之前已写关于爬虫的成套教程:
爬取你要的数据:爬虫技术
现在希望去演示:
想找个简单的例子,演示如何从无到有去实现整个爬虫。
以加深理解和真正掌握写爬虫的基本逻辑和概念。
然后找到一个例子:
爬取
百度首页:
百度一下,你就知道
中的 百度热榜的内容的标题的列表:
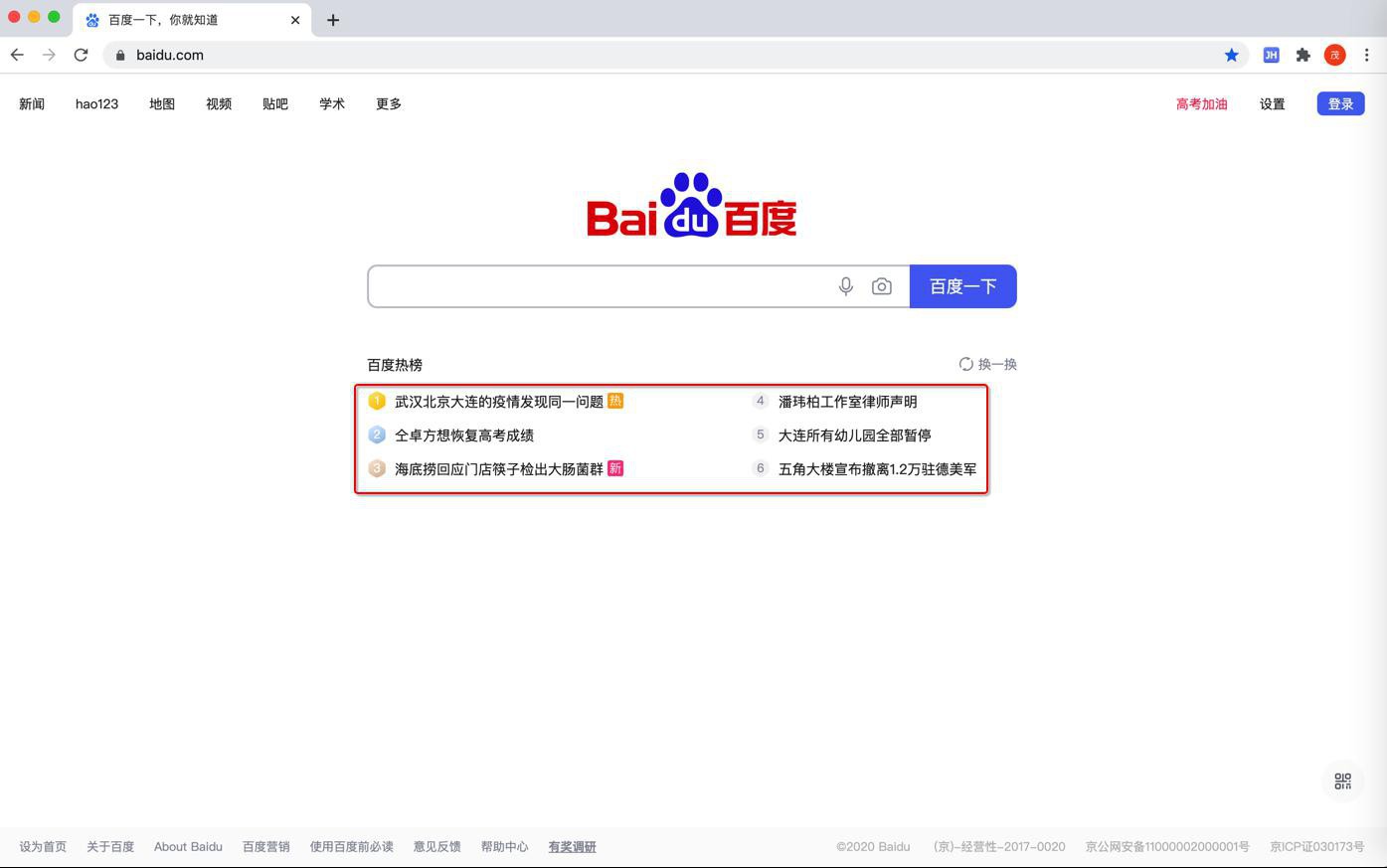
希望输出的:
一个字符串列表:
- 武汉北京大连的疫情发现同一问题
- 潘玮柏工作室律师声明
- 平安经涉事副厅长作深刻检查
- 五角大楼宣布撤离1.2万驻德美军
- 海底捞回应门店筷子检出大肠菌群
- 山西教育厅回应仝卓恢复成绩要求
保存格式,暂定为csv文件。
入手之前,先要了解清楚:
- 写爬虫的思路
- 先去(用工具)分析流程
- 此处:用Chrome中 开发者工具 去分析
- 用Chrome的开发者工具分析百度首页的内容加载的流程
- 再去用代码实现逻辑
- 此处:用Python代码实现
- 要做的事情可以分成3个步骤
- Download=下载:html网页源码
- 期间可能涉及
- 多次利用Chrome的开发者工具去调试页面内容加载逻辑
- Parse=分析:分析html中源码中我们要的内容的提取规则是什么
- 需要事先
- 分析要抓取的内容,所对应的规则
- 然后用代码实现规则,提取内容
- Save=保存:把抓取到的内容保存出来
下面就开始:
【已解决】Mac中用Chrome开发者工具分析百度首页的百度热榜内容加载逻辑
以及:
【已解决】用Python代码获取到百度首页源码并提取保存百度热榜内容列表
理论上,除了Python,用其他语言,比如Java,PHP,Go等等,也都是可以实现爬虫的效果的。
只不过由于生态,第三方库等原因,Python是目前用来爬虫开发最便捷的,最省心的语言了。
【后记 20200731】
接着再去实现:
【已解决】用Python纯内置库无第三方库实现爬虫爬取百度热榜内容列表
以及:
【已解决】用Python爬虫框架PySpider实现爬虫爬取百度热榜内容列表