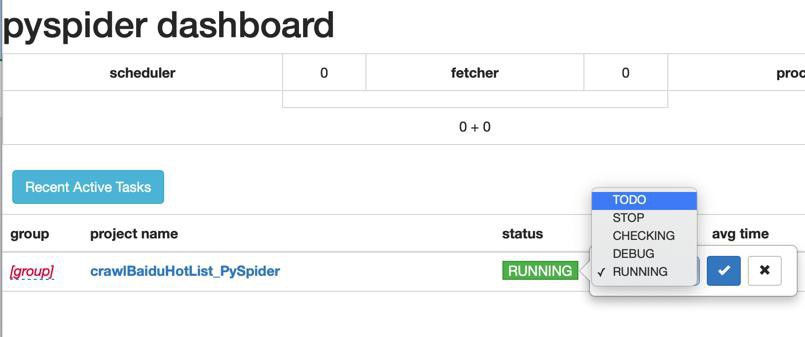
状态改为 RUNNING
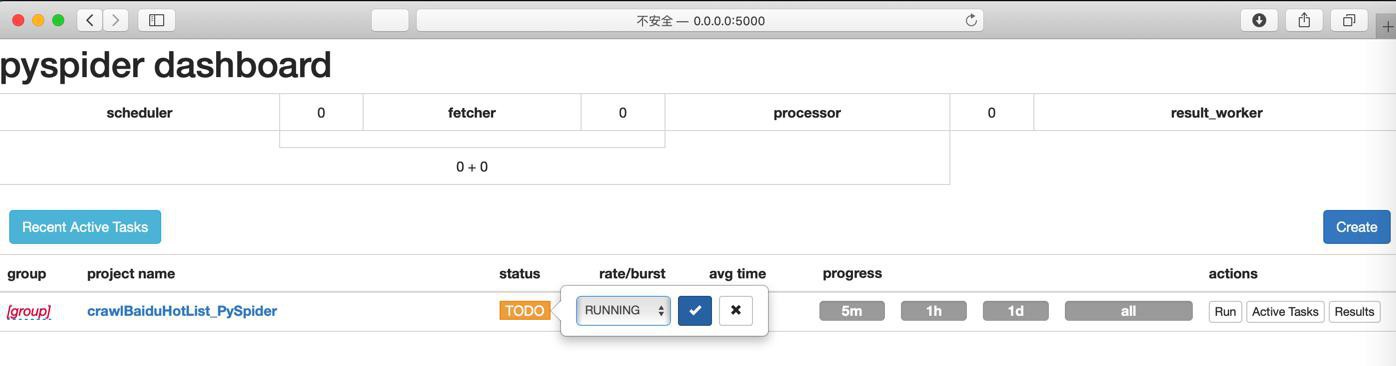
然后点击Run
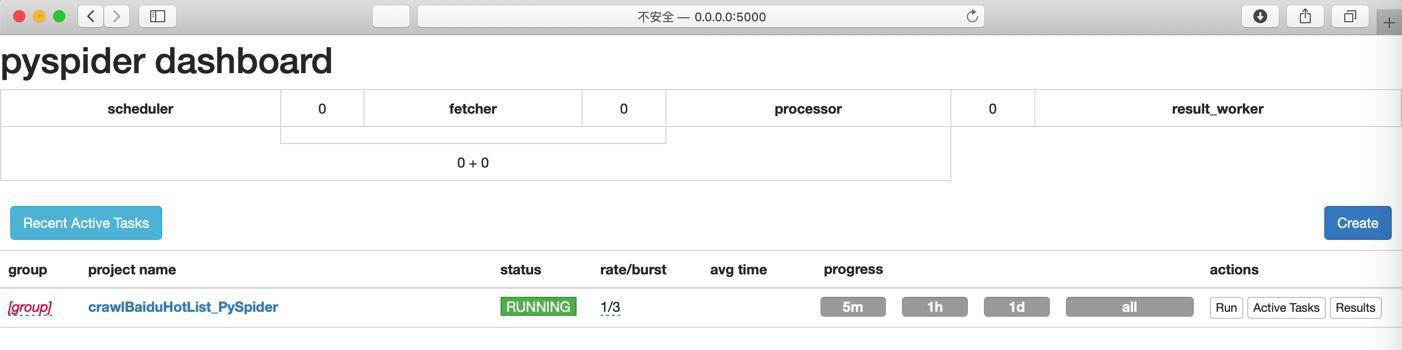
很快就运行完毕了:
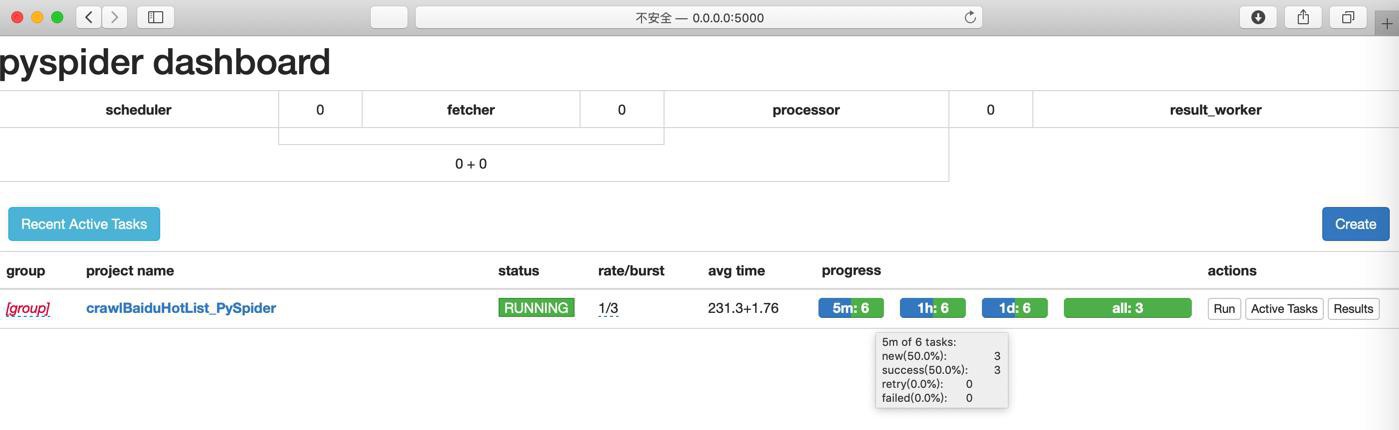
点击Results
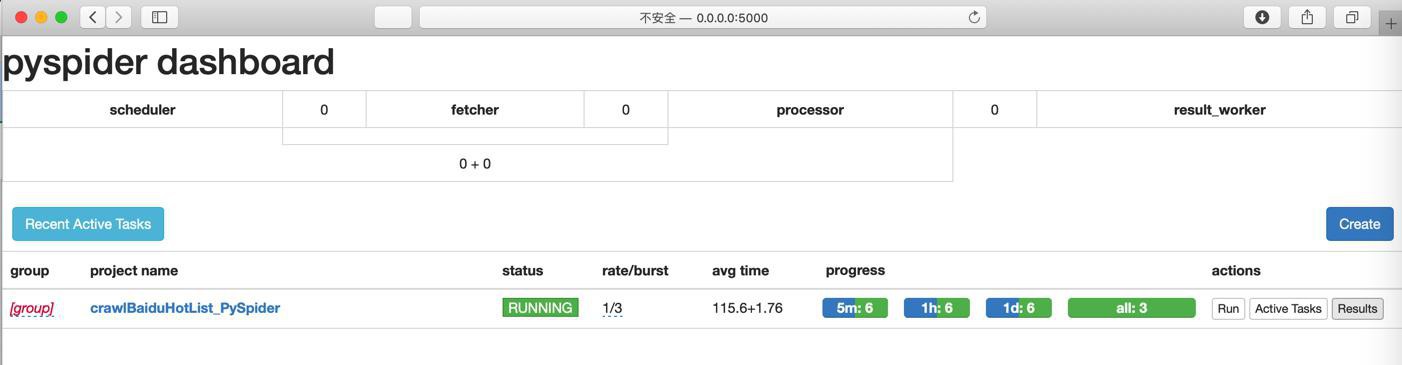
结果没数据:

说明代码有问题。
继续去调试
改回TODO 或STOP:
好像是:
titleItemList = response.doc('span[class="title-content-title"]').items()是个generator?
不能被使用,否则就空了?
改为:
# titleItemList = response.doc('span[class="title-content-title"]').items()
# print("titleItemList=%s" % titleItemList)
# for eachItem in titleItemList:
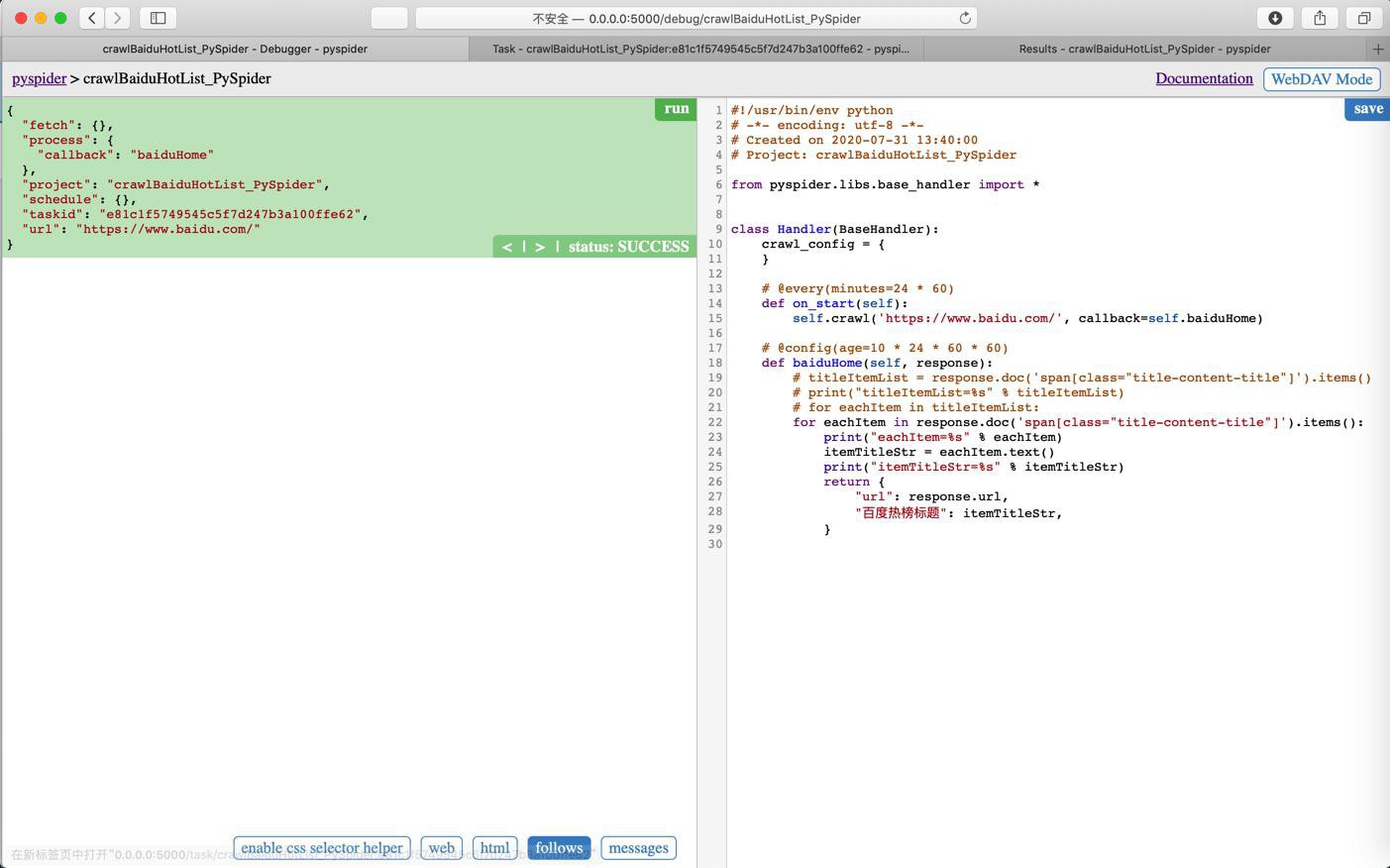
for eachItem in response.doc('span[class="title-content-title"]').items():结果:好像还是不行。
感觉是:
返回的dict中少了url?
去加上:
return {
"url": response.url,
"百度热榜标题": itemTitleStr,
}结果:
好像还是不对
点击Status:SUCCESS
跳转到:
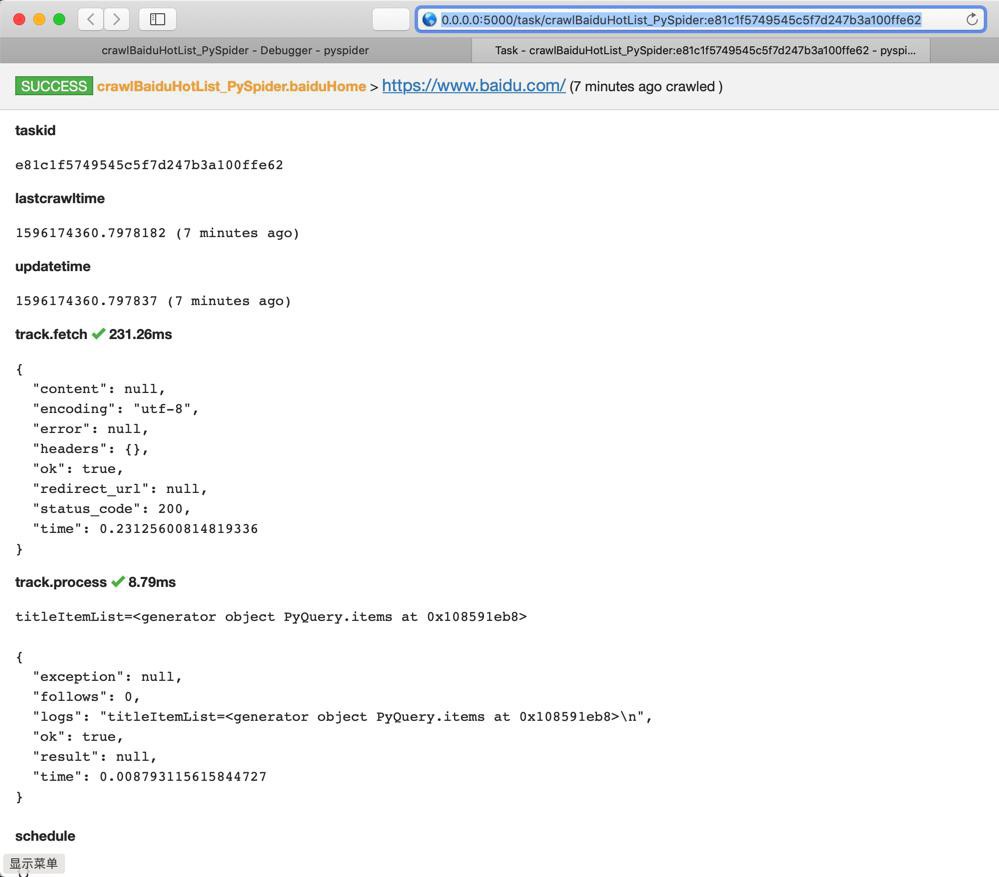
SUCCESS crawlBaiduHotList_PySpider.baiduHome >
https://www.baidu.com/
(7 minutes ago crawled )
taskid
e81c1f5749545c5f7d247b3a100ffe62
lastcrawltime
1596174360.7978182 (7 minutes ago)
updatetime
1596174360.797837 (7 minutes ago)
track.fetch 231.26ms
{ "content": null, "encoding": "utf-8", "error": null, "headers": {}, "ok": true, "redirect_url": null, "status_code": 200, "time": 0.23125600814819336 }
track.process 8.79ms
titleItemList=<generator object PyQuery.items at 0x108591eb8> { "exception": null, "follows": 0, "logs": "titleItemList=<generator object PyQuery.items at 0x108591eb8>\n", "ok": true, "result": null, "time": 0.008793115615844727 }
schedule
{}
fetch
{}
process
{ "callback": "baiduHome" }好像没问题?
参考:
代码:
好像写法没问题:
# for eachItem in response.doc('span[class="title-content-title"]').items():
titleItemList = response.doc('span[class="title-content-title"]').items()
print("titleItemList=%s" % titleItemList)
for eachItem in titleItemList:
print("eachItem=%s" % eachItem)
itemTitleStr = eachItem.text()
print("itemTitleStr=%s" % itemTitleStr)
return {
"url": response.url,
"百度热榜标题": itemTitleStr,
}但是调试没输出titleItemList之后的值
感觉是PyQuery的用法不对?
pyquery
写法没错啊
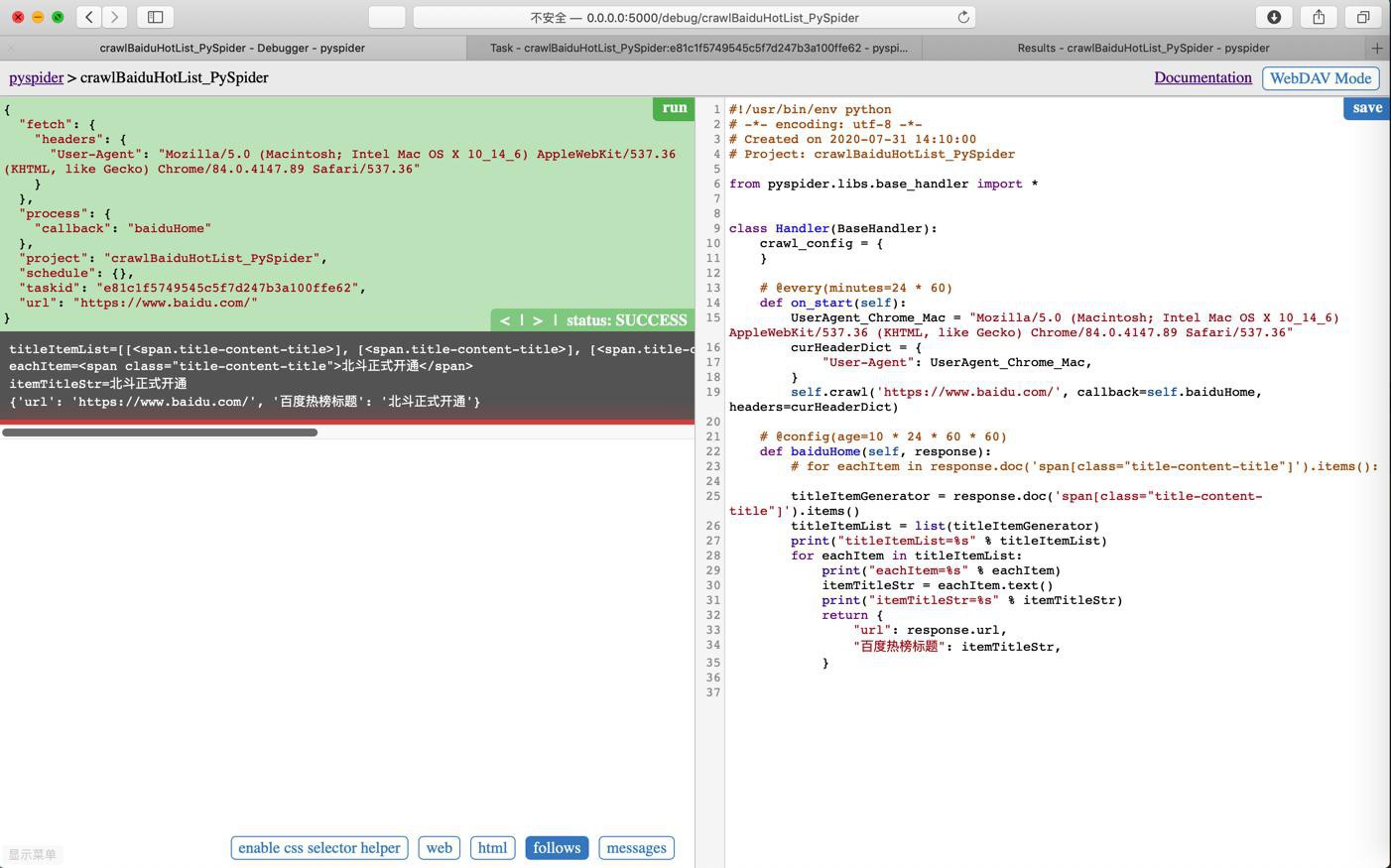
去改为list试试:
titleItemGenerator = response.doc('span[class="title-content-title"]').items()
titleItemList = list(titleItemGenerator)
print("titleItemList=%s" % titleItemList)结果:
titleItemList=[]
原来是代码有问题,返回是空啊。。。
所以继续找原因,估计是需要加header中的User-Agent?去试试
def on_start(self):
UserAgent_Chrome_Mac = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
curHeaderDict = {
"User-Agent": UserAgent_Chrome_Mac,
}
self.crawl('
https://www.baidu.com/
', callback=self.baiduHome, headers=curHeaderDict)结果:
就对了,终于返回出内容了:
【总结】
此处之所以之前代码:
response.doc('span[class="title-content-title"]').items()没有返回我们希望的百度热榜的标题列表
表面原因:
此处本身PySpider直接抓取
返回网页内容不完整
根本原因:缺少User-Agent
解决办法:去加上:
def on_start(self):
UserAgent_Chrome_Mac = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"
curHeaderDict = {
"User-Agent": UserAgent_Chrome_Mac,
}
self.crawl('https://www.baidu.com/', callback=self.baiduHome, headers=curHeaderDict)后续即可返回结果。
转载请注明:在路上 » 【已解决】PySpider抓包百度热榜标题列表结果