折腾:
【未解决】用Python把印象笔记中的文章内容部分转换成html用于后续上传到WordPress
期间,需要把
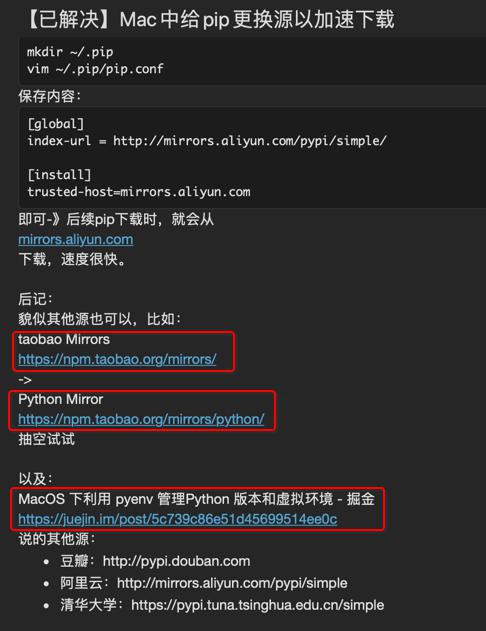
中对应的html
<div> taobao Mirrors </div> <div> <a href="https://npm.taobao.org/mirrors/"> https://npm.taobao.org/mirrors/ </a> </div> <div> Python Mirror </div> <div> <a href="https://npm.taobao.org/mirrors/python/"> https://npm.taobao.org/mirrors/python/ </a> </div>
中的标题和链接合并再一起:
把文字加上链接
以及,不要误判,不要把
<div> 即可-》后续pip下载时,就会从 </div> <div> <a href="http://mirrors.aliyun.com/"> mirrors.aliyun.com </a> </div>
目前看起来,可以采用的判断逻辑是:
title标题中,要包含空格,才合并
否则不合并
以及要合并的规则是:
title+url
中的url中是:
div -> a,以及a中的string和href值相同
所以就要去找:
div下面,有且只有一个a的,且a的href和string相同
然后再去找div前面存在一个div:
且该div下面只有string,没有其他子节点
以及string中要包含空格
然后才去合并
对于合并后的规则,去研究看看:
另外还有一个,本来是:
<div> MacOS 下利用 pyenv 管理Python 版本和虚拟环境 - 掘金 </div> <div> <a href="https://juejin.im/post/5c739c86e51d45699514ee0c"> https://juejin.im/post/5c739c86e51d45699514ee0c </a> </div>
然后故意合并在一起:
调试看看,html是啥
先要去搜a,且带href的
但是不清楚:如何写 有href,但是不为空
当前href值可以用正则,但是觉得没必要
记得有默认表达的
不过待会可以参考:
from bs4 importNavigableString def surrounded_by_strings(tag): return(isinstance(tag.next_element,NavigableString) and isinstance(tag.previous_element,NavigableString)) fortag insoup.find_all(surrounded_by_strings): printtag.name # p # a # a # a # p
去实现:一次性搜索出来要的值
即:
把各个条件写成判断函数,直接找
a,带href,然后parent必须是div的,且a没有兄弟节点的
参考:
soup.find_all(id=True)
好像可以写成:
aNodeList = soup.find_all("a", attrs={"href": True})去试试
是可以的。
另外对于
<div><a href="http://mirrors.aliyun.com/">mirrors.aliyun.com</a></div>
想要去判断a节点是没有child的
结果用
childrenGenerator = eachANode.children childList = list(childrenGenerator) if childList:
却发现childList是有值的
['mirrors.aliyun.com']
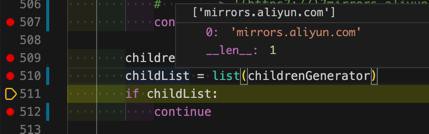
再去找,如何获取到 子节点,判断子节点为空的逻辑
好像也只能就这么判断
不过应该换用descendants
descendantGenerator = eachANode.descendants descendantList = list(descendantsGenerator) if descendantList:
此处也是
['mirrors.aliyun.com']
所以只能去判断
有且只有一个child
且直接是str值就是前面的aStr
然后就是复杂的逻辑判断
其中再去看:
【已解决】BeautifulSoup中如何删除某个节点
【总结】
最后此处用代码:
def mergePostTitleAndUrl(soup):
"""Merge post title and url
Args:
soup (BeautifulSoup soup): soup of evernote post
Returns:
processed soup
Raises:
"""
"""
<div>
Python Mirror
</div>
<div>
<a href="https://npm.taobao.org/mirrors/python/">
https://npm.taobao.org/mirrors/python/
</a>
</div>
"""
aNodeList = soup.find_all("a", attrs={"href": True})
aNodeListLen = len(aNodeList)
for eachANode in aNodeList:
# prevSiblingList = eachANode.find_previous_siblings()
# nextSiblingList = eachANode.find_next_siblings()
prevSiblingGenerator = eachANode.previous_siblings
prevSiblingList = list(prevSiblingGenerator)
nextSiblingGenerator = eachANode.next_siblings
nextSiblingList = list(nextSiblingGenerator)
if prevSiblingList or nextSiblingList:
continue
aStr = eachANode.string
if not aStr:
continue
aStr = aStr.strip()
if not aStr:
continue
hrefValue = eachANode["href"]
if not hrefValue:
continue
# <div><a href="https://npm.taobao.org/mirrors/">https://npm.taobao.org/mirrors/</a></div>
# <div><a href="https://npm.taobao.org/mirrors/python/">https://npm.taobao.org/mirrors/python/</a></div>
# if hrefValue != aStr:
hrefP = "(https?://)?%s/?" % aStr
isSameUrl = re.match(hrefP, hrefValue, re.I)
isNotSameUrl = not isSameUrl
if isNotSameUrl:
# (1) <div><a href="https://juejin.im/post/5c739c86e51d45699514ee0c">MacOS 下利用 pyenv 管理Python 版本和虚拟环境 - 掘金</a></div>
# (2) <div><a href="http://mirrors.aliyun.com/">mirrors.aliyun.com</a></div>
# -> '(https?://)?mirrors.aliyun.com/?' == 'http://mirrors.aliyun.com/'
continue
isCurNoChild = isNoMoreChildren(eachANode)
isCurHasChild = not isCurNoChild
if isCurHasChild:
continue
# only one parent: div
# parentDivNode = eachANode.find_parent("div")
parentDivNode = eachANode.parent
if not parentDivNode:
continue
# parent prev is div
# parentPrevSibling = parentDivNode.find_previous_sibling()
parentPrevSibling = parentDivNode.previous_sibling
isParentPrevSiblingNotExist = not parentPrevSibling
if isParentPrevSiblingNotExist:
continue
isParentPrevSiblingNameNotDiv = parentPrevSibling.name != "div"
if isParentPrevSiblingNameNotDiv:
continue
parentPrevSiblingStr = parentPrevSibling.string
isParentPrevSiblingStrEmpty = not parentPrevSiblingStr
if isParentPrevSiblingStrEmpty:
continue
isParentPrevSiblingNoChild = isNoMoreChildren(parentPrevSibling)
isParentPrevSiblingHasChild = not isParentPrevSiblingNoChild
if isParentPrevSiblingHasChild:
continue
# other possible logic check
# (1) title best contain some char: ' ' or '|' or '-'
foundSpecialCharInTitle = re.search("[ \|\—]", parentPrevSiblingStr)
isTitleNoSpecialChar = not foundSpecialCharInTitle
if isTitleNoSpecialChar:
continue
# match all condition -> merge title and url
# delete div
parentPrevSibling.decompose()
# replace new a node
eachANode.string = parentPrevSiblingStr
return soup处理后,即可实现普通的把title和url合并,处理后的html打开页面看效果:
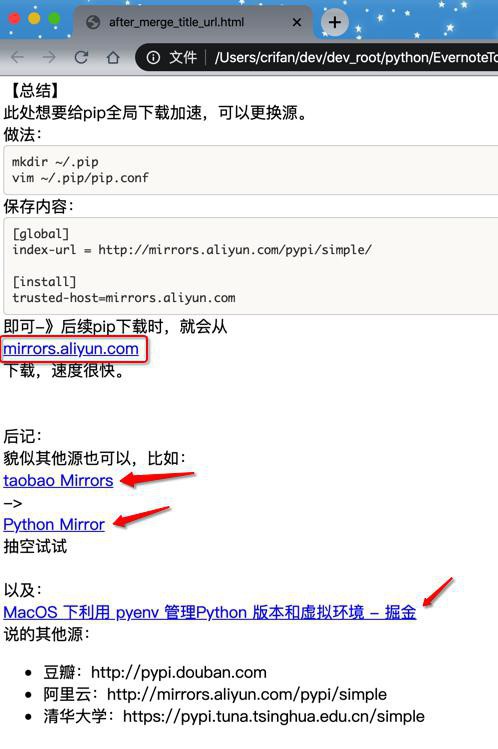
是我们希望看到的:
上面链接前面title中没有空格等特殊字符,所以不合并。
后面3个符合条件,则合并。
另外
处理之前就已经是合并好的,此处也不符合,isNotSameUrl
所以不动。
【后记 20201125】
折腾:
【未解决】用Python发布印象笔记帖子内容到WordPress网站
期间,又多次遇到,代码需要更新
def mergeNoteTitleAndUrl(noteDetail):
"""Merge title and url in note content
Args:
noteDetail (Note): evernote note with detail
Returns:
updated Note
Raises:
"""
curContent = noteDetail.content
logging.debug("curContent=%s", curContent)
soup = BeautifulSoup(curContent, 'html.parser')
aNodeList = soup.find_all("a", attrs={"href": True})
for eachANode in aNodeList:
# prevSiblingList = eachANode.find_previous_siblings()
# nextSiblingList = eachANode.find_next_siblings()
prevSiblingGenerator = eachANode.previous_siblings
prevSiblingList = list(prevSiblingGenerator)
nextSiblingGenerator = eachANode.next_siblings
nextSiblingList = list(nextSiblingGenerator)
if prevSiblingList or nextSiblingList:
# <a> node is link title, and prev (or next) should be the link title
# so if NO prev (or next), means NO exist title and link to merge
continue
aStr = eachANode.string
if not aStr:
continue
aStr = aStr.strip()
# '怎么关闭QQ浏览器的手势快捷键-百度经验'
if not aStr:
continue
hrefValue = eachANode["href"]
# 'https://jingyan.baidu.com/article/7f766daf6eeea40000e1d026.html'
if not hrefValue:
continue
"""
<div>
Python Mirror
</div>
<div>
<a href="https://npm.taobao.org/mirrors/python/">
https://npm.taobao.org/mirrors/python/
</a>
</div>
"""
# <div><a href="https://npm.taobao.org/mirrors/">https://npm.taobao.org/mirrors/</a></div>
# <div><a href="https://npm.taobao.org/mirrors/python/">https://npm.taobao.org/mirrors/python/</a></div>
# if hrefValue != aStr:
hrefP = "(https?://)?%s/?" % aStr
isSameUrl = re.match(hrefP, hrefValue, re.I)
isNotSameUrl = not isSameUrl
if isNotSameUrl:
# (1) has add link into title:
# <a href="https://jingyan.baidu.com/article/7f766daf6eeea40000e1d026.html">怎么关闭QQ浏览器的手势快捷键-百度经验</a>
# <div><a href="https://juejin.im/post/5c739c86e51d45699514ee0c">MacOS 下利用 pyenv 管理Python 版本和虚拟环境 - 掘金</a></div>
# (2) <div><a href="http://mirrors.aliyun.com/">mirrors.aliyun.com</a></div>
# -> '(https?://)?mirrors.aliyun.com/?' == 'http://mirrors.aliyun.com/'
continue
isCurNoChild = isNoMoreChildren(eachANode)
isCurHasChild = not isCurNoChild
if isCurHasChild:
continue
# only one parent: div
# parentDivNode = eachANode.find_parent("div")
parentDivNode = eachANode.parent
if not parentDivNode:
continue
# parent prev is div
# parentPrevSibling = parentDivNode.find_previous_sibling()
parentPrevSibling = parentDivNode.previous_sibling
isParentPrevSiblingNotExist = not parentPrevSibling
if isParentPrevSiblingNotExist:
continue
isParentPrevSiblingNameNotDiv = parentPrevSibling.name != "div"
if isParentPrevSiblingNameNotDiv:
continue
parentPrevSiblingStr = parentPrevSibling.string
isParentPrevSiblingStrEmpty = not parentPrevSiblingStr
if isParentPrevSiblingStrEmpty:
continue
isParentPrevSiblingNoChild = isNoMoreChildren(parentPrevSibling)
isParentPrevSiblingHasChild = not isParentPrevSiblingNoChild
if isParentPrevSiblingHasChild:
continue
# other possible logic check
# (1) title best contain some char: ' ' or '|' or '-'
foundSpecialCharInTitle = re.search("[ \|\—]", parentPrevSiblingStr)
isTitleNoSpecialChar = not foundSpecialCharInTitle
if isTitleNoSpecialChar:
continue
# match all condition -> merge title and url
# delete div
parentPrevSibling.decompose()
# replace new a node
eachANode.string = parentPrevSiblingStr
updatedContent = soup.prettify()
# updatedContent = str(soup)
logging.info("updatedContent=%s", updatedContent)
noteDetail.content = updatedContent
return noteDetail结果报错:
【已解决】Python中用正则re.match报错:发生异常 error multiple repeat at position
转载请注明:在路上 » 【已解决】用Python把印象笔记中标题和链接合并一起