折腾:
【未解决】自动化测试安卓游戏烈焰龙城:通过百度OCR返回JSON判断2个游戏界面是否一样
期间,需要去检测判断2个字符串的相似度,以便于判断字符串是否是相同字符串
去看看,为何此处2367 找不到:
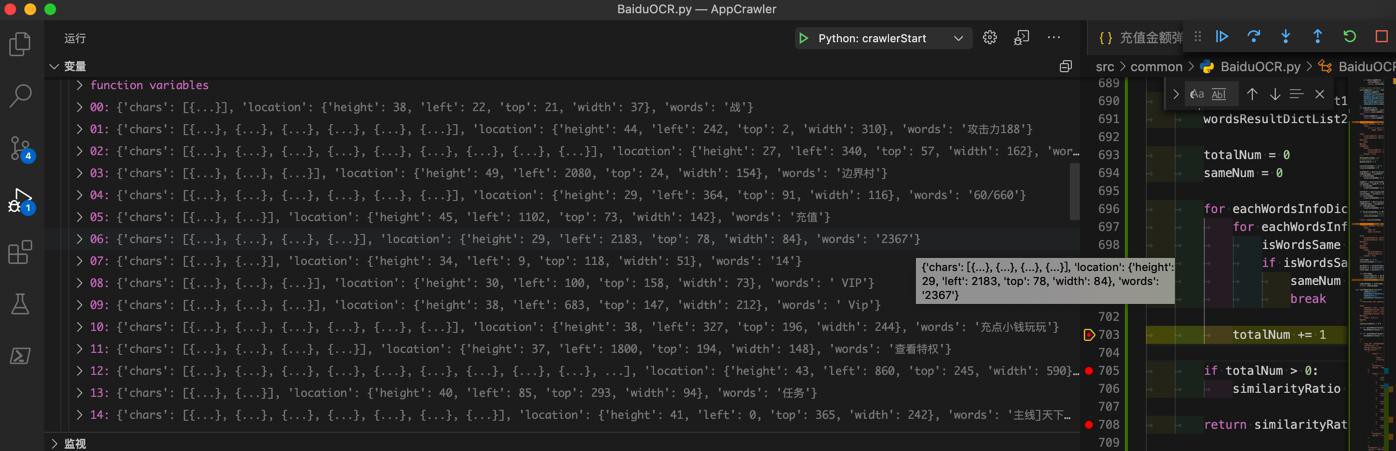
发现了,第二次识别成了(更加精确的):
23:67
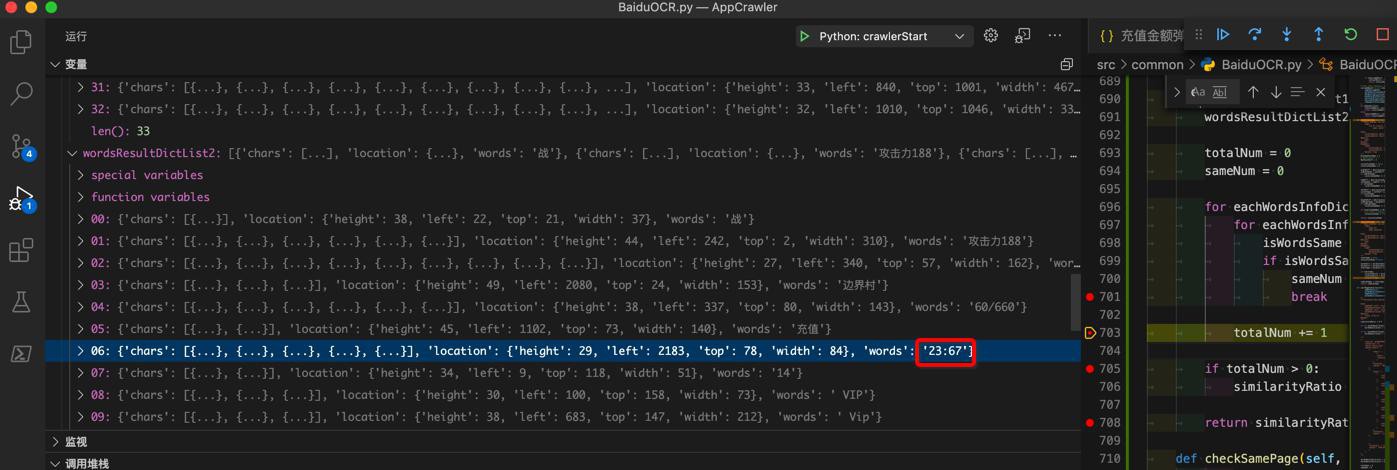
所以匹配不到,是正常的
至于,是否要去:
想办法让 2367,也去和 23:67 去比较,判断字符串是否很相似
暂时就不用这么麻烦了
以后如果需要匹配页面元素精度如此高,再去弄。
以及还有这种很类似的:
{'chars': [{...}, {...}, {...}, {...}, {...}, {...}, {...}, {...}, {...}, ...], 'location': {'height': 43, 'left': 860, 'top': 245, 'width': 590}, 'words': '只需再充1000元宝,即可升级到VIP1!’}
{'chars': [{...}, {...}, {...}, {...}, {...}, {...}, {...}, {...}, {...}, ...], 'location': {'height': 43, 'left': 860, 'top': 245, 'width': 591}, 'words': '只需再充1000元宝,即可升级到VIP1'}即:
只需再充1000元宝,即可升级到VIP1! 只需再充1000元宝,即可升级到VIP1
只差了1个感叹号
暂时也忽略精确匹配。先继续再说
其实知道OCR是有可能误判一些的
但是先看看最后结果如何,是否能够实现 判断出相同页面
如果不能,再去每个words更加精确的匹配,支持相似度高的words视为相同
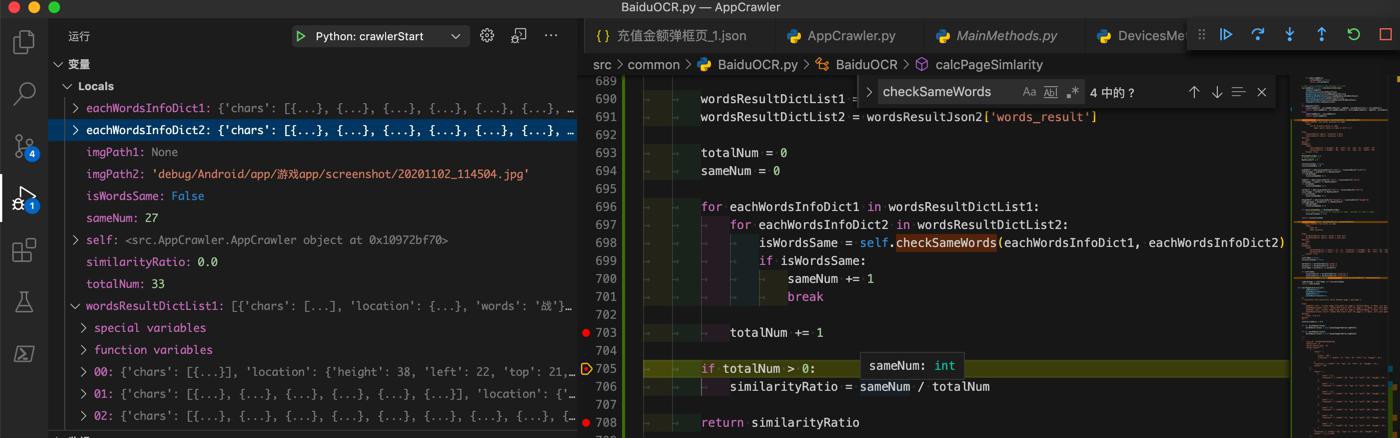
最终是27/33=0.818181818181818
此处不够理想,希望能达到90%的准确度
实际上应该超过30个是相同的,此处被误判了估计有3个以上。
所以还是去想办法支持words的相似度检测:
python string similarity
from difflib import SequenceMatcher def similar(a, b): return SequenceMatcher(None, a, b).ratio()
有内置库支持difflib
那去试试
from difflib import SequenceMatcher WordsMinSimilarRatio = 0.8 wordsStr1 = wordsInfoDict1['words'] wordsStr2 = wordsInfoDict2['words'] # isStrSame = wordsStr1 == wordsStr2 matcher = SequenceMatcher(None, wordsStr1, wordsStr2) simimarRatio = matcher.ratio() isStrSame = simimarRatio >= WordsMinSimilarRatio
去调试看看
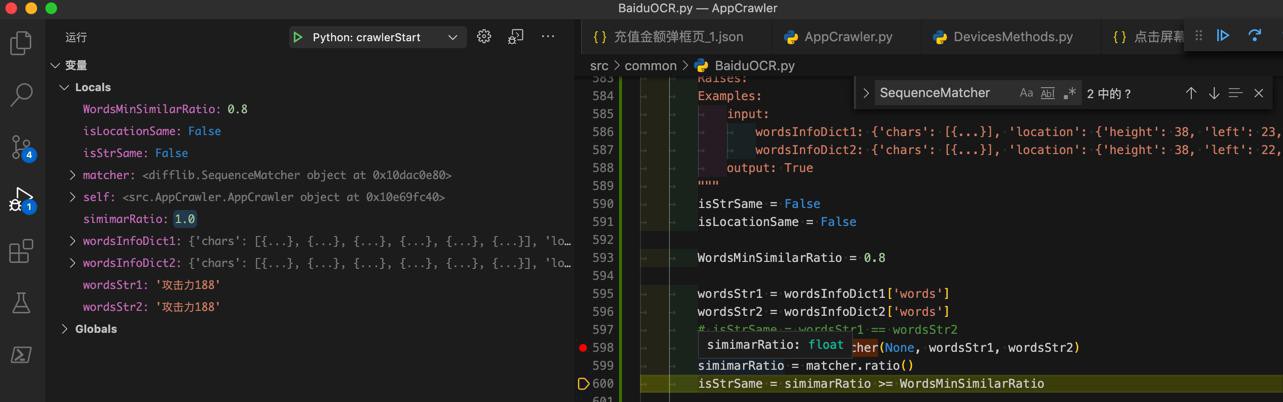
'攻击力188’ '攻击力188'
相似度:1.0
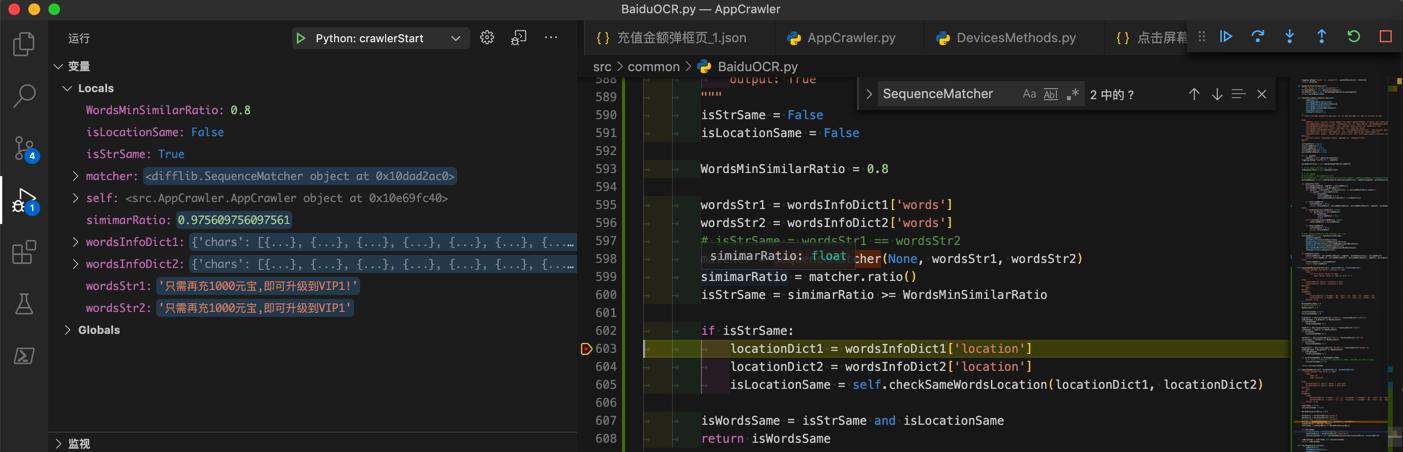
'只需再充1000元宝,即可升级到VIP1!’ '只需再充1000元宝,即可升级到VIP1'
相似度:0.975609756097561
是我们希望的
但是如果用0.8的比例,此处也有误判的
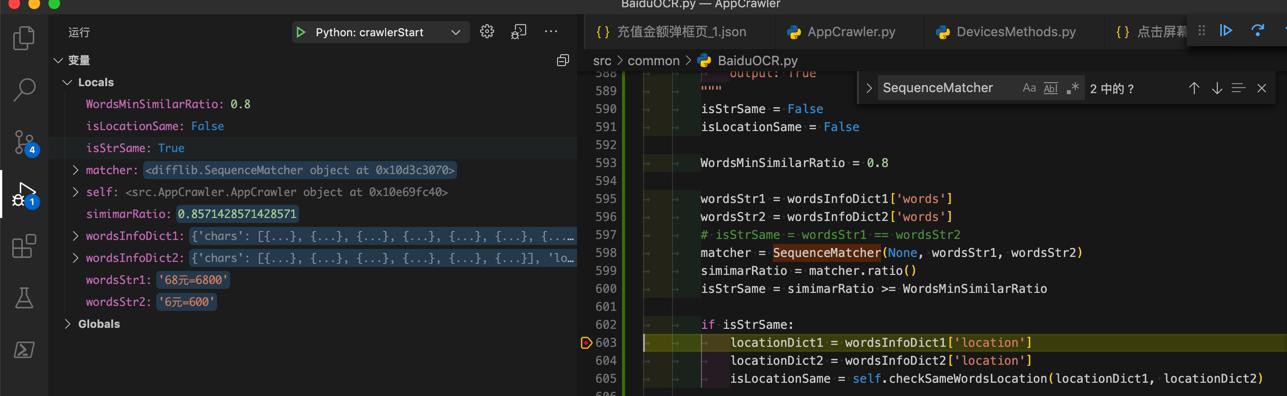
0.8571428571428571 '68元=6800’ '6元=600'
所以,感觉需要去把阈值改为0.9
另外,为了减少判断,可以加上:实现判断是否相等
isStrSame = wordsStr1 == wordsStr2 if not isStrSame: matcher = SequenceMatcher(None, wordsStr1, wordsStr2) simimarRatio = matcher.ratio() isStrSame = simimarRatio >= WordsMinSimilarRatio
继续调试
然后之前的就过滤掉了,可以正常匹配了。
另外:
0.9032258064516129 'XP:8400134506246’ 'eP:840013450624'
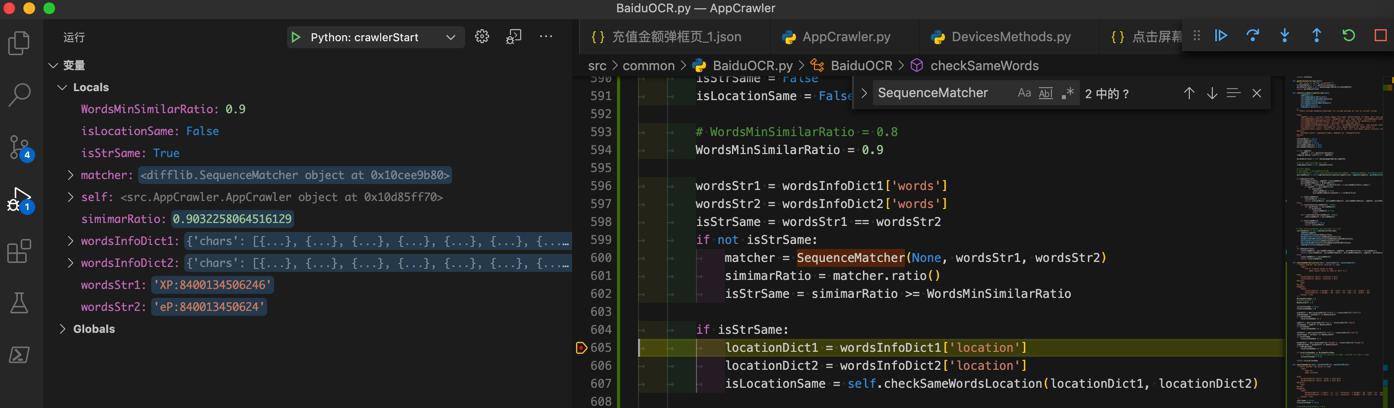
也是符合期望的。
以及后来的:
'线情况,请在设直中勾选屏BOSS特效!’ '线情况,请在设直中勾选屏敞BOSS特效!’ 0.9743589743589743
也是符合预期的:
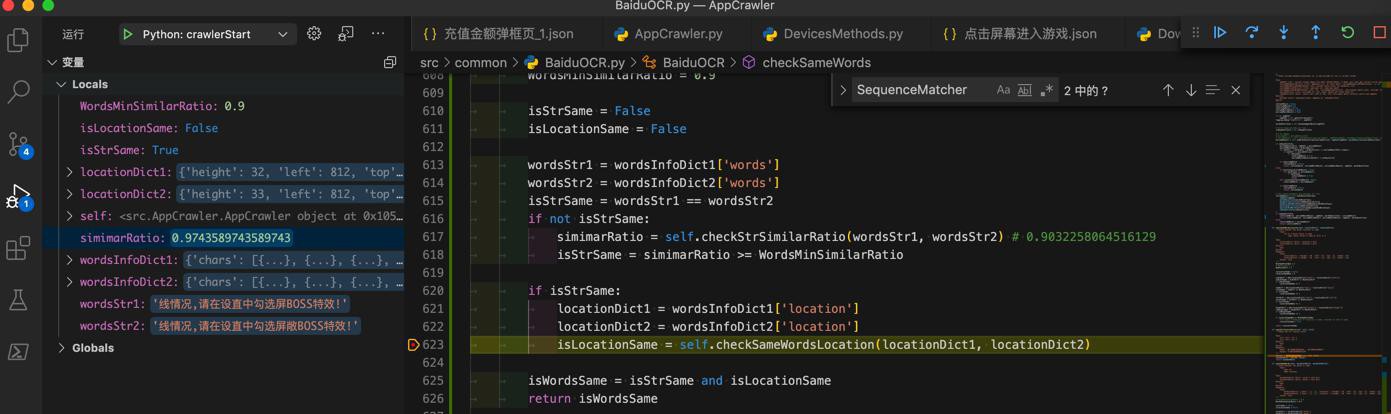
不过继续优化:
isStrSame = wordsStr1 == wordsStr2 if not isStrSame: simimarRatio = self.checkStrSimilarRatio(wordsStr1, wordsStr2) isStrSame = simimarRatio >= WordsMinSimilarRatio
和:
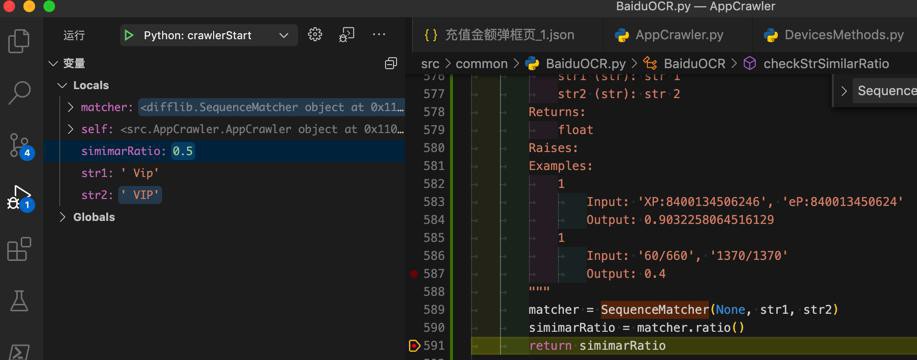
def checkStrSimilarRatio(self, str1, str2): """Check two str similar ratio Args: str1 (str): str 1 str2 (str): str 2 Returns: float Raises: Examples: Input: 'XP:8400134506246', 'eP:840013450624' Output: 0.9032258064516129 """ matcher = SequenceMatcher(None, str1, str2) simimarRatio = matcher.ratio() return simimarRatio
期间还发现一个,很好的事情:
对于界面中的:
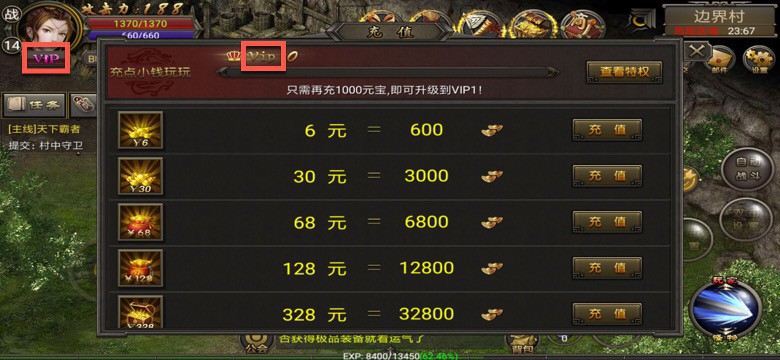
- VIP
- Vip
可以判断出:
' Vip’ ' VIP’ 0.5
是有相似的,相似度是0.5,结果很合理。
【总结】
Python中判断2个字符串相似度,可以用代码:
def checkStrSimilarRatio(self, str1, str2): """Check two str similar ratio Args: str1 (str): str 1 str2 (str): str 2 Returns: float Raises: Examples: 1 Input: 'XP:8400134506246', 'eP:840013450624' Output: 0.9032258064516129 1 Input: '60/660', '1370/1370' Output: 0.4 """ matcher = SequenceMatcher(None, str1, str2) simimarRatio = matcher.ratio() return simimarRatio
调用:
wordsStr1 = 'XP:8400134506246' wordsStr2 = 'eP:840013450624' simimarRatio = checkStrSimilarRatio(wordsStr1, wordsStr2) # 0.9032258064516129
即可。
转载请注明:在路上 » 【已解决】Python中检测判断2个字符串的相似度