折腾:
【未解决】用Python纯内置库无第三方库实现爬虫爬取百度热榜内容列表
期间,先去用python 3的内置库urllib去下载网页源码
python3 urllib
- urllib 是一个收集了多个涉及 URL 的模块的包:
- * urllib.request 打开和读取 URL
- * urllib.error 包含 urllib.request 抛出的异常
- * urllib.parse 用于解析 URL
- * urllib.robotparser 用于解析 robots.txt 文件
去写代码:
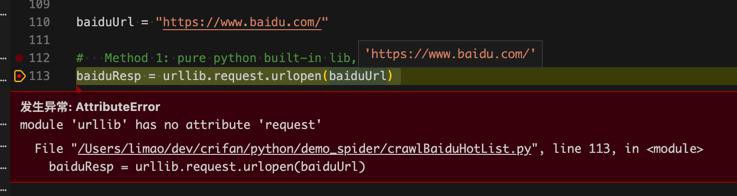
import urllib baiduResp = urllib.request.urlopen(baiduUrl)
竟然报错:
发生异常: AttributeError module 'urllib' has no attribute 'request'
感觉是,要换个方式去导入
import urllib.request baiduResp = urllib.request.urlopen(baiduUrl)
就可以了:
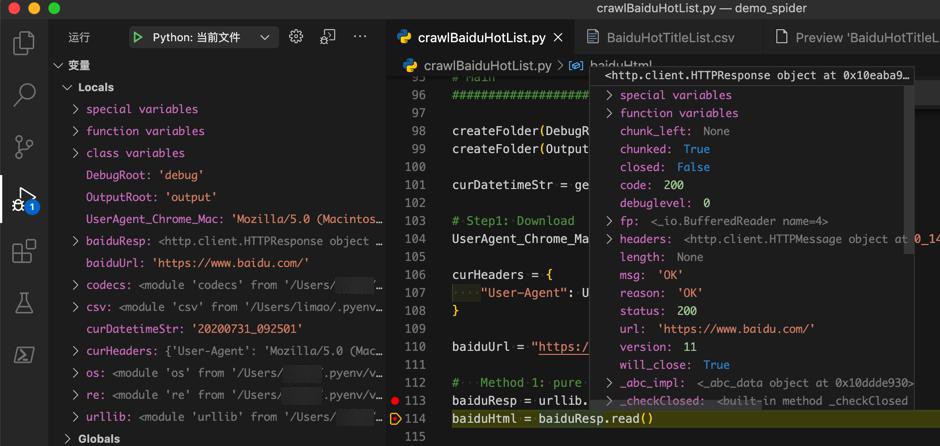
继续调试
去read:
baiduHtml = baiduResp.read()
调试保存出来是:
结果发现read出来的是bytes:
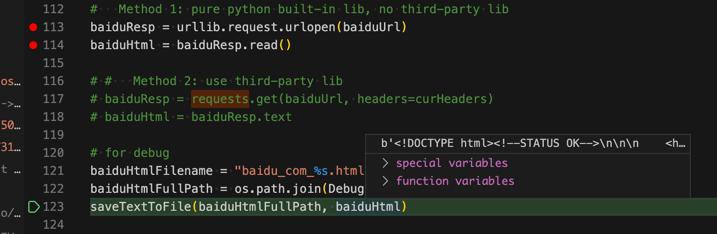
要去解码:
baiduHtmlBytes = baiduResp.read() baiduHtml = baiduHtmlBytes.decode()
结果:

可以变成string
然后本来以为会和之前requests一样,没有返回完整源码呢。
结果发现不是的,已经返回完整html源码了:
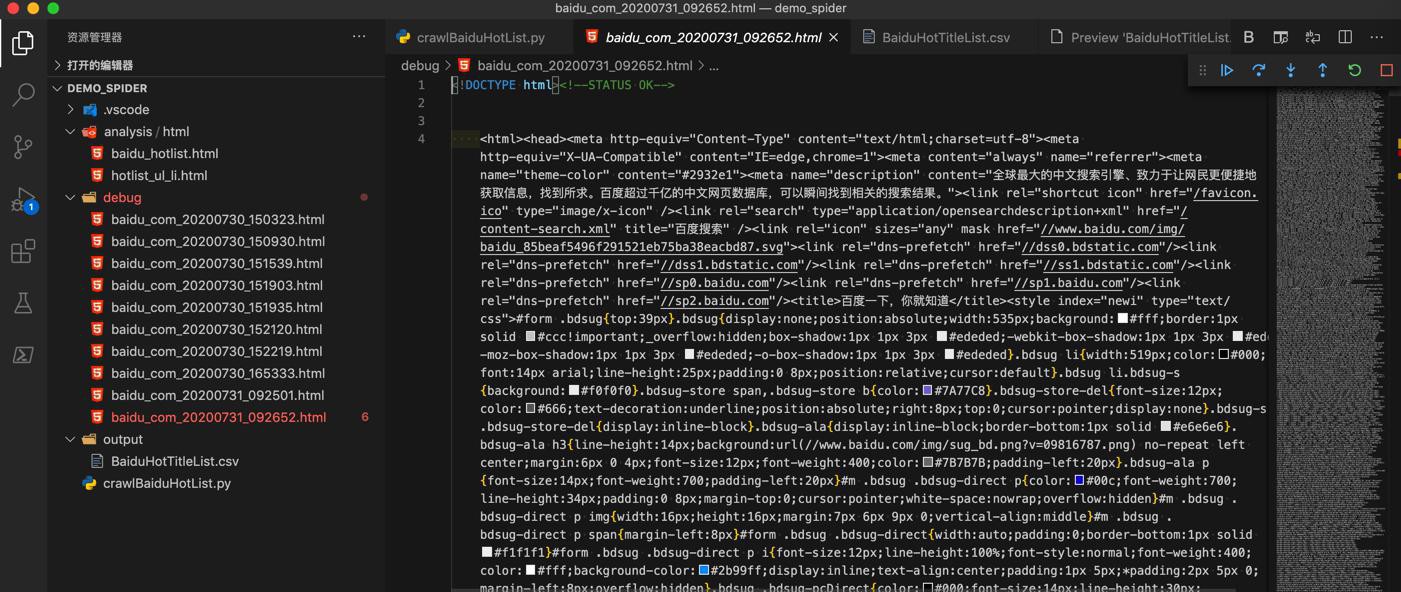
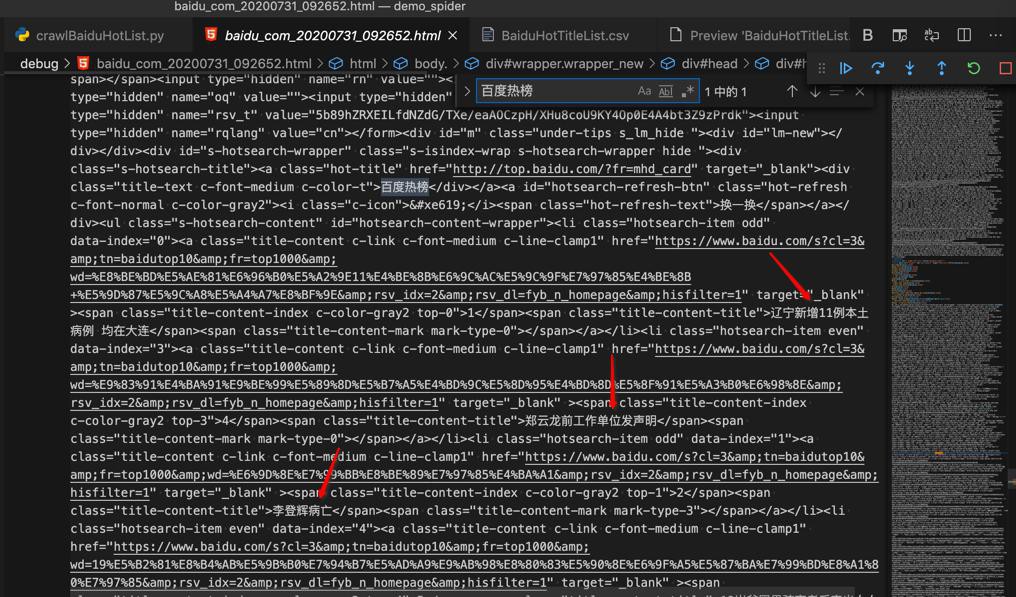
去搜索:百度热榜
也就可以看到最新热榜内容标题了
【总结】
此处用Python内置库urllib去下载百度首页html源码
baiduUrl = "https://www.baidu.com/" baiduHtmlBytes = baiduResp.read() baiduHtml = baiduHtmlBytes.decode()
即可。
注:
之前requests,是需要加User-Agent的,才能返回完整网页源码,而此处urllib无需加。
转载请注明:在路上 » 【已解决】用Python3的urllib下载百度首页源码